一种针对供应链数据缺失的补全方法及装置
本说明书一个或多个实施例涉及计算机,尤其涉及一种针对供应链数据缺失的补全方法及装置。
背景技术:
1、数据补全(data imputation)是一种重要的数据治理技术,其目的是利用已有的多源多维度数据来填补数据集中的缺失值或缺失数据点,为数据分析建模、价值挖掘奠定基础。在企业数字化转型过程中,数据缺失一直是一个不可忽视的重要问题。数据缺失会降低数据整体质量,进而影响智能算法和模型分析结果的可靠性,有时甚至会导致完全相反的观点和结论。因此,数据补全对于保障企业业务经营及管理决策分析的准确性和科学性非常重要。例如,大型供应链集成服务企业集团(以下简称大型供应链企业)的上下游客商、大宗商品价格等关键信息缺失会影响对市场发展趋势的研判,导致出现经营亏损和商业风险增加的情况。而在企业投资并购过程中,关键商业信息的缺失和错误会在资产评估中引入极端值,从而产生极大的投资风险。另外,在医疗实验中,关键变量信息的缺失或错误可能导致分析结论产生偏差,误导科研人员和医护人员评估治疗手段的有效性和安全性。因此,在当今大数据分析与应用迅猛发展的时代,数据治理过程中关于缺失数据的补全研究获得了企业界及学术界的广泛关注。
2、在大型供应链企业的实际数据应用场景中,数据往往并非独立存在,而以系列的形式构成由多个数据表组成的大规模数据集,且不同数据表之间存在一定的互补关系。因此,针对某一数据表的数据缺失问题,可以通过引入其它数据表的相同或相似字段,从而一定程度地解决该问题。然而,引入其它数据表来最大程度地解决数据缺失问题面临着巨大的挑战。大型供应链企业数字化转型过程中,由于缺乏前瞻性的规划和统一的数据标准,常常会出现系统“烟囱”和数据“孤岛”问题,导致数据的表单、字段、时间、部门等方面存在差异,数据之间往往缺少有效的关联。因此,引入其它数据表来补全缺失数据时,首先需要建立数据之间的关联关系。例如,由于不同的数据表中都包含企业识别码,因此数据表a缺失的企业地址可能可以在数据表b中通过同一企业识别码找到。具体来说,面临的挑战如下:
3、(1)大规模数据集中每张数据表都包含大量的数据列(属性)和数据行(条目),庞大的数据空间导致了数据治理过程中数据检索工作的低效和冗长。数据检索工作的复杂度随着数据表以及数据列、数据行的数量增加而呈现指数级上升趋势,使得数据治理专业人员难以从中检索到用于补全当前数据表缺失的数据信息。
4、(2)由于不同数据表中存在数据分布、类型、格式及结构等方面的数据异质性问题,因此代表相同属性的数据列可能在不同数据表中以不同的列名或数据分布等形式出现。同样,代表相同条目的数据行在其他数据表中也可能以不同的数据属性存在。采用简单的统计和模糊匹配方法容易忽略大量正确的关联关系,因此,需要采用科学方法来有效解决关联数据的同质性问题,从而使不同数据表中该企业名称的缺失数据能够相互补全。
5、(3)在建设供应链大数据中心、推进多维度数据归集的过程中,由于存在较多数据质量问题,构建准确的数据关联关系非常困难,需要用户结合背景知识来验证关联关系和数据补全结果。由于复杂的数据关联关系导致数据验证工作量庞大且充满挑战,因此需要设计一种新型高效的交互式可视化解决方案,引导用户验证数据补全过程、提升补全效率。
技术实现思路
1、本说明书一个或多个实施例描述了一种针对供应链数据缺失的补全方法及装置,能够提升供应链数据补全的准确性。
2、第一方面,提供了一种针对供应链数据缺失的补全方法,包括:
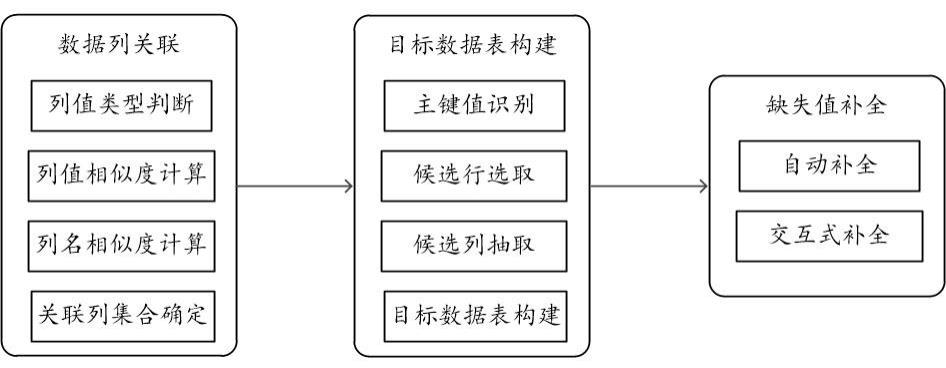
3、获取用于记录供应链数据的多个数据表,其中的每个数据表包含多个数据列;
4、针对所述多个数据表所包含的各数据列,两两计算列值相似度,得到列值相似度矩阵;以及两两计算列名相似度,得到列名相似度矩阵;所述列值/列名相似度矩阵中的各矩阵行分别对应于所述各数据列,且其中的各矩阵列分别对应于所述各数据列;
5、对所述列值相似度矩阵和所述列名相似度矩阵进行融合,得到整体相似度矩阵;
6、基于所述整体相似度矩阵,针对所述多个数据表确定各关联列集合;
7、对于所述多个数据表中包含缺失值的第一数据表,从中确定出包含所述缺失值的第一数据行,并从所述多个数据表中除所述第一数据表外的其它各数据表中,查找与所述第一数据行具有共同主键值的各匹配数据行;所述第一数据行和所述各匹配数据行形成各目标数据行;
