图协同过滤推荐模型的预测方法
本发明涉及推荐系统和图卷积神经网络领域,具体地说,是一种基于原型对比和特征筛选的图协同过滤推荐模型的预测方法。
背景技术:
1、由于信息时代发展到大数据时代,如今的互联网上的数据规模呈爆炸式增长,导致信息超载成为我们生活中日益严重的问题。而推荐系统是缓解信息过载问题、方便用户寻求信息的有效解决方案,也可以增加服务提供商的流量和收入。因此,高效而准确的个性化推荐系统也就成为学术界和工业界的关注热点。而同时,图神经网络(gnn)的研究逐渐兴起,由于推荐系统中的大部分信息具有图结构,gnn在图表示学习方面具有优势,因此在推荐系统中得到了广泛的应用。
2、传统的基于图卷积的推荐模型未从频域下对图卷积进行分析,对用户项目交互图中不同频率的特征一视同仁,这就不可避免地引入了噪声。事实上,用户与项目的交互信息中只有少部分邻居的平滑或者粗糙特征对推荐有促进,大部分的图信息都可以看作噪声,并且反复的图卷积操作只能促进邻居平滑,不能有效过滤噪声,同时也使图卷积变得低效。另外为了减少数据稀疏性的影响,传统的基于图卷积的推荐模型采用了对比学习的方法来提高性能。然而,这些方法通常采用随机采样的方式构建对比对,忽略了用户(或项目)之间的潜在关系,不能充分利用对比学习在推荐系统中的潜力。
3、有鉴于此,确有必要提出一种基于原型对比和特征筛选的图协同过滤推荐模型的预测方法,以解决上述问题。
技术实现思路
1、本发明的目的在于提供一种图协同过滤推荐模型的预测方法,能够有效地提高图卷积的效率并缓解数据稀疏的问题。
2、为实现上述目的,本发明提供了一种图协同过滤推荐模型的预测方法,主要包括以下步骤:
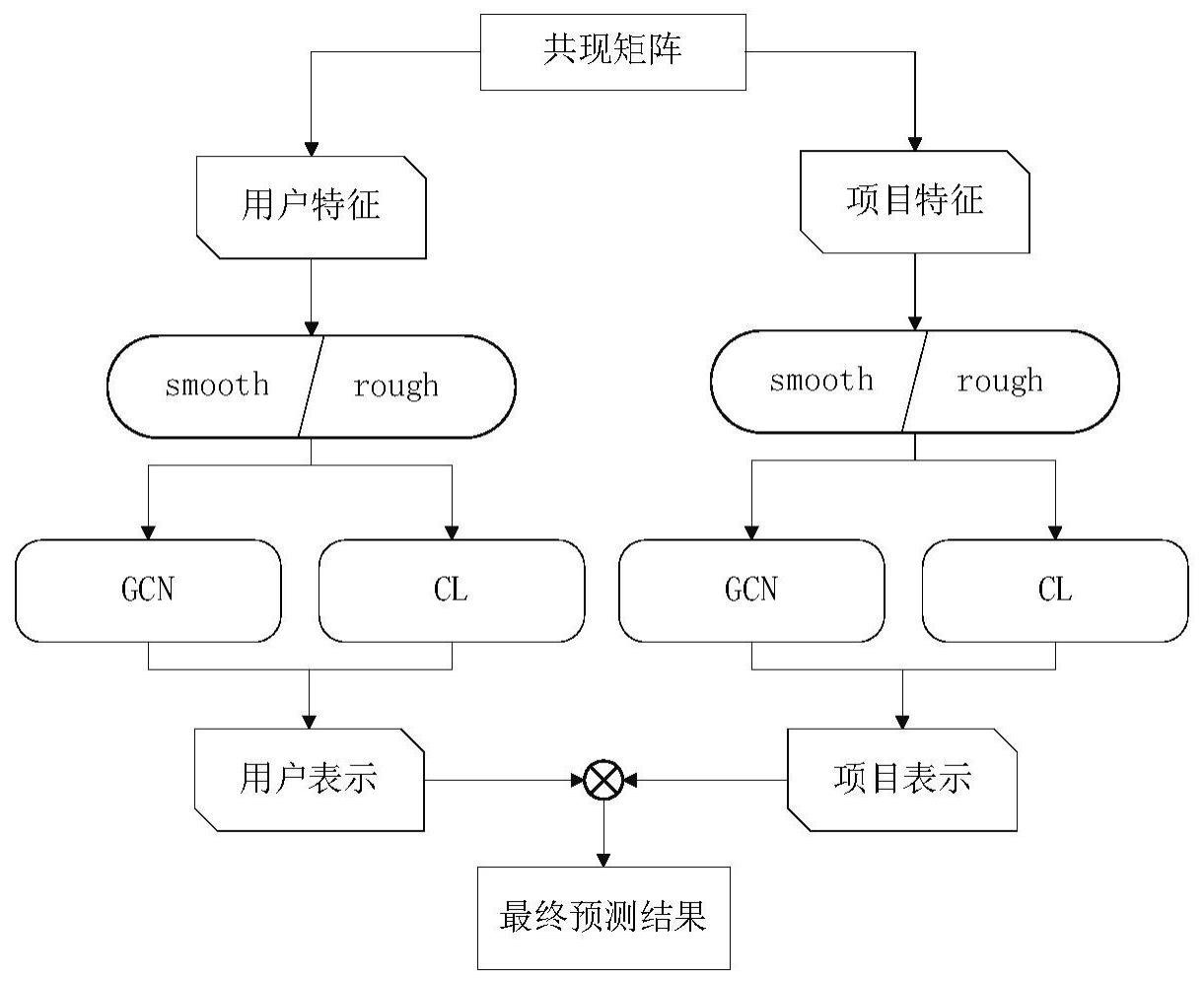
3、步骤1,建立问题:根据用户与项目的交互矩阵a∈rm×n建立一个二部图,明确模型的输入输出;
4、步骤2,初始嵌入层:使用嵌入向量uk∈rd和ik∈rd来描述一个用户和一个项目,其中d是嵌入维度;
5、步骤3,特征筛选:利用模型的图卷积滤波器对交互特征进行筛选并且只进行一层卷积,该一层卷积会卷到任意远的节点;
6、步骤4,原型对比学习任务:利用空间中语义相似的集群中心的嵌入来与目标节点构建对比对,该集群中心的节点即为原型,使用期望最大化算法来推断原型,此时目标节点的对比学习任务能够通过与原型之间的对比来完成;
