推荐模型的训练方法、推荐模型以及存储介质与流程
本技术实施例涉及互联网,尤其涉及推荐模型的训练方法、推荐模型以及存储介质。
背景技术:
1、现有的推荐系统广泛应用于各类互联网在线服务,帮助用户更快发现感兴趣的物品,如视频、音乐以及书籍等。目前推荐系统存在曝光偏差,热门物品的曝光次数较大,推荐系统的学习权重较大,后续推荐时越趋于推荐该热门物品,而冷门物品的曝光次数较小,推荐系统的学习权重较小,后续推荐时更不容易推荐该冷门物品,即容易导致马太效应:热门的物品变得更加热门,而冷门的物品变得更加冷门。
2、现有的解决马太效应的方法为,采用热度降权的方法,减少曝光次数较大的热门物品的学习权重,提高曝光次数较小的冷门物品的学习权重,以打压热门物品,提高推荐的多样性。然现有的解决方法得到的推荐系统,在推荐物品时,单纯地减少推荐曝光次数较大的热门物品,推荐更多曝光次数较小的冷门物品,推荐的物品难以反映用户的真实兴趣,推荐的精度较低。
技术实现思路
1、本技术实施例提供了推荐模型的训练方法、推荐模型以及存储介质;在解决马太效应的同时,该推荐模型推荐的样本更能够反映用户的真实兴趣,提高推荐精度。
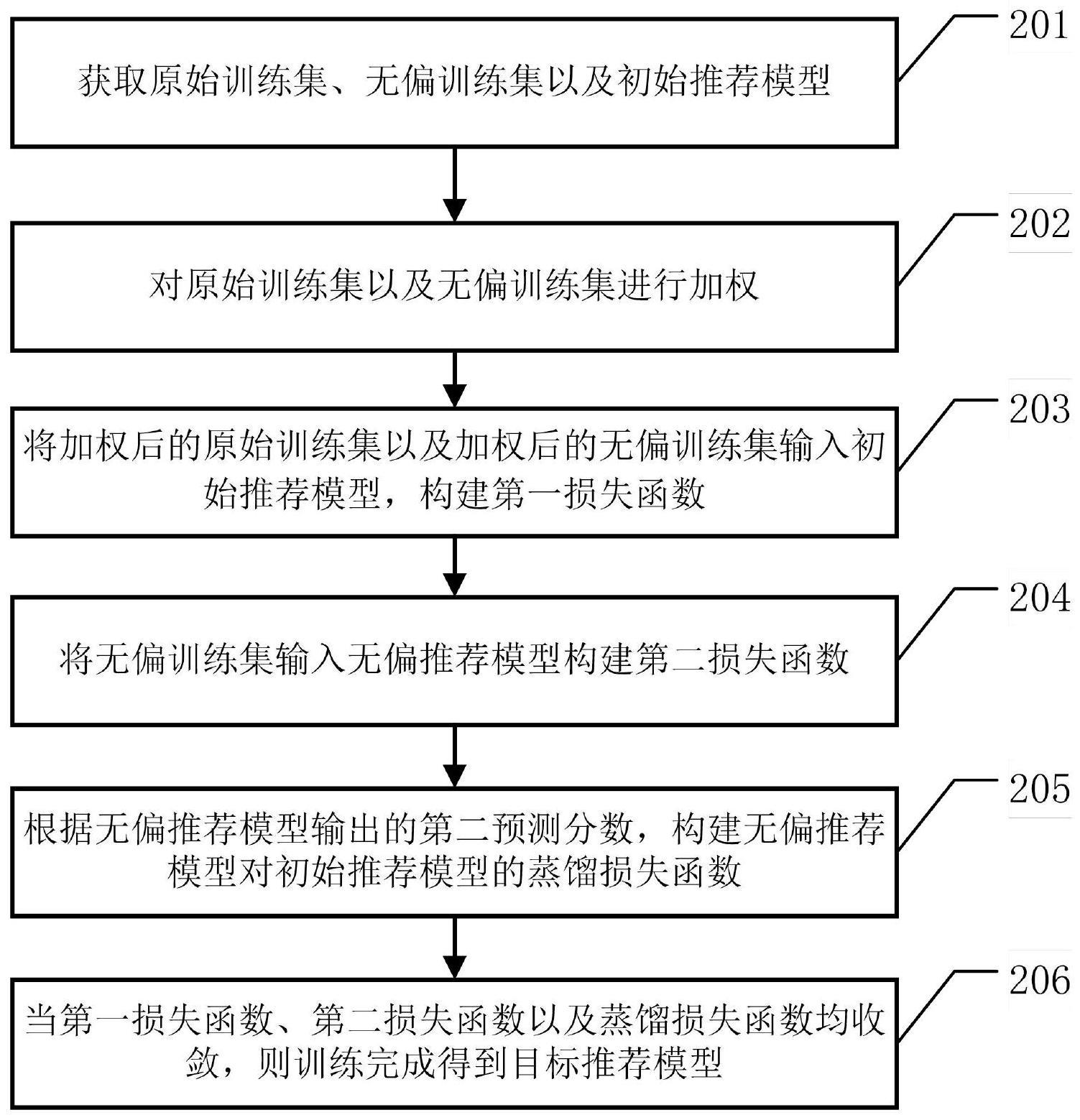
2、本技术实施例提供了一种推荐模型的训练方法,包括:
3、获取原始训练集、无偏训练集以及初始推荐模型,其中,所述原始训练集包括:推荐系统推荐的样本,所述无偏训练集包括:在所述推荐系统的候选推荐样本中随机选取的样本,所述初始推荐模型用于预测输入的样本被用户完整浏览的概率;
4、获取所述原始训练集以及所述无偏训练集中样本是否被用户完整浏览的样本标签;
5、对所述无偏训练集的样本进行加权,并基于所述原始训练集的样本属于所述无偏训练集的概率对所述原始训练集的样本进行加权;
6、将加权后的原始训练集以及加权后的无偏训练集中的第一样本输入所述初始推荐模型,根据所述初始推荐模型输出的第一预测分数、所述第一样本的样本标签以及所述第一样本的样本权重构建第一损失函数;
7、将所述无偏训练集中的第二样本输入无偏推荐模型,根据所述无偏推荐模型输出的第二预测分数以及所述第二样本的样本标签构建第二损失函数;其中,所述无偏推荐模型用于预测输入的样本被用户完整浏览的概率;
8、基于所述第一预测分数以及所述第二预测分数,构建所述无偏推荐模型对所述初始推荐模型的蒸馏损失函数;
9、当所述第一损失函数、所述第二损失函数以及所述蒸馏损失函数均收敛,则确定所述初始推荐模型训练完成,得到目标推荐模型。
