基于强化学习策略的翻译模型构建方法和存储介质与流程
本发明涉及自然语言处理,其特别涉及一种基于强化学习策略的翻译模型构建方法和存储介质。
背景技术:
1、近年来,随着深度神经网络的不断发展,神经机器翻译(neural machinetranslation,nmt)的研究取得重大突破,逐渐发展成为目前主流的机器翻译新模式;现有研究表明,在具备大规模、高质量的平行语料的通用领域中,nmt能够产生最优的翻译性能。
2、然而,现有的机器翻译引擎对垂直领域的翻译效果不尽人意,存在着术语词翻译错误、译文不符合领域风格等多种问题,这主要是因为在现实世界中,多数垂直领域缺乏特定于该领域的大规模、高质量的平行语料;且高质量的领域专用机器翻译系统需求量很大,而领域平行语料的构造需要耗费大量人力、物力及时间,成本昂贵;因此,如何利用少量域内平行数据更好地微调通用领域翻译模型,即如何将机器翻译模型的更好地进行领域适应,为垂直领域开发机器翻译系统,成为近年来的研究热点。
3、现有的机器翻译的领域适应的研究主要可以分成两个方面:基于数据和基于模型,基于数据的领域适应方案更关注对于所使用的数据的利用,而基于模型的适应方案更关注于对领域适应模型架构的改进;在目前的机器翻译领域适应中,基于数据的方法是较为主流的方法,其中最传统的方式是使用域内少量的平行数据微调通用领域预训练的nmt模型,或将域内平行数据和域外平行数据混合微调;但是在域内平行语料过少时,这种微调方式总是趋向于快速地过拟合于域内训练集,并且会存在模型对通用领域的翻译质量严重下降,即灾难性遗忘现象;为了解决这一现象,通常是简单地减少调优步骤,但其本质还是基于域外和域内数据的混合训练,无法为模型提供域内特点与域外特点的差异信息,模型通常很难学习到垂直领域的更深层次的领域性知识,如句子风格、术语翻译等;另外,近年来,也有一些研究为垂直领域引入额外的特定于域的参数或子网络,然而这通常需要设计复杂的子网络、域参数层等,并对原始的模型架构进行修改,模型在不同领域的应用也不够灵活。
技术实现思路
1、为了解决现有翻译模型域内翻译风格不强、术语翻译准确率低的问题,本发明提供一种基于强化学习策略的翻译模型构建方法和存储介质。
2、本发明为解决上述技术问题,提供如下的技术方案:一种基于强化学习策略的翻译模型构建方法,包括以下步骤:
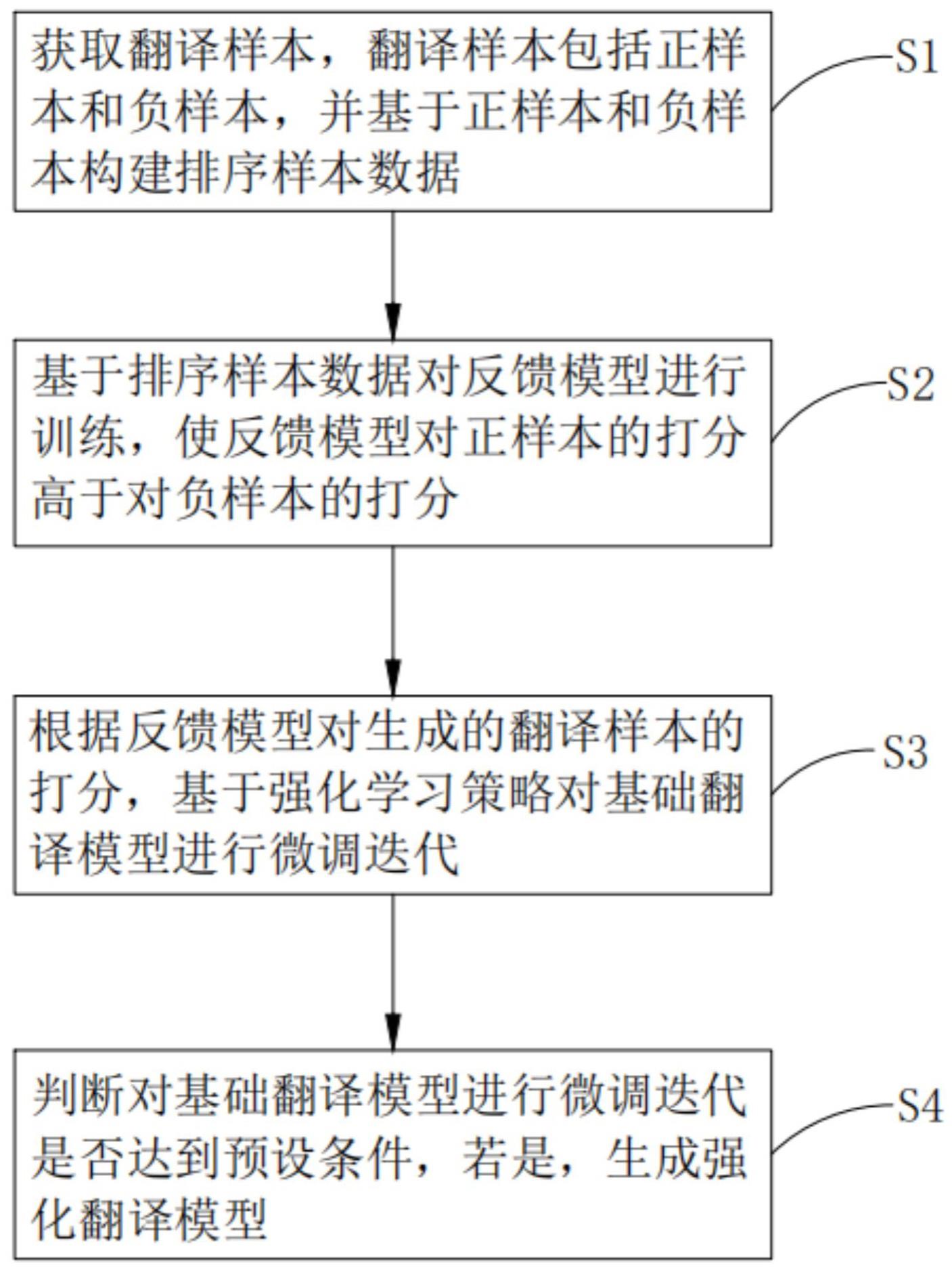
3、获取翻译样本,所述翻译样本包括正样本和负样本,并基于正样本和负样本构建排序样本数据;基于排序样本数据对反馈模型进行训练,使反馈模型对正样本的打分高于对负样本的打分;根据反馈模型对生成的翻译样本的打分,基于强化学习策略对基础翻译模型进行微调迭代;判断对基础翻译模型进行微调迭代是否达到预设条件,若是,生成强化翻译模型。
4、优选地,所述正样本包括垂直领域的平行数据;所述负样本包括使用通用领域翻译模型构建的翻译对、基于黄金平行语料进行术语替代生成的数据和基于伪平行语料进行术语替代生成的数据。