7、步骤5,嵌入传播层:模型中的嵌入传播层建立在gcn的消息传递架构上,用来捕获协同过滤信号以及用户与项目交互的图结构;所述模型使用超图卷积,并用特征筛选的滤波器重写卷积公式;
8、步骤6,结果预测:在经过嵌入传播层的卷积以及对比任务的学习后,通过pooling函数得到用户u和项目i的最终表示形式,建立目标用户u对项目i进行交互的可能性公式,将用户u对项目i的最终表示进行结合作为最终的交互预测,利用损失函数进行模型训练;
9、作为本发明的进一步改进,所述步骤1具体包括:输入的用户-项目交互数据用无向图g=(v,e)表示,其中节点集v由用户节点u∈u和项目节点i∈i组成,边集e由用户和项目之间的交互关系组成,若用户与项目之间有交互,则二者之间存在连边,否则无连边;所有用户和项目之间的交互数据即为模型的输入,对目标用户是否会与目标项目进行交互的预测即为模型的输出。
10、作为本发明的进一步改进,所述步骤2具体包括:用户嵌入向量和项目嵌入向量分别用嵌入矩阵u和i表示:
11、u={u1,u2,…um}
12、i={i1,i2,…,in}
13、模型使用one-hot编码作为输入来作为用户和项目的初始嵌入,则矩阵u、i能够视为用户和项目的初始化特征,即模型的输入特征。
14、作为本发明的进一步改进,所述步骤3具体包括:将交互图g划分为平滑gs图、粗糙gr图和噪声gn图,它们分别由平滑、粗糙和噪声特征组成,使用在gs和gr上的嵌入生成最终表示,而来自gn的嵌入被过滤掉,即为带通滤波器:
15、
16、其中λt代表对应交互特征的特征值,代表user/item;
17、使用超图卷积,用户和项目的交互表示为:
18、
19、
20、其中du,di,是用户和项目的对角度矩阵,r表示用户和项目的交互矩阵,rt表示该矩阵的转置矩阵,使用滤波器代替超图卷积中原来的特征值组成的对角阵,则在超图上生成的嵌入表达式如下:
21、
22、其中e表示嵌入矩阵,{p,π}表示前m个最平滑或者最粗糙的{特征向量,特征值},pt表示p的转置矩阵。
23、作为本发明的进一步改进,所述步骤4具体包括:对用户和项目的嵌入应用k-means算法进行聚类分成k个簇,让簇内的节点尽量紧密,而簇间的距离尽可能大,然后用em算法学习每一个簇的原型,即最大化对数似然函数
24、
25、其中,eu表示用户u的嵌入,ci是用户u的潜在原型,r是交互矩阵,φ是一组模型参数,先用jensen不等式得到它的下界
