基于融合注意力解耦特征的路侧遮挡人体姿态估计方法
本发明属于计算机视觉及智能交通路侧感知,涉及智能交通路侧感知人体三维姿态估计方法,具体涉及基于融合注意力解耦特征的路侧遮挡人体姿态估计方法。
背景技术:
1、近年来,我国在交通运输领域取得了巨大成就,在高速公路、城市轨道交通等多领域建设了举世瞩目的重大工程。随着基础设施的逐步完善,汽车保有量的快速增长以及通车里程的迅速增加,交通拥堵和交通安全问题层出不穷,智能交通系统的出现对提升交通效率和增强交通安全性能提供了新思路。智能交通系统是将计算机技术、传感器技术、电子控制技术、人工智能等诸多先进的科学技术综合运用于交通运输、控制、管理和车辆制造中的一种新型综合运输系统,其对提升交通效率和增强交通安全性能具有重要作用。在车路云一体化的智能交通系统中,路侧环境感知是一个至关重要的环节,其通过多种传感器感知人、车、路的多源信息,并与车端和云端通过新兴通信技术实现交互,从局部到全局实现多视角环境感知,综合处理复杂交通环境中智能汽车的规划、决策和控制。精确、高效的路侧环境感知技术为车路云一体化系统的高效运转提供了关键保障。
2、对行人目标的感知环节包括行人检测、姿态估计、行为识别和行为预测等,其中姿态估计任务为后续行为识别及预测提供了准确可靠的和姿态信息,是行人感知整体流程中必不可缺的基础。人体姿态估计作为行人感知的重要环节之一,是行人的行为识别、行为预测以及交通安全态势评估的重要基础。传统的基于计算机视觉的人体姿态估计方法先基于图结构和形变部件模型设计人体部件检测器,再根据人体运动学约束优化模型从而估计人体姿态。然而,传统方法依赖于人工设计的特征,其对于不同外观、视角下的各类人体的特征表达能力受限,导致无法适应交通环境下复杂多样的行人目标,影响感知精度。
3、随着人工智能技术的发展,基于深度学习的三维人体姿态估计技术得到了广泛的研究与应用。与传统的人工设计特征的方法相比,深度卷积神经网络具有强大的特征表达能力,其对于交通场景下的行人目标具有更好的适应性。现有的基于深度学习的三维人体姿态估计算法根据是否使用人体模型可以被分为基于模型类算法和不依赖模型类算法。基于模型类算法通常以人体的平均结构作为先验条件,将二维关键点向三维空间投影从而获取三维空间中的人体姿态,或直接以回归的方式实现高维空间的人体姿态参数优化。不依赖模型类算法直接从输入图像学习高维空间中的人体姿态。该方式由于结构简洁相较于基于模型类算法的速度更快,但其解空间的高度非线性导致其鲁棒性略逊于基于模型类算法。
4、尽管基于深度学习的姿态估计算法在近年来取得了巨大的进展,但大多数算法仅在一般场景中表现优异。在复杂的场景例如存在遮挡或多尺度等环境中,一般场景下的先进算法的精度将难以达到实际应用需求。其中,遮挡问题是复杂环境中的重大难点之一,多年来有不少研究针对遮挡问题提出了多种解决方案,主要包括数据侧的数据增广和算法侧的改进策略。在数据层面通常采用遮挡合成的方式生成各类遮挡模式下的训练数据,在算法层面大多引入辅助方式使网络先学习未被遮挡的目标特征,然后以该特征引导被遮挡目标的预测。例如,lasor利用合成的遮挡轮廓和2d关键点来回归smpl参数;metro利用transformer编码器对顶点-顶点和顶点-关键点的相互作用联合建模,并同时输出3d关键点和网格顶点的坐标,dcrowdnet提出了一种基于先验2d关键点的检测器来区分遮挡环境下的多个人体目标,并利用2d关键点标签实现3d姿态估计。然而,这些算法只能改善部分特定的遮挡场景,在复杂的交通路侧视角下,行人具有密集、流量大、行走轨迹复杂、行为多变等特点,构成了各类复杂多样的遮挡情况。此时,常用的基于深度学习的姿态估计方法难以提取有效特征,并容易混淆目标与非目标特征,导致对行人的关键点和形态感知出现偏差,从而估计出错误的人体姿态,严重影响感知系统的可靠性。因此,针对该难题的解决方案将有效提升智能交通系统感知环节的准确性与可靠性,进一步提升智能交通系统的服务能力。
技术实现思路
1、为解决上述问题,本发明公开了基于融合注意力解耦特征的路侧遮挡人体姿态估计方法,有效地解决了当前大部分基于深度学习的三维人体姿态估计方法难以适应交通环境下复杂遮挡环境的问题,进一步提升了人体三维姿态估计的准确性和鲁棒性。
2、为达到上述目的,本发明的技术方案如下:
3、基于融合注意力解耦特征的路侧遮挡人体姿态估计方法,包括以下步骤:
4、步骤一:建立人体三维姿态估计数据集;
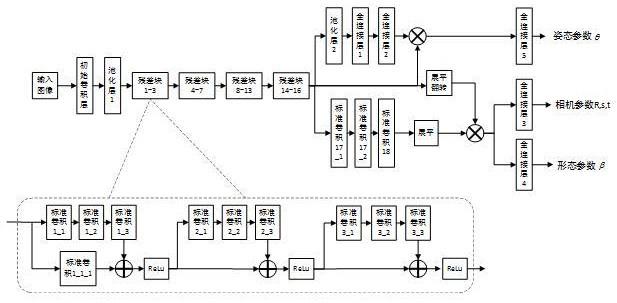
5、步骤二:构建基于融合注意力解耦特征的遮挡人体三维姿态估计网络架构:首先,设计深度卷积残差特征提取网络提取输入图像的高维特征;然后,设计通道注意力特征增强模块对高维特征图进行通道建模,对目标的关键点特征进行特征调制;接着,设计语义分割空间注意力特征增强模块对高维特征图进行空间建模,对目标的形态特征进行特征调制;最后,设计融合注意力解耦结构以及基于此结构的姿态估计网络,将原始特征进行解耦分离并加权调制,最终得到基于融合注意力解耦特征的路侧遮挡人体三维姿态估计网络,