5、优选地,所述反馈模型通过语言模型层和线性打分层构成,所述语言模型层为预训练的m-bert模型。
6、优选地,基于排序样本数据对反馈模型进行训练,使反馈模型对正样本的打分高于对负样本的打分具体为:排序样本数据中的正样本和负样本均包括源端和目标端,分别将正样本与负样本的源端和目标端进行拼接得到翻译对,并将翻译对输入反馈模型,训练反馈模型对正样本的打分高于对负样本的打分。
7、优选地,训练反馈模型的损失函数为:
8、
9、其中,表示sigmoid函数;表示正样本的分数;表示负样本的分数。
10、优选地,根据反馈模型对生成的翻译样本的打分,基于强化学习策略对基础翻译模型进行微调迭代,具体包括以下步骤:
11、步骤s31:获取初始句子,基于初始句子进行采样得到初始样本数据;步骤s32:所述强化学习策略包括第一优化网络和第二优化网络,基于初始样本数据与第一优化网络,预测初始句子生成目标句的概率分布并计算策略目标;和基于初始样本数据与第二优化网络,预测初始句子生成目标句的分数并计算价值损失;步骤s33:基于策略目标和价值损失分别更新第一优化网络和第二优化网络,并重新开始步骤s31进行微调迭代。
12、优选地,预测初始句子生成目标句的概率分布并计算策略目标,具体计算公式为:
13、
14、其中,表示状态;表示动作;表示当前的第一优化网络预测初始句子生成目标句的概率分布;表示旧的第一优化网络预测初始句子生成目标句的概率分布;表示为状态下动作的优势函数;为超参数。
15、优选地,预测初始句子生成目标句的分数并计算价值损失,具体计算公式为:
16、
17、其中,表示状态;表示动作;表示当前状态的分数;表示基于反馈模型计算的反馈分数。
18、优选地,所述预设条件为基础翻译模型收敛和/或达到最大迭代次数。
19、本发明为解决上述技术问题,提供又一技术方案如下:一种计算机可读存储介质,计算机可读存储介质存储有计算机程序,计算机程序被执行时实现如前述任一项所述的基于强化学习策略的翻译模型构建方法。
20、与现有技术相比,本发明所提供的一种基于强化学习策略的翻译模型构建方法和存储介质,具有如下的有益效果:
21、1、本发明实施例中提供的一种基于强化学习策略的翻译模型构建方法,包括以下步骤:首先获取翻译样本,翻译样本包括正样本和负样本,并基于正样本和负样本构建排序样本数据;然后基于排序样本数据对反馈模型进行训练,使反馈模型对正样本的打分高于对负样本的打分;接着根据反馈模型对生成的翻译样本的打分,基于强化学习策略对基础翻译模型进行微调迭代;最后判断对基础翻译模型进行微调迭代是否达到预设条件,若是,生成强化翻译模型;即将强化学习策略用于机器翻译的领域适应,通过反馈模型进行打分,并引入术语翻译准确率信息,强化术语翻译准确率较高和领域风格较强的翻译,即将更符合垂直领域域内特点的句子作为正向反馈,较为不符合域内特点的句子作为负向反馈,以对基础翻译模型进行优化,使模型生成更符合垂直领域特点和风格句子,还能提升翻译模型对垂直领域术语翻译的准确率;通过对基础翻译模型进行微调迭代,对更符合领域风格的翻译进行强化,对较不符合领域特点的翻译进行弱化,以增强域内翻译;且利用强化翻译模型能够进行自监督学习和优化,具有较强的适应性和可迁移性,领域利用率更强。