10、进一步的,所述基于所述原始训练集的样本属于所述无偏训练集的概率对所述原始训练集的样本进行加权包括:
11、使用所述原始训练集、所述无偏训练集以及训练集中样本的真实标签训练得到二分类判别模型,其中,所述样本的真实标签为样本是否属于所述无偏训练集的标签,所述二分类判别模型用于预测输入的样本属于所述无偏训练集的概率;
12、将所述原始训练集的样本输入训练完成的二分类判别模型,输出样本属于所述无偏训练集的概率;
13、设置所述原始训练集中样本的权重与所述概率成正比,以对所述原始训练集的样本进行加权。
14、进一步的,所述使用所述原始训练集、所述无偏训练集以及训练集中样本的真实标签训练得到二分类判别模型包括:
15、将所述原始训练集以及所述无偏训练集中样本对应的用户特征、样本特征以及样本标签输入初始二分类判别模型;
16、基于所述初始二分类模型输出的样本属于所述无偏训练集的概率,以及所述样本的真实标签,构建二元交叉熵;
17、当所述二元交叉熵收敛,则确定所述初始二分类判别模型训练完成,得到所述二分类判别模型。
18、进一步的,所述初始推荐模型包括:二分类推荐模型;
19、所述将加权后的原始训练集以及加权后的无偏训练集中的第一样本输入所述初始推荐模型,根据所述初始推荐模型输出的第一预测分数、所述第一样本的样本标签以及所述第一样本的样本权重构建第一损失函数包括:
20、将加权后的原始训练集以及加权后的无偏训练集中第一样本的用户特征以及样本特征输入所述二分类推荐模型;
21、基于所述二分类推荐模型输出的第一预测分数、所述第一样本的样本标签以及所述第一样本的样本权重构建二元交叉熵;
22、将所述二元交叉熵作为所述第一损失函数。
23、进一步的,所述无偏推荐模型为二分类预测模型;
24、所述将所述无偏训练集中的第二样本输入无偏推荐模型,根据所述无偏推荐模型输出的第二预测分数以及所述第二样本的样本标签构建第二损失函数包括:
25、将所述无偏训练集中第二样本的用户特征以及样本特征输入所述二分类预测模型;
26、基于所述二分类预测模型输出的第二预测分数以及所述第二样本的样本标签构建二元交叉熵;
27、将所述二元交叉熵作为所述第二损失函数。
28、进一步的,所述基于所述第一预测分数以及所述第二预测分数,构建所述无偏推荐模型对所述初始推荐模型的蒸馏损失函数包括:
29、获取同一样本输入所述初始推荐模型得到的第一预测分数,以及输入所述无偏推荐模型得到的第二预测分数;
30、根据同一样本对应的第一预测分数以及第二预测分数,将第二预测分数作为样本标签,构建二元交叉熵,以使所述无偏推荐模型对所述初始推荐模型进行蒸馏;
