一种线上教学问答互动的方法及系统与流程
本发明属于线上教育领域,具体涉及一种线上教学问答互动的方法及系统。
背景技术:
1、近年来,随着互联网、多媒体技术的发展以及手机、平板电脑等终端的普及,线上教育走过了诞生、探索时期,正慢慢走向成熟阶段。在线教育能够打破时间和空间的限制,使学生足不出户就能享受海量教育资源,对传统教育起到了极大的补充作用。同时,相比传统教育,在线教育在课程选课、课程管理、教学方法、成绩评估、学习效率、时间空间、教学资源等方面都具备一定的优势。而且对于一些如人员空间上难以流动、避免人员接触的特殊的场景或时期,线上教学更是有着不可替代的作用。
2、但是,对于当前的线上教育模式,在线上的授课和上课过程中,由于受限于多媒体设备和现有技术,老师与学生难以进行问答互动,这使得线上教育难以还原真实教学场景中的氛围,导致授课过程容易变成单向输出的填鸭式教学模式,其教学效果也将受到很大程度的影响。
技术实现思路
1、针对当前线上教育存在的难点和不足,本发明提出了一种线上教学问答互动的方法及系统。
2、一种线上教学问答互动系统,包括教师系统侧和学生侧,具体地,教师系统侧和学生系统侧都包括图像采集模块、语音采集模块、计算模块和显示模块,其中,所述图像采集模块用于采集图像信号,所述语音采集模块用于采集语音信号,所述计算模块用于数值计算,所述显示模块用于音频、视频和信息显示,
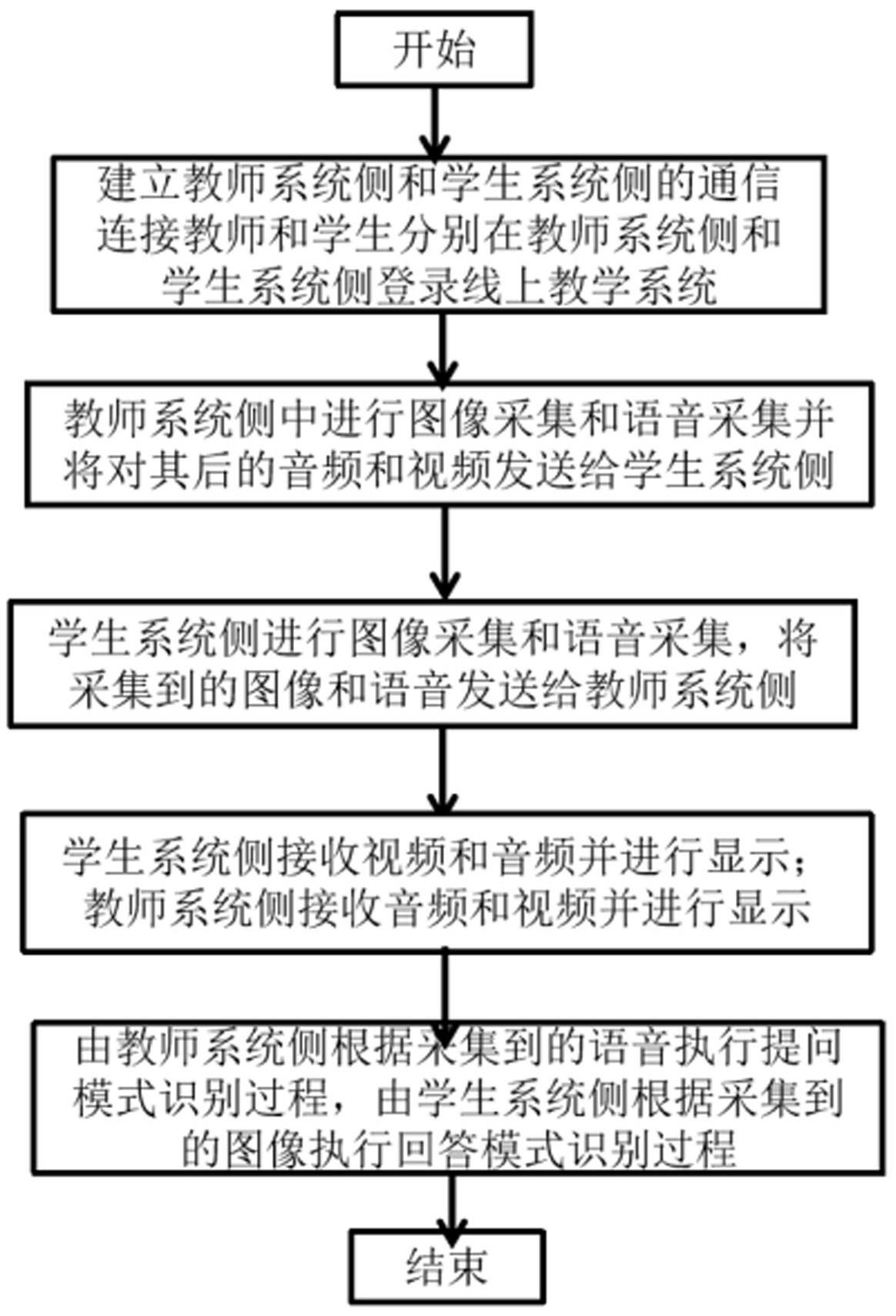
3、一种线上教学问答互动方法,包括步骤:
4、步骤s1,线上教学系统开启并建立教师系统侧和学生系统侧的通信连接,教师和学生分别在教师系统侧和学生系统侧登录线上教学系统;
5、步骤s2,教师系统侧中的图像采集装置和语音采集装置分别对教师进行图像采集和语音采集,并将对其后的音频和视频发送给所述学生系统侧;
6、步骤s3,学生系统侧中的图像采集装置和语音采集装置分别对学生进行图像采集和语音采集,并将对其后的音频和视频发送给所述教师系统侧;
7、步骤s4,所述学生系统侧接收所述教师系统侧发送的视频和音频并进行显示;所述教师系统侧接收所述学生系统侧发送的音频和视频并进行显示;
8、步骤s5,由教师系统侧根据采集到的语音执行提问模式识别过程,由学生系统侧根据采集到的图像执行回答模式识别过程,具体地,
9、提问模式识别过程包括步骤:
10、步骤a1,由教师系统侧内的计算模块对采集到的语音进行语音转文本识别,并根据语音转文本识别的结果来判断该文本是否为提问语句,具体识别过程包括步骤:
11、步骤a101,对采集到的音频进行预处理,具体地,预处理是对音频进行降噪处理,其计算公式为:
12、
13、式中,表示经过特征提取后的带噪音频,表示带噪音频,表示纯净音频,表示噪声音频,i表示时域帧,k表示频点,
14、lstm表示训练得到的神经网络,其训练方式是用学生系统侧播放音频时的背景声进行训练得到,infer_post表示用训练得到的神经网络模型进行推理和后处理过程。
15、步骤a102,对预处理后的音频进行特征提取,即通过语音频谱图将音频信号转为频谱特征,得到特征向量;
16、步骤a103,由声学模型根据声学特性计算每一个特征向量在声学特征上的概率,得到因素信息;
17、步骤a104,由语言模型根据得到的因素信息,获取不同词组序列的概率,
18、步骤a105,对词组序列根据字典进行解码,得到最终文本;