6、具体包括以下子步骤:
7、子步骤1:设计深度卷积残差特征提取网络,具体包括:
8、(1)设计初始卷积层。初始卷积层数量为1,卷积核的大小为7×7,卷积核数量为64,步长为2。
9、初始卷积层1:用64个7×7的卷积核与a×a像素的输入样本做卷积,步长为2,再经过bn层和relu激活,得到维度为的特征图。
10、(2)设计池化层。池化层数量为1,采用最大池化操作,采样尺寸为3×3,步长为2。
11、池化层1:用3×3的核对初始卷积层1输出的特征图做最大池化,步长为2,得到维度为的特征图。
12、(3)设计残差块。残差块数量为16,其中每个残差块都由一个1×1,3×3和1×1的标准卷积层构成,步长均为1。残差块1~3的结构一致,其中卷积核的数量分别为64,64,256,残差块4~7的结构一致,其中卷积核的数量分别为128,128,512,残差块8~13的结构一致,其中卷积核的数量分别为256,256,1024,残差块14~16的结构一致,其中卷积核的数量分别为512,512,2048。
13、①设计残差块1~3:
14、a.设计残差块1:
15、构建标准卷积1_1:用64个1×1的卷积核与池化层1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
16、构建标准卷积1_1_1:用256个1×1的卷积核与池化层1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
17、构建标准卷积1_2:用64个3×3的卷积核与标准卷积1_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
18、构建标准卷积1_3:用256个1×1的卷积核与构建标准卷积1_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
19、构建残差结构1:将标准卷积1_3与标准卷积1_1_1的输出特征图相加,再经过relu激活,得到维度为的特征图;
20、b.设计残差块2:
21、构建标准卷积2_1:用64个1×1的卷积核与残差结构1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
22、构建标准卷积2_2:用64个3×3的卷积核与标准卷积2_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
23、构建标准卷积2_3:用256个1×1的卷积核与构建标准卷积2_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
24、构建残差结构2:将标准卷积2_3与残差结构1的输出特征图相加,再经过relu激活,得到维度为的特征图;
25、c.设计残差块3:
26、残差块3的输入为残差结构2的输出特征图,残差块3包含标准卷积3_1、标准卷积3_2、标准卷积3_3和残差结构3,其结构分别与标准卷积2_1、标准卷积2_2、标准卷积2_3和残差结构2一致,最终得到维度为的特征图。
27、②设计残差块4~7:
28、a.设计残差块4:
29、构建标准卷积4_1:用128个1×1的卷积核与残差块3的输出特征图做卷积,步长为2,再经过bn层和relu激活,得到维度为的特征图;
30、构建标准卷积4_1_1:用512个1×1的卷积核与残差块3的输出特征图做卷积,步长为2,再经过bn层和relu激活,得到维度为的特征图;
31、构建标准卷积4_2:用128个3×3的卷积核与标准卷积4_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
32、构建标准卷积4_3:用512个1×1的卷积核与构建标准卷积4_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
33、构建残差结构4:将标准卷积4_3与标准卷积4_1_1的输出特征图相加,再经过relu激活,得到维度为的特征图;
34、b.设计残差块5:
35、构建标准卷积5_1:用128个1×1的卷积核与残差块4的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
36、构建标准卷积5_2:用128个3×3的卷积核与标准卷积5_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
