一种问题匹配方法和系统与流程
本发明涉及金融科技领域,具体涉及一种问题匹配方法和系统。
背景技术:
1、随着信息化时代的发展,人们习惯于借助于网络解决各种生活中遇到的问题,比如金融知识问答平台,用户可在网上咨询各种金融知识,相关领域从业者会回答用户的问题,类似网络问答社区等,这些问答社区为用户提供了极大的便利。随着在线提问的用户数量的增加,各种各样的新问题被不断提出,但是能够解答问题的专家却相对数量较少,解答问题的速度也难以提高,这给网络问答社区的用户体验造成了较大的不良影响。面对迅速增长的咨询用户所提出的海量问题,如何为用户快速找到答案并答复是一个亟待解决的问题。
2、对于传统的金融网络问答社区所面临的困境,自动问答系统是一种有效的解决方案。问答系统的核心步骤,在于将用户提出的问题q,与数据库中的问题列表进行匹配,即在数据库中寻找与用户问题最接近的问题qi,进而返回数据库中该问题的答案ai,输出至用户。现有技术中问题匹配的常用做法为:首先构建深度神经网络模型,使用开源大规模的、多领域的,即通用的语料库,对模型预训练;进一步,收集相对少量的、目标领域内的,即非通用的语料数据,对上述深度神经网络模型再次进行微调。微调完成后,该模型可用于计算两个问题的相似程度,进而实现问题匹配。
3、上述模型构建过程通常较为复杂,预训练阶段需要大量的通用数据,需要耗费大量的时间与计算量;但当目标场景相对简单时,往往也不需要过于复杂的模型,甚至人工规则构成的专家系统,同样可以解决问题;当目标场景相对单一时,可收集到目标领域语料数据通常较少,难以驱动大型神经网络模型进行微调,或者微调效果不佳。
技术实现思路
1、基于此,本技术实施例提供一种问题匹配方法和系统,涉及金融科技领域,通过对目标问题和问答数据库中的模拟问题的相似度分值的计算,更高效的完成问题匹配。
2、为了实现上述目的,本技术实施例提供如下技术方案:
3、根据本技术实施例的第一方面,提供了一种问题匹配方法,所述方法包括:
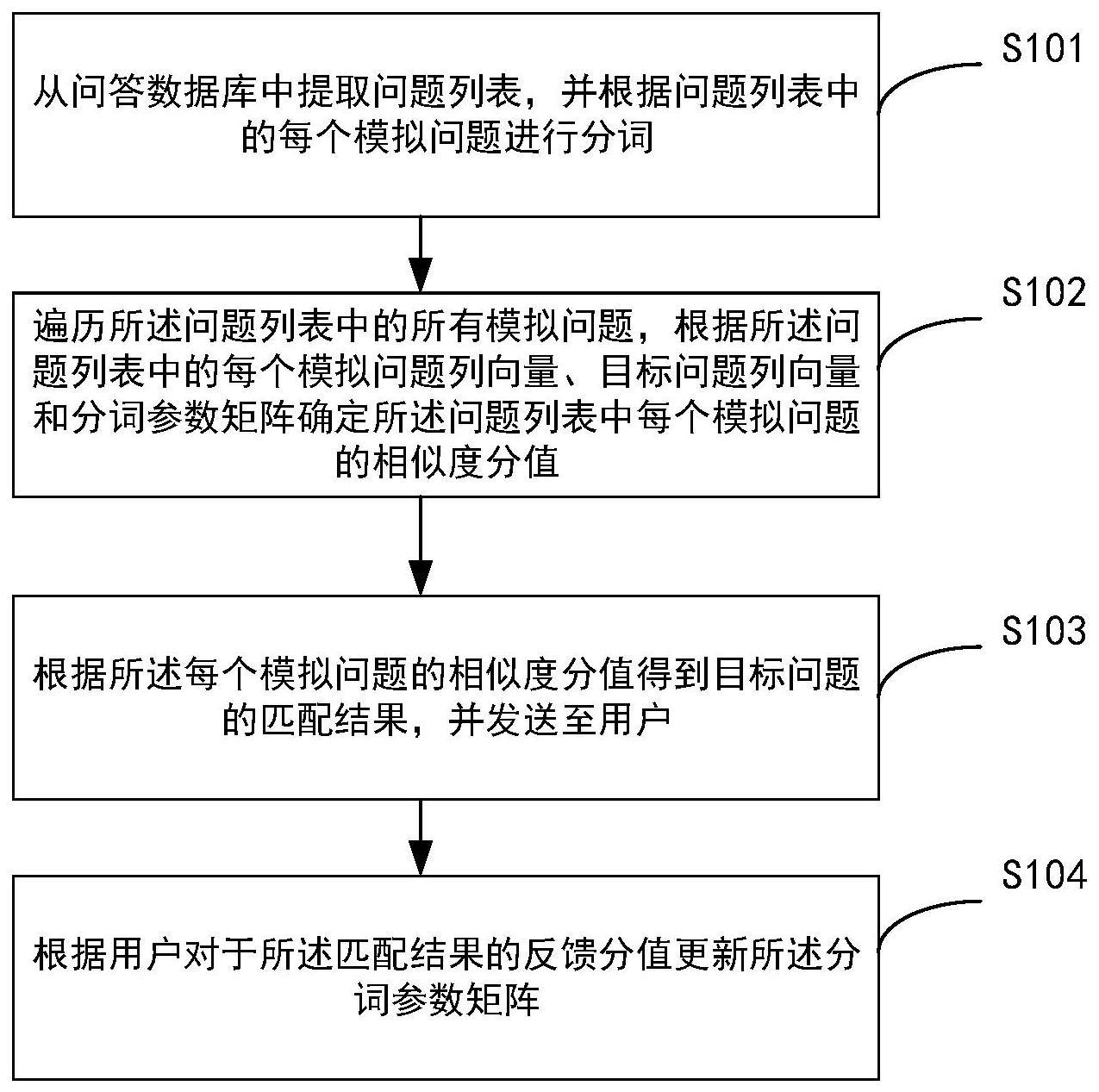
4、从问答数据库中提取问题列表,并根据问题列表中的每个模拟问题进行分词;
5、遍历所述问题列表中的所有模拟问题,根据所述问题列表中的每个模拟问题列向量、目标问题列向量和分词参数矩阵确定所述问题列表中每个模拟问题的相似度分值;
6、根据所述每个模拟问题的相似度分值得到目标问题的匹配结果,并发送至用户;
7、根据用户对于所述匹配结果的反馈分值更新所述分词参数矩阵。
