一种基于流式处理的数仓建设方法和系统与流程
本发明涉及数据仓库建设的,尤其是一种基于流式处理的数仓建设方法和系统。
背景技术:
1、在计算机领域,数据仓库是用于数据分析与报告的系统,是商业智能的重要组成。数据仓库来自一个或多个不同源的集成数据中央存储库,可以是异构的存储库。数据仓库一般将当前最新或历史数据存储在一起,用于商业价值的创造。数据仓库代表对数据的管理和使用的方式,是典型的提取、转换、加载、建模使用分级,数据集成和访问层等完整的体系。数据仓库是面向主题的、集成的、变化的、但相对稳定的数据集合,用于管理决策过程的支持。
2、进入互联网时代由于上网用户剧增,特别是从pc时代进入移动互联时代,海量的用户行为数据的产生,从每天的pb级到eb级,甚至zb级,企业迫切希望从这些海量数据中挖掘有效的商业信息,如业务数据、用户行为数据、异常数据等等数据中提炼出有价值的信息,用户商业决策。伴随着数据规模的不断增大,业务数据量激增,数据仓库的建设方法与架构也不断的迭代,从原来传统数仓,发展到离线数仓,再到现在的离线加实时的lambda。
3、传统的数仓对源头数据中的结构化、半结构化与非结构化数据通过离线etl定期加载到数仓,之后通过计算引擎取得结果,再提供前端或服务使用。离线数仓+计算引擎,通常运用于大型oltp数据库(以传统关系型数据库为主,如oracle、sql server为代表)。传统的数据仓库对于事务型业务处理能非常完善地支撑,但面对海量的数据存储与计算显得无法适应,主要有以下3点:
4、1.传统的数据仓库属于预建设模型的,对于海量数据或用户需要的不断变化都需要不断的重构,效率非常低。
5、2.由于大数据的海量数据属于由量变到质变的,传统数据仓库无法属于适应海量数据的快速分析响应的需要。
6、3.传统数据仓库的集群扩展成本非常大,且很难做好横向扩展提高计算能力。
7、随着数据规模的不断增大,业务的数据量激增,传统数据仓库难以承载海量数据,传统的数据库存储技术也面临存储紧张,成本不断提高。与此同时随着大数据技术的普及,通过大数据技术来构建离线数据仓库可能,采用大数据技术来承载存储与计算离线数仓。大数据中的数据仓库构建就是基于传统数仓建设架构而来,使用了大数据的技术工具来替代传统的oltp,演变成离线大数据数仓建议架构,离线数据仓库建设方法很好地解决了传统数仓的不足。随着业务数据处理能力与需求的不断变化,实践中发现,离线批量处理的模式能力虽有很大的提升,但无论如何也无法满足数据处理与业务时效性要求非常高的业务场景。“离线+流式计算”双链路的数仓建设方法是一种折中的过渡性方案,但在实践生产中有诸多不足:
8、1.计算资源的使用增加。由于同时存在离线与流式计算两条线路,离线与流式数据计算资源占用时间段可能会不一致,离线计算更多是凌晨12点至早上6点前,而流式更多的是白天时间或凌晨12点前,这样离线与流式的计算资源没办法充分利用,导致整体的资源占用会增多。
9、2.同时维护两套代码。离线与流式计算的两条线路,一个需要实现离线引擎上代码,一个则需要实现流式引擎上的代码,并且需要实现两套测试过程。对数仓业务的运维成本翻倍。
10、3.离线计算时效性差。由于业务的不断变化,越来越多的业务需要将原来有的离线任务时效性要求越来越高,由于离线计算只能满足t+n的计算要求,只能将n的时间级别转到分钟级,这样对服务器资源的要求越来越高,而且时效性不一致能保证。
11、4.集群存储要求高。由于离线与流式两个链路过程都需要将数据存储在群集中,并且在中间计算过程中会产大量的暂时数据或日志,这样会造成数据急速膨胀,对服务器存储造成极大压力。
技术实现思路
1、为了解决现有技术中存在的上述技术问题,本发明提出了一种基于流式处理的数仓建设方法和系统,以解决上述技术问题。
2、根据本发明的第一方面,提出了一种基于流式处理的数仓建设方法,包括:
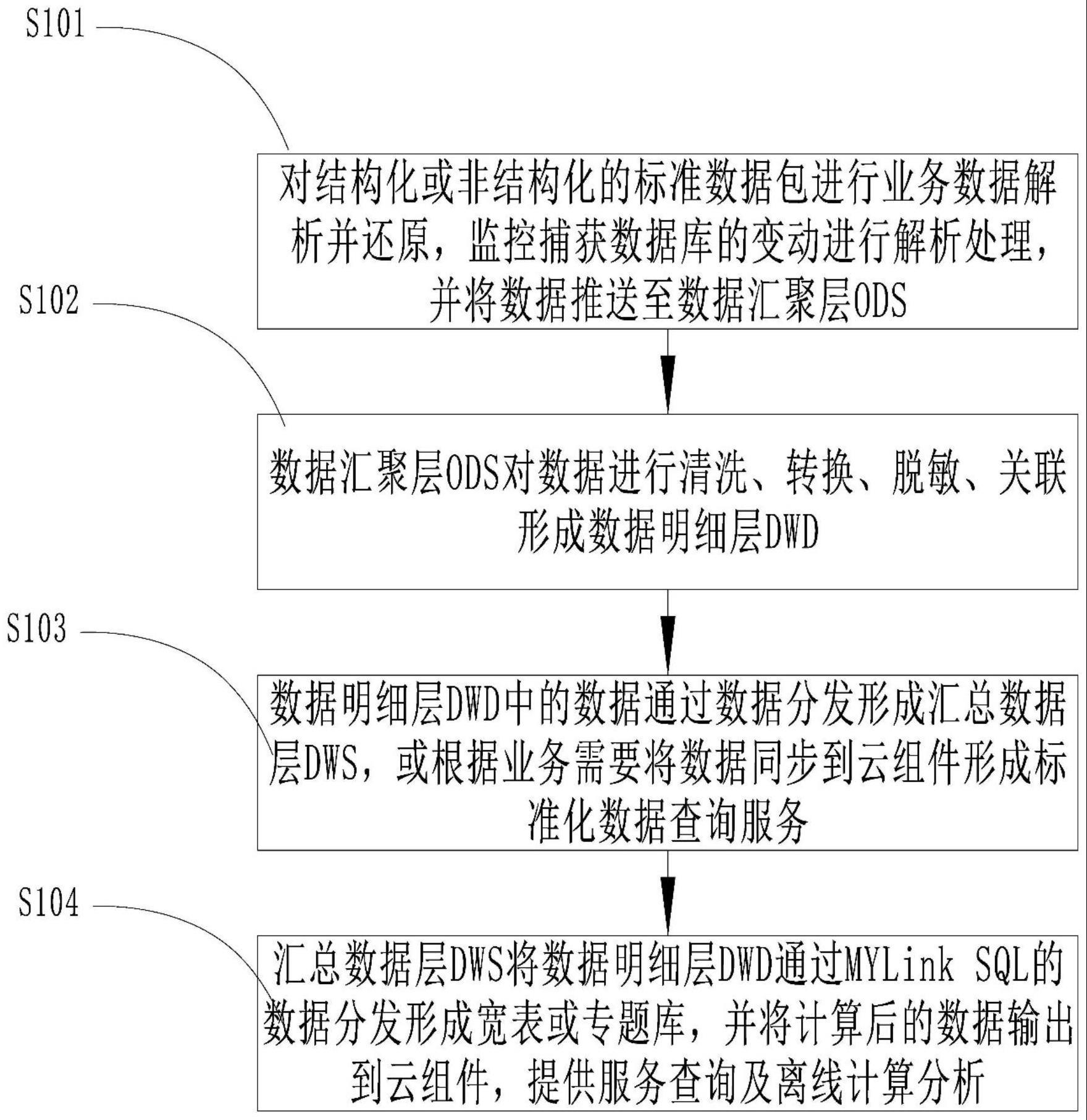
3、s1:对结构化或非结构化的标准数据包进行业务数据解析并还原,监控捕获数据库的变动进行解析处理,并将数据推送至数据汇聚层ods;
4、s2:数据汇聚层ods对数据进行清洗、转换、脱敏、关联形成数据明细层dwd;
5、s3:数据明细层dwd中的数据通过数据分发形成汇总数据层dws,或根据业务需要将数据同步到云组件形成标准化数据查询服务;
6、s4:汇总数据层dws将数据明细层dwd通过mylink sql的数据分发形成宽表或专题库,并将计算后的数据输出到云组件,提供服务查询及离线计算分析。
7、在一些具体的实施例中,s1之前还包括对源头业务库根据数据汇聚层ods的采集规则进行数据采集,源头业务库可对应一或多个数据汇聚层ods。
8、在一些具体的实施例中,s1具体包括利用ssend工具将结构化或非结构化的标准数据包进行业务数据解析,利用datax将结构化或非结构化的数据解析并还原,利用flinkcdc监控捕获数据库的变动进行解析处理。
9、在一些具体的实施例中,s2中数据汇聚层ods用于存储的业务库数据保持业务数据的原貌,通过mylink引擎以sql+udf的方式对数据进行清洗、转换、脱敏、关联形成数据明细层dwd。