26、
27、其中q(ci|eu)为观察到eu时潜在变量ci的分布,在估计q(ci|eu)时重定向目标使eu上的函数最大化,在最大化步骤中,利用将目标函数重写
28、
29、设用户在所有簇上服从各向同性的高斯分布,则
30、
31、其中,cj表示目标节点所在的簇之外的其他簇的原型,δ代表高斯分布的方差,最小化此目标函数即可完成用户的对比学习任务。
32、作为本发明的进一步改进,所述步骤5具体包括:将平滑超图上生成的嵌入表示如下:
33、
34、
35、其中分别是user邻接矩阵和item邻接矩阵中最平滑的m1和n1个{特征向量,特征值},γ(·)输出不同特征的重要性权重,eu和ei分别代表user和item的嵌入矩阵,类似地,在具有最粗糙的m2和n2个{特征向量,特征值}的粗糙超图上进行嵌入,以便学习其异质性:
36、
37、
38、其中,分别是user邻接矩阵和item邻接矩阵中最粗糙的m2和n2个{特征向量,特征值}。
39、作为本发明的进一步改进,所述步骤6具体包括:令步骤5中m=m1+m2,n=n1+n2,通过pooling函数生成最终的表示:
40、
41、
42、此处的pooling函数采用求和的方式;其中,β是指数函数的系数,k是麦克劳林展开的阶数,代表去掉了噪声的邻接矩阵,下标的u/i代表用户/项目,ou和oi作为用户和项目的最终表示,使用二者的内积来表示最终预测的用户和项目交互的可能性,即
43、
44、采用贝叶斯个性化排名bpr损失来作为图卷积的损失函数,形式上,该损失函数如下:
45、
46、其中,c={(u,i,j)|(u,i)∈r+,(u,j)∈r-}表示成对的交互数据,σ()代表sigmoid激活函数,j代表用户未交互项目,则模型整体的损失函数为
47、l=lbpr+lp,
48、其中lp为对比学习任务的损失函数。
49、本发明的有益效果为:本发明通过对交互信息的共现矩阵特征进行筛选,过滤显式交互特征中的噪声,并且利用原型构建节点级的对比学习目标来丰富用户和项目的最终表示,因此可以有效地提高图卷积的效率并缓解数据稀疏的问题。另外,通过重写超图卷积公式使得卷积过程只需要一次,避免了传统图协同过滤模型多次卷积所引起的特征平滑的问题,使得推荐系统模型的效率和性能都得到了提升。
- 还没有人留言评论。精彩留言会获得点赞!