数据处理方法和装置、电子设备及存储介质与流程
本申请涉及金融科技领域,尤其涉及一种数据处理方法和装置、电子设备及存储介质。
背景技术:
1、随着人工智能的兴起,各大金融系统平台、医疗平台系统均开始研发各类人工智能模型以辅助业务开展,在进行金融、医疗等数据交易的过程中,采用联邦学习会存在恶意攻击获取交易数据的现象。例如在银行系统进行联邦学习的过程中,当攻击者出现时,其调用交易数据的目的是要获取数据的详细标签和对应关系信息,因此,攻击者通常会多次调用交易数据,然后利用多次调用出的交易数据求交,找出其中相同的部分,之后再找出对应缺失标签并进行数据对应,进而实现对隐私数据的准确获取,因此,如何提高联邦学习数据交易的过程中的数据隐私保护效果,成为了亟待解决的技术问题。
技术实现思路
1、本申请实施例的主要目的在于提出一种数据处理方法和装置、电子设备及存储介质,旨在提高联邦学习中的数据隐私保护效果。
2、为实现上述目的,本申请实施例的第一方面提出了一种数据处理方法,所述方法包括:
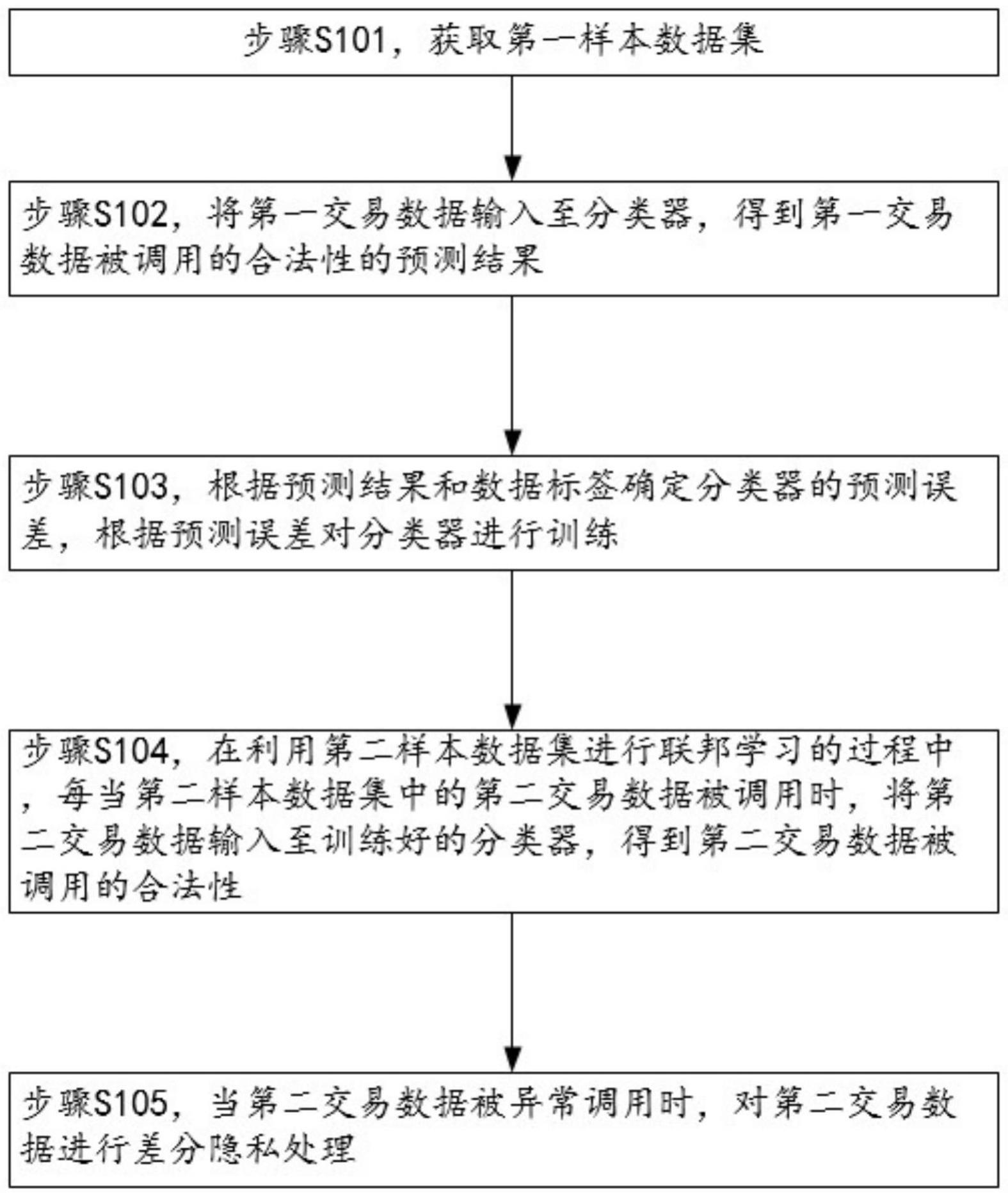
3、获取第一样本数据集,其中,所述第一样本数据集包括标注有数据标签的第一交易数据,所述数据标签用于指示所述第一交易数据被调用的合法性;
4、将所述第一交易数据输入至分类器,得到所述第一交易数据被调用的合法性的预测结果;
5、根据所述预测结果和所述数据标签确定所述分类器的预测误差,根据所述预测误差对所述分类器进行训练;
6、在利用第二样本数据集进行联邦学习的过程中,每当所述第二样本数据集中的第二交易数据被调用时,将所述第二交易数据输入至训练好的所述分类器,得到所述第二交易数据被调用的合法性;
7、当所述第二交易数据被异常调用时,对所述第二交易数据进行差分隐私处理。
8、在一些实施例,所述将所述第一交易数据输入至分类器,包括:
9、从所述第一样本数据集中确定存在被调用历史的所述第一交易数据;
10、利用存在被调用历史的所述第一交易数据对分类器进行预训练;
11、从所述第一样本数据集中随机抽取出所述第一交易数据,输入至预训练后的所述分类器。
12、在一些实施例,所述根据所述预测结果和所述数据标签确定所述分类器的预测误差,根据所述预测误差对所述分类器进行训练,包括:
13、确定各个所述第一交易数据在当前迭代轮次中的样本权重;
14、根据所述预测结果和所述数据标签确定预测错误的所述第一交易数据,根据预测错误的所述第一交易数据对应的所述样本权重之和,确定所述分类器的预测误差;
15、根据所述预测误差确定所述分类器在当前迭代轮次中的分类权重;
16、根据多个迭代轮次中的所述分类权重对所述分类器进行线性组合,得到训练好的分类器。
17、在一些实施例,确定各个所述第一交易数据在当前迭代轮次中的样本权重,包括:
18、确定所述第一样本数据集的代价矩阵;
19、根据所述代价矩阵确定各个所述第一交易数据在当前迭代轮次中的样本权重。
20、在一些实施例,所述根据所述代价矩阵确定各个所述第一交易数据在当前迭代轮次中的样本权重,包括:
21、若所述第一交易数据在前一个迭代轮次中被预测错误,根据所述代价矩阵增加所述第一交易数据在当前迭代轮次中的样本权重;
22、或者,若所述第一交易数据在前一个迭代轮次中被预测正确,根据所述代价矩阵减小所述第一交易数据在当前迭代轮次中的样本权重。
23、在一些实施例,所述对所述第二交易数据进行差分隐私处理,包括:
24、基于拉普拉斯机制向所述第二交易数据添加噪声分布,得到第三交易数据;
25、其中,所述第二交易数据和所述第三交易数据之间相差一个数据元素。
26、在一些实施例,所述数据处理方法还包括:
27、调用随机函数,将所述第二交易数据作为所述随机函数的自变量,计算所述第二交易数据属于目标集合的第一概率值;
28、将所述第三交易数据作为所述随机函数的自变量,计算所述第三交易数据属于所述目标集合的第二概率值;
29、根据所述第一概率值和所述第二概率值计算隐私预算值;
30、当所述隐私预算值大于或者等于预设的预算阈值,调整添加至所述第二交易数据中的所述噪声分布。
31、为实现上述目的,本申请实施例的第二方面提出了一种数据处理装置,所述装置包括:
32、样本数据获取模块,用于获取第一样本数据集,其中,所述第一样本数据集包括标注有数据标签的第一交易数据,所述数据标签用于指示所述第一交易数据被调用的合法性;
33、第一预测模块,用于将所述第一交易数据输入至分类器,得到所述第一交易数据被调用的合法性的预测结果;
34、训练模块,用于根据所述预测结果和所述数据标签确定所述分类器的预测误差,根据所述预测误差对所述分类器进行训练;
35、第二预测模块,用于在利用第二样本数据集进行联邦学习的过程中,每当所述第二样本数据集中的第二交易数据被调用时,将所述第二交易数据输入至训练好的所述分类器,得到所述第二交易数据被调用的合法性;
36、隐私处理模块,用于当所述第二交易数据被异常调用时,对所述第二交易数据进行差分隐私处理。
37、为实现上述目的,本申请实施例的第三方面提出了一种电子设备,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现上述第一方面所述的数据处理方法。
38、为实现上述目的,本申请实施例的第四方面提出了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现上述第一方面所述的数据处理方法。