10、在一些具体的实施例中,s2还包括通过mylink引擎将数据直接输出到云组件中提供原始数据的追踪查询。
11、在一些具体的实施例中,云组件包括华为云认证组件或腾讯云。
12、在一些具体的实施例中,ssend工具、datax、flinkcdc均支撑消费队列作为数据汇聚层ods。
13、根据本发明的第二方面,提出了一种计算机可读存储介质,其上存储有一或多个计算机程序,该一或多个计算机程序被计算机处理器执行时实施上述的方法。
14、根据本发明的第三方面,提出了一种基于流式处理的数仓建设系统,包括:
15、数据处理单元,配置用于对结构化或非结构化的标准数据包进行业务数据解析并还原,监控捕获数据库的变动进行解析处理,并将数据推送至数据汇聚层ods,数据汇聚层ods对数据进行清洗、转换、脱敏、关联形成数据明细层dwd;
16、数据分发单元,配置用于将数据明细层dwd中的数据通过数据分发形成汇总数据层dws,或根据业务需要将数据同步到云组件形成标准化数据查询服务;
17、查询分析单元,汇总数据层dws将数据明细层dwd通过mylink sql的数据分发形成宽表或专题库,并将计算后的数据输出到云组件,提供服务查询及离线计算分析。
18、在一些具体的实施例中,还包括数据采集单元,配置用于讲源头业务库根据数据汇聚层ods的采集规则进行数据采集,源头业务库可对应一或多个数据汇聚层ods。
19、在一些具体的实施例中,利用ssend工具将结构化或非结构化的标准数据包进行业务数据解析,利用datax将结构化或非结构化的数据解析并还原,利用flinkcdc监控捕获数据库的变动进行解析处理;数据汇聚层ods用于存储的业务库数据保持业务数据的原貌,通过mylink引擎以sql+udf的方式对数据进行清洗、转换、脱敏、关联形成数据明细层dwd;通过mylink引擎将数据直接输出到云组件中提供原始数据的追踪查询。
20、在一些具体的实施例中,ssend工具、datax、flinkcdc均支撑消费队列作为数据汇聚层ods。
21、本发明提出了一种基于流式处理的数仓建设方法和系统,能够很好适用于流与批并存的业务场景,对于流和批同一套代码且可共用相同的资源,这样对于资源利用率高且资源开销小。只要实现一套代码在开发、测试、发布上线难度大大降低,后期的运维成本也少。对数据实时性要求高的场景都有很强的适应性。能快速部署,易维护的优点,大大降低企业的成本与提高适应性。
- 还没有人留言评论。精彩留言会获得点赞!