22、2、本发明实施例中提供的正样本包括垂直领域的平行数据;负样本包括使用通用领域翻译模型构建的翻译对、基于黄金平行语料进行术语替代生成的数据和基于伪平行语料进行术语替代生成的数据;即正样本与目标领域的翻译任务更加贴合,能够提高翻译的准确度,保障翻译的质量;而负样本的构建能够进一步弱化模型对不符合目标领域风格的翻译生成,通过正、负样本的对比,强化模型对领域泛化知识进行学习;且使用的是不同来源的数据构成的数据样本,能够提高领域利用的灵活性,扩大了样本数据的规模,以更好地应对实际应用场景的各种翻译任务。
23、3、本发明实施例中提供的反馈模型通过语言模型层和线性打分层构成,语言模型层为预训练的m-bert模型,此设置用于对输入的排序样本数据进行打分,使更符合领域特点的翻译分数大于较不符合领域特点的翻译分数。
24、4、本发明实施例中提供的基于排序样本数据对反馈模型进行训练,使反馈模型对正样本的打分高于对负样本的打分具体为:排序样本数据中的正样本和负样本均包括源端和目标端,分别将正样本与负样本的源端和目标端进行拼接得到翻译对,并将翻译对输入反馈模型,训练反馈模型对正样本的打分高于对负样本的打分;即利用反馈模型为样本数据打分,使得正样本的得分大于负样本的得分,以此使反馈模型学习到更优的数据,即更符合领域特征的翻译,模型不仅能学习域内和域外翻译数据特点和风格的不同,也进一步学习到域内术语翻译高的数据应当具有较高的分数;另外,利用反馈机制可以自监督学习和优化,减少了人工干预的需求,提高了翻译效率和自动化程度。
25、5、本发明实施例中提供的根据反馈模型对正样本的打分和对负样本的打分,基于强化学习策略对基础翻译模型进行微调迭代,具体包括以下步骤:步骤s31:获取初始句子,基于初始句子进行采样得到初始样本数据;步骤s32:强化学习策略包括第一优化网络和第二优化网络,基于初始样本数据与第一优化网络,预测初始句子生成目标句的概率分布并计算策略目标;和基于初始样本数据与第二优化网络,预测初始句子生成目标句的分数并计算价值损失;步骤s33:基于策略目标和价值损失分别更新第一优化网络和第二优化网络,并重新开始步骤s31进行微调迭代;即通过与环境的交互作用在数据采样和梯度优化目标函数之间进行交替,从在线学习转化为离线学习,提升数据有效性和鲁棒性;且通过微调迭代优化,能够提高翻译效果和准确度;而采用基于策略目标和价值损失分别更新第一优化网络和第二优化网络的方法,可以优化训练过程,提高训练效率和精度,使得模型更好地应对实际应用场景中的各种翻译任务,提高其领域应用灵活性。
26、6、本发明实施例还提供一种计算机可读存储介质,具有与上述一种基于强化学习策略的翻译模型构建方法相同的有益效果,在此不做赘述。
- 还没有人留言评论。精彩留言会获得点赞!