37、构建标准卷积5_3:用512个1×1的卷积核与构建标准卷积5_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
38、构建残差结构5:将标准卷积5_3与残差结构4的输出特征图相加,再经过relu激活,得到维度为的特征图;
39、c.构建残差结构6~7:
40、残差块6的输入为残差结构5的输出特征图,残差块6包含标准卷积6_1、标准卷积6_2、标准卷积6_3和残差结构6,其结构分别与标准卷积5_1、标准卷积5_2、标准卷积5_3和残差结5一致,最终得到维度为的特征图。残差块7的输入为残差结构6的输出特征图,其结构和输出特征图维度与残差块6一致。
41、③设计残差块8~13:
42、a.设计残差块8:
43、构建标准卷积8_1:用256个1×1的卷积核与残差块7的输出特征图做卷积,步长为2,再经过bn层和relu激活,得到维度为的特征图;
44、构建标准卷积8_1_1:用1024个1×1的卷积核与残差块7的输出特征图做卷积,步长为2,再经过bn层和relu激活,得到维度为的特征图;
45、构建标准卷积8_2:用256个3×3的卷积核与标准卷积8_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
46、构建标准卷积8_3:用1024个1×1的卷积核与构建标准卷积8_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
47、构建残差结构8:将标准卷积8_3与标准卷积8_1_1的输出特征图相加,再经过relu激活,得到维度为的特征图;
48、b.设计残差块9:
49、构建标准卷积9_1:用256个1×1的卷积核与残差块8的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
50、构建标准卷积9_2:用1024个3×3的卷积核与标准卷积9_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
51、构建标准卷积9_3:用1024个1×1的卷积核与构建标准卷积9_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
52、构建残差结构9:将标准卷积9_3与残差结构8的输出特征图相加,再经过relu激活,得到维度为的特征图;
53、c.构建残差结构10~13:
54、残差块10的输入为残差结构9的输出特征图,残差块10包含标准卷积10_1、标准卷积10_2、标准卷积10_3和残差结构10,其结构分别与标准卷积9_1、标准卷积9_2、标准卷积9_3和残差结构9一致,最终得到维度为的特征图。残差块11的输入为残差结构10的输出特征图,残差块12的输入为残差结构11的输出特征图,残差块12的输入为残差结构11的输出特征图,残差块13的输入为残差结构11的输出特征图。残差结构11~13的结构和输出特征图维度与残差块10一致。
55、④设计残差块14~16:
56、a.设计残差块14:
57、构建标准卷积14_1:用512个1×1的卷积核与残差块13的输出特征图做卷积,步长为2,再经过bn层和relu激活,得到维度为的特征图;
58、构建标准卷积14_1_1:用2048个1×1的卷积核与残差块13的输出特征图做卷积,步长为2,再经过bn层和relu激活,得到维度为的特征图;
59、构建标准卷积14_2:用512个3×3的卷积核与标准卷积14_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
60、构建标准卷积14_3:用2048个1×1的卷积核与构建标准卷积14_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
61、构建残差结构14:将标准卷积14_3与标准卷积14_1_1的输出特征图相加,再经过relu激活,得到维度为的特征图;
62、b.设计残差块15:
63、构建标准卷积15_1:用512个1×1的卷积核与残差块14的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
64、构建标准卷积15_2:用2048个3×3的卷积核与标准卷积15_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
65、构建标准卷积15_3:用2048个1×1的卷积核与构建标准卷积15_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
66、构建残差结构15:将标准卷积15_3与残差结构14的输出特征图相加,再经过relu激活,得到维度为的特征图;
67、c.构建残差结构16:
68、残差块16的输入为残差结构15的输出特征图,残差块16包含标准卷积16_1、标准卷积16_2、标准卷积16_3和残差结构16,其结构分别与标准卷积15_1、标准卷积15_2、标准卷积15_3和残差结构15一致,最终得到维度为的特征图。
69、子步骤2:设计通道注意力特征增强模块,具体包括:
70、(1)设计池化层,池化层数量为1,采用全局平均池化操作。
71、池化层2:对步骤二的子步骤1中(3)④.c的残差块16输出的特征图做全局平均池化,得到维度为1×1×2048的特征图。
72、(2)设计全连接层,全连接层的数量为2。
73、全连接层1~2:对池化层2输出的特征图进行两次全连接操作,再经过relu激活函数和sigmoid函数得到维度为1×1×2048的特征向量。
74、(3)设计特征加权方式。将全连接层2输出的特征向量与池化层2的输入特征图进行逐通道相乘,得到维度为的特征图。
75、子步骤3:设计语义分割空间注意力特征增强模块,具体包括:
76、(1)设计标准卷积层,卷积层的数量为3,卷积核的大小分别为3×3、3×3和1×1,卷积核数量分别为c1、c2和(j+1),步长均为1。
77、标准卷积17_1:用c1个3×3的卷积核与步骤一中子步骤1的残差块16的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
78、标准卷积17_2:用c2个3×3的卷积核与标准卷积17_1的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
79、标准卷积18:用(j+1)个1×1的卷积核与标准卷积17_2的输出特征图做卷积,步长为1,再经过bn层和relu激活,得到维度为的特征图;
80、(2)设计辅助损失函数。引入人体语义分割标签标注的外轮廓作为网络的辅助监督,引入辅助损失函数:
81、
82、式(1)中采用交叉熵损失函数计算语义分割辅助损失函数,h、w表示特征图的大小,h=w=7,ph,w表示特征图上(h,w)处像素点的类别概率,表示特征图上(h,w)处像素点的类别真值。
83、(3)设计特征加权方式:
84、①提取标准卷积18的输出特征图的前j维特征,并沿着j维度将特征图展平,得到的特征图;
85、②将标准卷积17_1的输入特征图沿着通道维度展平,并进行矩阵翻转,得到的特征图;
86、③将步骤二的子步骤3(3)中的①和②的输出特征图进行逐元素相乘,得到2048×j的特征图。
87、子步骤4:设计融合注意力解耦结构姿态估计网络,具体包括:
88、(1)设计解耦结构。将步骤二子步骤1残差结构16输出的特征图分别输入步骤二子步骤2设计的通道注意力特征增强模块和步骤二子步骤3设计的语义分割空间注意力特征增强模块,构成两路并行分支解耦结构。
89、(2)设计全连接层,全连接层的数量为3。
90、全连接层3:对步骤二子步骤3(3)③输出的特征图进行一次全连接操作,再经过relu激活函数和sigmoid函数得到维度分别为9、2、1的特征向量r、t和s。
91、全连接层4:对步骤二子步骤3(3)③输出的特征图进行一次全连接操作,再经过relu激活函数和sigmoid函数得到维度为10的特征向量β。
92、全连接层5:步骤二子步骤2(3)输出的特征图进行一次全连接操作,再经过relu激活函数和sigmoid函数得到维度为3k的特征向量θ,其中k为人体关键点数量。
93、步骤三:训练设计的基于融合注意力解耦特征的遮挡人体三维姿态估计网络,获得网络参数;
94、步骤四:使用基于融合注意力解耦特征的遮挡人体三维姿态估计网络进行姿态估计。
95、本发明的有益效果是:
96、(1)本发明提出了一种交通环境下智能路侧视角的三维人体姿态估计方法,充分利用路侧设备感知视野广阔的优点,对交通环境下的行人目标实现全局感知,克服了智能交通系统中单一车载视角感知的视野局限性与存在视觉盲区的缺点,有效增强了行人姿态估计的准确性。
97、(2)本发明设计了基于融合注意力解耦特征的遮挡人体三维姿态估计网络,其中包括残差特征提取网络、通道注意力特征增强模块、语义分割空间注意力特征增强模块和融合注意力解耦结构。首先使用深度卷积残差特征提取网络提取输入图像的高维特征。然后,设计通道注意力特征增强模块对人体的关键点特征建模,改善遮挡造成的人体的关键点估计错误。接着,设计语义分割空间注意力特征增强模块对人体的形态特征建模,使用外部监督手段改善遮挡造成的人体形态估计错误。最后,设计两个并行的分支构成解耦结构,并将两注意力模块与解耦结构结合,构成融合注意力解耦结构姿态估计网络。该网络以特征增强的方式有效改善了交通路侧遮挡环境下姿态估计错误的问题,大大提升了姿态估计的准确性,与现存的绝大多数三维人体姿态估计算法相比,有效解决了遮挡环境下的三维人体姿态估计错误问题,大大提升了遮挡人体姿态估计的准确性和鲁棒性。
- 还没有人留言评论。精彩留言会获得点赞!