8、依次针对所述各目标数据行,从中抽取包含在所述各关联列集合中的数据列,得到各候选数据行;根据所述各候选数据行以及其中包含的各数据列,构建候选数据表;
9、对于所述候选数据表,根据所述各关联列集合,从中识别出存在关联关系的各组数据列,并将识别出的每组数据列中的各数据列堆叠在一列中,得到目标数据表;
10、根据所述目标数据表,对所述第一数据表中的缺失值进行补全。
11、第二方面,提供可一种可视化分析系统,包括:
12、数据概览视图,用于展示多个数据表所包含的各数据列中内容的缺失情况;所述多个数据表包括第一数据表,所述第一数据表包含缺失值;
13、控制面板视图,用于配置数据列关联过程中的列值相似度、列名相似度的计算方法;
14、列关系视图,用于展示所述多个数据表中数据列之间的关联关系;
15、矩阵视图,用于展示目标数据表;
16、所述矩阵视图,还用于接收用户的选择指令,并根据所述选择指令,从所述目标数据表中选取对应的内容对所述第一数据表中的缺失值进行补全;
17、其中,所述目标数据表通过以下步骤确定:
18、基于配置的所述计算方法,针对所述多个数据表所包含的各数据列,两两计算列值相似度,得到列值相似度矩阵;以及两两计算列名相似度,得到列名相似度矩阵;所述列值/列名相似度矩阵中的各矩阵行分别对应于所述各数据列,且其中的各矩阵列分别对应于所述各数据列;
19、对所述列值相似度矩阵和所述列名相似度矩阵进行融合,得到整体相似度矩阵;
20、基于所述整体相似度矩阵,针对所述多个数据表确定各关联列集合;
21、对于所述第一数据表,从中确定出包含所述缺失值的第一数据行,并从所述多个数据表中除所述第一数据表外的其它各数据表中,查找与所述第一数据行具有共同主键值的各匹配数据行;所述第一数据行和所述各匹配数据行形成各目标数据行;
22、依次针对所述各目标数据行,从中抽取包含在所述各关联列集合中的数据列,得到各候选数据行;根据所述各候选数据行以及其中包含的各数据列,构建候选数据表;
23、对于所述候选数据表,根据所述各关联列集合,从中识别出存在关联关系的各组数据列,并将识别出的每组数据列中的各数据列堆叠在一列中,得到所述目标数据表。
24、第三方面,提供了一种针对供应链数据缺失的补全装置,包括:
25、获取单元,用于获取用于记录供应链数据的多个数据表,其中的每个数据表包含多个数据列;
26、计算单元,用于针对所述多个数据表所包含的各数据列,两两计算列值相似度,得到列值相似度矩阵;以及两两计算列名相似度,得到列名相似度矩阵;所述列值/列名相似度矩阵中的各矩阵行分别对应于所述各数据列,且其中的各矩阵列分别对应于所述各数据列;
27、融合单元,用于对所述列值相似度矩阵和所述列名相似度矩阵进行融合,得到整体相似度矩阵;
28、确定单元,用于基于所述整体相似度矩阵,针对所述多个数据表确定各关联列集合;
29、查找单元,用于对于所述多个数据表中包含缺失值的第一数据表,从中确定出包含所述缺失值的第一数据行,并从所述多个数据表中除所述第一数据表外的其它各数据表中,查找与所述第一数据行具有共同主键值的各匹配数据行;所述第一数据行和所述各匹配数据行形成各目标数据行;
30、抽取单元,用于依次针对所述各目标数据行,从中抽取包含在所述各关联列集合中的数据列,得到各候选数据行;根据所述各候选数据行以及其中包含的各数据列,构建候选数据表;
31、堆叠单元,用于对于所述候选数据表,根据所述各关联列集合,从中识别出存在关联关系的各组数据列,并将识别出的每组数据列中的各数据列堆叠在一列中,得到目标数据表;
32、补全单元,用于根据所述目标数据表,对所述第一数据表中的缺失值进行补全。
33、本说明书一个或多个实施例提供的一种针对供应链数据缺失的补全方法,针对多个数据表中的各数据列,通过两两计算列值相似度和列名相似度,得到列值相似度矩阵和列名相似度矩阵。之后通过对列值相似度矩阵和列名相似度矩阵进行融合,得到整体相似度矩阵,以及基于该整体相似度矩阵,针对该多个数据表确定出各关联列集合。最后,对于任一包含缺失值的数据表,基于各关联列集合,构建对应的目标数据表,该目标数据表包含与缺失值所在的行和列相似的数据行和数据列,并基于该目标数据表中的内容,对该缺失值进行补全,由此可以大大提升供应链数据补全的准确性。
- 还没有人留言评论。精彩留言会获得点赞!