一种文本分类方法
本发明属于文本分类,具体涉及一种文本分类方法。
背景技术:
1、随着科技的进步以及信息时代的到来,伴随着信息、数据的爆炸式增长,人工对数据的标注以及分类愈发显得效率低下,不仅费时费力,而且受技术员主观意识的影响较大。为了提高效率,文本分类模型应运而生,利用计算机以及机器的自动化来实现对文本数据的分类及标注,将枯燥且繁琐的文本标注任务完全交由计算机来进行处理,避免了人的主观意识对结果的影响,产生更可观更可靠的分类结果。
2、一般来说,文本分类分为两大基础结构:特征表示和分类模型。文本特征表示目的是让文本转变为一种可以被计算机处理的形式,常见的方法有n-gram,tf-idf和word2vec等。文本分类模型可分为两类:浅层学习模型和深度学习模型。浅层学习模型是基于传统的机器学习方法,例如朴素贝叶斯,k近邻和支持向量机等。但浅层学习模型通常需要人工提取文本特征,非常耗时且昂贵,而且往往忽略文本数据中自然的顺序结构或上下文信息,使学习词汇的语义信息变得困难。深度学习模型的出现,大量深度学习算法,如循环神经网络和卷积神经网络,被广泛应用于文本分类领域,成功的解决了上述问题。yoonkim等人提出将cnn用于文本分类的textcnn模型,将cnn运用于文本分类取得了不错的表现,但cnn最大的问题就是无法获得更长的序列信息;liu等人提出了将rnn用于文本分类的模型textrnn,可以捕获长距离的依赖关系,解决了textcnn的缺陷,但由于无法进行并行处理,导致模型训练速度过慢。lai等人提出了文本分类模型textrcnn,将卷积层和池化层加入了rnn网络中提升了模型的训练速度,但这类序列学习模型都存在无法获取全局信息。
3、近年来兴起了图神经网络,gnn不将文本看作序列,而是将其视为贡献单词的集合,解决了序列学习模型集中在单词局部,无法获取长距离和非连续的单词交互的问题。在将图神经网络应用在文本分类方向的实践中,yao等人提出了基于图卷积网络的文本分类算法textgcn,将文本分类问题转化为了节点分类问题,提升了文本分类效率,但存在构建文本图时由于边的权重是固定的从而限制了边的表达能力,在构建文本异构图时需要考虑整个语料库从而占用了大量的内存资源的问题。在这个基础上,huang等人提出的text-level-gnn中没有给整个语料库构建大图,而是为每个输入的文本单独构建一个图,并采用消息传播机制来减少内存的消耗,解决了上述模型所具有的问题。与此同时,zhang等人提出了texting模型,通过每个文本中的滑动窗口构建单个图,单词节点信息通过门控神经网络传播到邻居,汇总到文本嵌入,取得良好的效果。william l等人提出了graphsage模型,使用节点之间连接信息,对邻居进行采样,然后通过多层聚合函数不断地将相邻节点的信息融合在一起,用融合后的信息预测节点标签。