8、可选地,根据所述每个模拟问题的相似度分值得到目标问题的匹配结果,包括:
9、将所述问题列表中所有模拟问题的相似度分值最大的模拟问题确定为候选模拟问题;
10、在所述问答数据库中查询所述候选模拟问题的答案,确定为目标问题的匹配结果。
11、可选地,所述遍历所述问题列表中的所有模拟问题之前,所述方法还包括:
12、根据问题列表中所有模拟问题进行分词后得到的分词计算每个分词的频率;
13、根据每个分词的频率构建所述分词参数矩阵;
14、基于所述问题列表中的模拟问题中是否出现分词将所述问题列表中的每个模拟问题转换为模拟问题列向量的形式,以及将目标问题转换为目标问题列向量的形式。
15、可选地,所述根据所述问题列表中的每个模拟问题列向量、目标问题列向量和分词参数矩阵确定所述问题列表中每个模拟问题的相似度分值,按照如下公式:
16、f(qt,qi)=sigmoid(ytwxi)
17、其中,分词参数矩阵w∈rk×k为k行k列的实数矩阵,sigmoid(·)为sigmoid激活函数,qi为问题列表中的模拟问题i,xi为模拟问题i的列向量,qt为目标问题,y为目标问题的列向量。
18、可选地,所述根据用户对于所述匹配结果的反馈分值更新所述分词参数矩阵,包括:
19、使用梯度下降方法,对所述分词参数矩阵进行迭代更新,当设定迭代时间内,交叉熵损失函数持续低于设定阈值时,迭代收敛,得到更新后的分词参数矩阵。
20、可选地,按照如下公式对分词参数矩阵w进行迭代更新:
21、
22、l=-∑y·logf(qt,qi*)
23、其中,学习率α>0,l为交叉熵损失函数,qt为目标问题,qi*为目标问题的匹配结果,y为用户对于目标问题的匹配结果的反馈分值,f(qt,qi*)为目标问题与匹配结果的相似度分值。
24、根据本技术实施例的第二方面,提供了一种问题匹配系统,所述系统包括:
25、分词模块,用于从问答数据库中提取问题列表,并根据问题列表中的每个模拟问题进行分词;
26、相似度分值计算模块,用于遍历所述问题列表中的所有模拟问题,根据所述问题列表中的每个模拟问题列向量、目标问题列向量和分词参数矩阵确定所述问题列表中每个模拟问题的相似度分值;
27、问题匹配模块,用于根据所述每个模拟问题的相似度分值得到目标问题的匹配结果,并发送至用户;
28、优化模块,用于根据用户对于所述匹配结果的反馈分值更新所述分词参数矩阵。
29、可选地,所述问题匹配模块,具体用于:
30、将所述问题列表中所有模拟问题的相似度分值最大的模拟问题确定为候选模拟问题;