31、将所述二元交叉熵作为所述蒸馏损失函数。
32、进一步的,所述当所述第一损失函数、所述第二损失函数以及所述蒸馏损失函数均收敛,则确定所述初始推荐模型训练完成包括:
33、获取所述第一损失函数、所述第二损失函数以及所述蒸馏损失函数的相加之和;
34、当所述相加之和趋于稳定,则确定所述初始推荐模型训练完成。
35、本技术实施例还提供了一种推荐模型,所述推荐模型由根据上述的推荐模型的训练方法训练得到,且所述推荐模型用于输入候选推荐样本,根据所述推荐模型输出的预测分数对所述候选推荐样本进行排序。
36、本技术实施例还提供了一种电子设备,包括:
37、中央处理器,存储器以及输入输出接口;
38、所述存储器为短暂存储存储器或持久存储存储器;
39、所述中央处理器配置为与所述存储器通信,并执行所述存储器中的指令操作以执行上述的方法。
40、本技术实施例还提供了一种计算机可读存储介质,包括指令,当所述指令在计算机上运行时,使得计算机执行如上所述的方法。
41、从以上技术方案可以看出,本技术实施例具有以下优点:
42、本技术实施例包括:获取原始训练集、无偏训练集以及初始推荐模型,其中,原始训练集包括:推荐系统推荐的样本,无偏训练集包括:在推荐系统的候选推荐样本中随机选取的样本,初始推荐模型用于预测输入的样本被用户完整浏览的概率;获取原始训练集以及无偏训练集中样本是否被用户完整浏览的样本标签;对无偏训练集的样本进行加权,并基于原始训练集的样本属于无偏训练集的概率对原始训练集的样本进行加权;将加权后的原始训练集以及加权后的无偏训练集中的第一样本输入所述初始推荐模型,根据初始推荐模型输出的第一预测分数、第一样本的样本标签以及第一样本的样本权重构建第一损失函数;将无偏训练集中的第二样本输入无偏推荐模型,根据无偏推荐模型输出的第二预测分数以及第二样本的样本标签构建第二损失函数;其中,无偏推荐模型用于预测输入的样本被用户完整浏览的概率;基于第一预测分数以及第二预测分数,构建无偏推荐模型对初始推荐模型的蒸馏损失函数;当第一损失函数、第二损失函数以及蒸馏损失函数均收敛,则确定初始推荐模型训练完成,得到目标推荐模型。本技术实施例中,使用无偏训练集训练的无偏模型输出的预测分数对推荐模型进行蒸馏,使推荐模型输出的预测分布接近无偏分布,有效解决了马太效应,且基于推荐模型输出的样本被用户完整浏览的概率构建损失函数,训练推荐模型学习用户完整浏览的样本的样本特征,训练完后,推荐模型输出的预测分数更能够反映用户的真实兴趣,即在解决马太效应同时提高了推荐的精度。
- 还没有人留言评论。精彩留言会获得点赞!