4、然而上述方法都没有充分考虑到文本深层次的语义交互,忽略了文本标签之间的相关性,使得预测结果不准确。
技术实现思路
1、为了克服上述现有技术存在的不足,本发明提供了一种文本分类方法。
2、为了实现上述目的,本发明提供如下技术方案:
3、一种文本分类方法,包括:
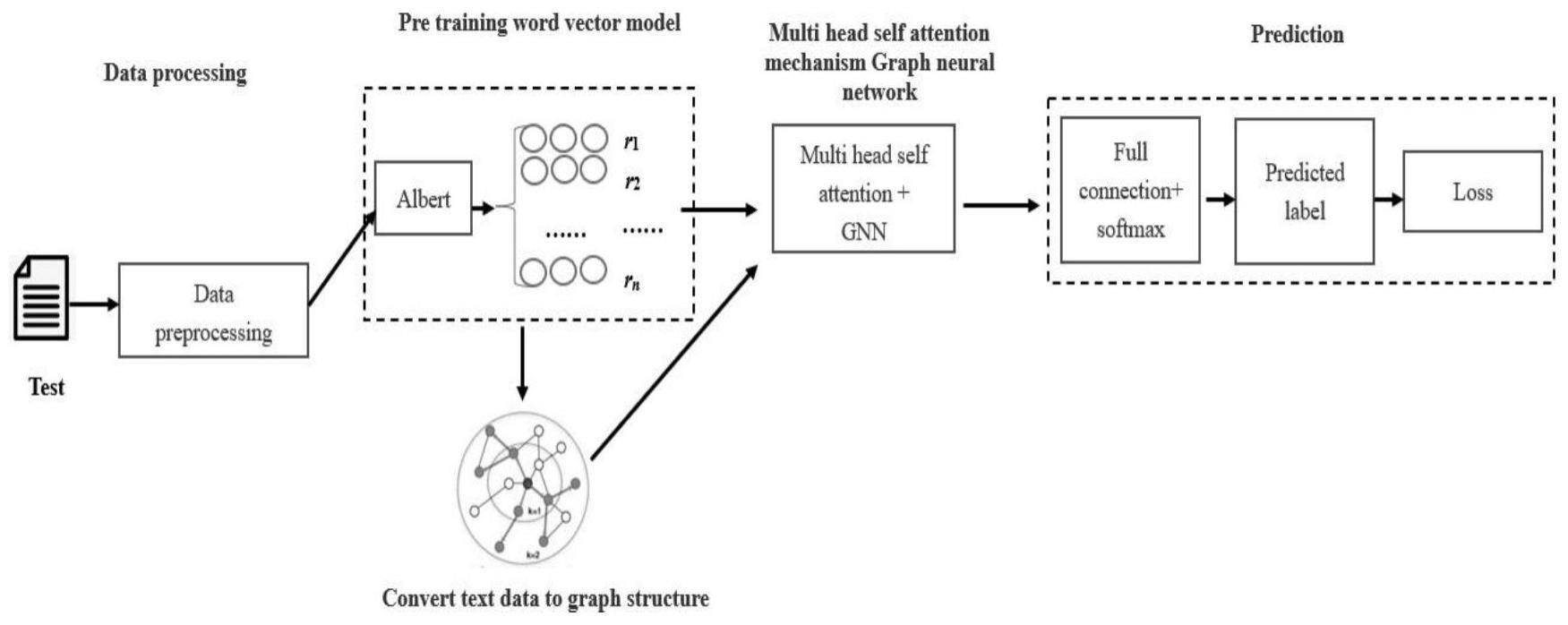
4、获取待分类的文本信息;
5、将文本中的词转化为词向量,并将文本的词向量转化为文本图;
6、将文本图输入到图神经网络中,利用图神经网络输出文本图所对应的标签向量;
7、将文本的词向量输入到多头自注意力神经网络中进行特征提取,输出自注意力特征向量;
8、将自注意力特征向量和标签向量点乘后的结果,输入神经网络的预测层中进行分类得到分类后的预测标签,实现文本分类。
9、进一步,所述将文本中的词转化为词向量,包括:
10、将文本t={t1,t2,……,tn}输入到albert模型的输入表示层中进行编码,输出词嵌入向量位置嵌入向量e0,e2……en和句子特征嵌入向量ea……eb;其中词嵌入表示单词本身的向量表示;位置嵌入是用于区分两个句子的向量表示;句子特征嵌入表示将单词的位置信息编码成的特征向量;
11、将词嵌入向量、位置嵌入向量、句子特征嵌入向量相加后输入到编码器中,利用编码器输出文本的词向量。
12、进一步,所述编码器包括多个堆叠的transformer编码器模块,所述transformer编码器模块包括:
13、串联的注意力机制层、归一化层,线性变换层;
14、所述注意力机制层和归一化层之间设有残差连接。
15、进一步,所述将文本的词向量转化为文本图,包括:
16、将词向量a1作为节点;
17、将词向量a1左边的p个词向量与右边的p个词通过边与词向量a相连,构成词向量a1的文本图。
18、进一步,所述利用图神经网络输出标签向量;包括:
19、对节点进行随机池化和平均池化;
20、根据随机池化和平均池化的结果得到节点最终的特征信息;
21、对迭代t次提取出的节点的特征信息进行求和,得到标签向量mgnn;
22、所述标签向量mgnn为:
23、mgnn={mt+mt+1+……+mt}
24、其中,
25、m=ηmsto+(1-η)mmean
26、
27、
28、其中,msto表示每个节点通过随机池化学习到的特征信息;mmean表示每个节点通过平均池化机制学习到的特征信息;rand函数为规约函数,表示按概率取各个维度上的元素值,元素值越大被取到的概率越大;mean函数表示各个维度上的元素值的平均值;表示文本中距离n节点距离为p的节点的集合;ean表示节点a与节点n之间的边特征;ta表示节点a的特征;m表示每个词最终获得的特征信息;η控制池化操作的比重;t表示图神经网络的迭代次数。