31、在所述问答数据库中查询所述候选模拟问题的答案,确定为目标问题的匹配结果。
32、可选地,所述分词模块,还用于:
33、根据问题列表中所有模拟问题进行分词后得到的分词计算每个分词的频率;
34、根据每个分词的频率构建所述分词参数矩阵;
35、基于所述问题列表中的模拟问题中是否出现分词将所述问题列表中的每个模拟问题转换为模拟问题列向量的形式,以及将目标问题转换为目标问题列向量的形式。
36、可选地,所述相似度分值计算模块,按照如下公式:
37、f(qt,qi)=sigmoid(ytwxi)
38、其中,分词参数矩阵w∈rk×k为k行k列的实数矩阵,sigmoid(·)为sigmoid激活函数,qi为问题列表中的模拟问题i,xi为模拟问题i的列向量,qt为目标问题,y为目标问题的列向量。
39、可选地,所述优化模块,具体用于:
40、使用梯度下降方法,对所述分词参数矩阵进行迭代更新,当设定迭代时间内,交叉熵损失函数持续低于设定阈值时,迭代收敛,得到更新后的分词参数矩阵。
41、可选地,按照如下公式对分词参数矩阵w进行迭代更新:
42、
43、l=-∑y·log f(qt,qi*)
44、其中,学习率α>0,l为交叉熵损失函数,qt为目标问题,qi*为目标问题的匹配结果,y为用户对于目标问题的匹配结果的反馈分值,f(qt,qi*)为目标问题与匹配结果的相似度分值。
45、根据本技术实施例的第三方面,提供了一种电子设备,包括:存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器运行所述计算机程序时执行以实现上述第一方面所述的方法。
46、根据本技术实施例的第四方面,提供了一种计算机可读存储介质,其上存储有计算机可读指令,所述计算机可读指令可被处理器执行以实现上述第一方面所述的方法。
47、综上所述,本技术实施例提供了一种问题匹配方法和系统,通过从问答数据库中提取问题列表,并根据问题列表中的每个模拟问题进行分词;遍历所述问题列表中的所有模拟问题,根据所述问题列表中的每个模拟问题列向量、目标问题列向量和分词参数矩阵确定所述问题列表中每个模拟问题的相似度分值;根据所述每个模拟问题的相似度分值得到目标问题的匹配结果,并发送至用户;根据用户对于所述匹配结果的反馈分值更新所述分词参数矩阵。通过对目标问题和问答数据库中的模拟问题的相似度分值的计算,更高效的完成问题匹配。
- 还没有人留言评论。精彩留言会获得点赞!