39、本申请提出的数据处理方法和装置、电子设备及存储介质,其通过第一样本数据集中标注有数据标签的第一交易数据对分类器进行训练,使得分类器具有识别输入的交易数据被调用是否合法的能力,因此,当在联邦学习中存在第二交易数据被调用时,可以通过分类器判断第二交易数据被调用的合法性,当第二交易数据被判断为异常调用(相当于被不合法调用)时,对第二交易数据进行差分隐私处理,以使被调用的第二交易数据信息并不准确,进而使得攻击者更难获取到准确的隐私数据,从而能够在对金融平台,如银行系统、电子交易平台等进行联邦学习的过程中,判断交易数据被调用的合法性,并进行相应的差分隐私处理,使得攻击者难以获得准确的交易隐私数据,如银行交易数据、电子交易订单数据等。因此,本申请提高了联邦学习中交易数据的隐私保护效果。
技术特征:
1.一种数据处理方法,其特征在于,所述方法包括:
2.根据权利要求1所述的数据处理方法,其特征在于,所述将所述第一交易数据输入至分类器,包括:
3.根据权利要求1所述的数据处理方法,其特征在于,所述根据所述预测结果和所述数据标签确定所述分类器的预测误差,根据所述预测误差对所述分类器进行训练,包括:
4.根据权利要求3所述的数据处理方法,其特征在于,确定各个所述第一交易数据在当前迭代轮次中的样本权重,包括:
5.根据权利要求4所述的数据处理方法,其特征在于,所述根据所述代价矩阵确定各个所述第一交易数据在当前迭代轮次中的样本权重,包括:
6.根据权利要求1所述的数据处理方法,其特征在于,所述对所述第二交易数据进行差分隐私处理,包括:
7.根据权利要求6所述的数据处理方法,其特征在于,所述数据处理方法还包括:
8.一种数据处理装置,其特征在于,包括:
9.一种电子设备,其特征在于,所述电子设备包括存储器和处理器,所述存储器存储有计算机程序,所述处理器执行所述计算机程序时实现权利要求1至7任一项所述的数据处理方法。
10.一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现权利要求1至7中任一项所述的数据处理方法。
技术总结
本申请实施例提供了一种数据处理方法和装置、电子设备及存储介质,属于金融科技领域。该数据处理方法包括:获取第一样本数据集;将第一交易数据输入至分类器,得到第一交易数据被调用的合法性的预测结果;根据预测结果和数据标签确定分类器的预测误差,根据预测误差对分类器进行训练;在利用第二样本数据集进行联邦学习的过程中,每当第二样本数据集中的第二交易数据被调用时,将第二交易数据输入至训练好的分类器,得到第二交易数据被调用的合法性;当第二交易数据被异常调用时,对第二交易数据进行差分隐私处理。本申请实施例能够提高针对金融交易,如电子支付、银行系统等,进行联邦学习时的数据隐私保护效果,且可以广泛应用在人工智能领域。
技术研发人员:李泽远,王健宗
受保护的技术使用者:平安科技(深圳)有限公司
技术研发日:
技术公布日:2024/1/14
- 还没有人留言评论。精彩留言会获得点赞!