29、进一步,所述将文本的词向量输入到多头自注意力神经网络中进行特征提取,输出自注意力特征向量;包括:
30、词向量v={v1,v2……vn}经过多头自注意力神经网络的嵌入层后被转化为第一词向量a1,a2,a3……an;
31、使用三个权值矩阵wq,wk,wv与第一词向量a1,a2,a3……an相乘,分别得到qi,ki,vi,i∈[1,n];
32、利用q1分别与k1,k2,k3……kn进行点乘计算向量点积,得到q1对应的自注意力分数α11,α12……α1n;
33、分别计算q2,q3……qn的自注意力分数;
34、将q1,q2,q3……qn的自注意力分数拼接得到自注意力分数矩阵α:
35、
36、将自注意力分数矩阵α归一化得到系数矩阵
37、
38、式中,d表示键的维度,表示把注意力矩阵转化为标准正态分布;
39、将系数矩阵分别与对应的vi(i∈[1,n])相乘并求和,得到对应的输出
40、
41、其中,为每个子空间中的自注意力特征向量,表示系数矩阵中第n行i列对应的值,head为头数;
42、将所有的拼接后,将拼接后的结果通过线性转换和softmax激活得到最终的自注意力特征向量bt;
43、
44、进一步,所述自注意力特征向量和标签向量整合后的结果为:
45、
46、其中,mgnn为标签向量,bt为特征向量。
47、进一步,所述分类后的预测标签为:
48、
49、其中,fc表示全连接层,elu表示激活函数,softmax表示分类函数,ypre代表预测标签,为自注意力特征向量和标签向量整合后的结果。
50、进一步,还包括:
51、使用负对数似然损失函数获取预测标签与真实标签的差距,其表达式为:
52、
53、其中yk表示表示真实标签,ypre表示预测标签,log(softmax())表示softmax取对数后的结果。
54、进一步,还包括:将文本转化为文本的词向量之前,对文本进行预处理,包括:
55、删除文本中包含空内容的数据;
56、对文本进行分词;
57、去除文本中的异常值;
58、修建文本中的句子长度并去除停用词,得到预处理后的文本t={t1,t2,……,tn},其中t为词的集合。
59、本发明提供的一种文本分类方法具有以下有益效果:
60、本发明将词向量通过多头自注意力神经网络进行特征提取得到自注意力特征向量,使得词向量具有更深层次的语义交互,再利用图神经网络捕获输入数据各标签之间的重要性,提高重要标签对于预测的影响,之后根据图神经网络和多头自注意力神经网络输出的结果进行文本分类,使得预测过程既考虑了词与词之间的交互关系,又考虑了文本标签之间的相关性,使得预测结果更加准确。
61、解决了现有技术中,没有充分考虑到文本深层次的语义交互,忽略了文本标签之间的相关性,使得预测结果不准确的问题。
- 还没有人留言评论。精彩留言会获得点赞!