19、其中,判断该文本是否为提问语句具体是根据分类器的输出标签,来判断是否为提问,其计算方式为:
20、
21、式中,表示支持分类器,其训练方式是用“提问”和“非提问”作为标签,用教学中的文本来训练svm支持向量机作为分类器,表示分类器输出为对应标签的概率,表示进行特征提取并进行矩阵表示后的输入文本,表示训练分类器的标签,表示最终输出的标签;
22、如果分类器输出最终为标签“提问”时,则判断该输入文本为提问语句,否则判断该输入文本为非提问语句。
23、步骤a2,如果判断该文本是提问语句,则将语音转文本识别的结果转进行定位和截取,并将截取的文字发送给所述学生系统侧,具体地,
24、当输入文本为提问语句时,则从该文本进行定位,否则跳过该文本并进行下一文本的判断;
25、进一步地,再根据语境判断该文本与上一文本的关联程度,如果上一文本也判断为提问语句,则认为上一文本与该文本存在关联,从而截取该文本和上一文本的文字进行合并和输出,否则只截取该语句文字进行输出。
26、步骤a3,所述学生系统侧接收所述教师系统侧发送的文字,开启定时任务并由学生系统侧的显示模块对接收的文字进行显示;
27、步骤a4,在定时任务内,学生系统侧的图像采集装置按照设定的频率f1(可选地,)对学生进行图像采集,并由采集到的图像进行举手识别,具体识别过程包括步骤:
28、步骤a401,由特征提取网络对输入的图像进行特征提取,具体计算公式为:
29、
30、式中,表示训练得到的特征提取模型,其训练方式是用包含手臂的人员图像进行训练得到,表示输入的图像,w和h分别表示输入图像的宽和高,表示cnn输出的三个尺度的特征图;
31、步骤a402,在特征提取得到的特征图上进行分类和回归预测,得到目标的坐标框信息和类别信息,具体计算公式为:
32、
33、式中,表示特征融合操作,表示特征融合后得到的特征图,表示后处理过程,包括目标框预测、目标分类、阈值处理和非极大值抑制过程,
34、其中,在由特征图进行目标框预测时,是直接在特征图上预测目标的左上角和右下角的坐标,去掉了传统的通过修正先验框的偏移量来进行坐标框的预测过程;
35、分别表示预测的类别和预测的坐标框,和分别表示目标的左上角坐标与右下角坐标;
36、步骤a403,根据得到的手臂坐标信息,由设定的规则判断是否存在举手动作,具体判断规则包括:
37、规则一:检测到手臂且手臂为非水平状态,计算公式为:
38、
39、式中,和分别表示目标的左上角坐标与右下角坐标。
40、规则二:时间大于设定的阈值,计算公式为:
41、
42、式中,表示检测到举手目标后的累计时间,表示设置的阈值;
43、当规则一和规则二同时成立,则认为检测到了举手动作,否则认为没有发生举手动作。
44、步骤a5,如果检测到学生举手动作,则由学生系统侧计算初从定时任务开启到学生举手的具体时间,并将学生的姓名和举手时间发送给教师系统侧。
45、步骤a6,所述教师系统侧接收所有所述学生系统侧发送过来的举手学生姓名和举手时间建立举手学生姓名时间表,按照举手时间从小到大的顺序对举手学生姓名时间表进行排序,并将排序后的结果显示在教师系统侧的显示模块上。
46、回答模式识别过程包括步骤:
47、步骤b1,学生系统侧的图像采集装置按照设定的频率f2(可选地,)对学生进行图像采集,并由采集到的图像进行举手识别,具体识别过程包括步骤:
48、步骤b101,由特征提取网络对输入的图像进行特征提取,具体计算公式为:
49、
50、式中,表示训练得到的特征提取模型,其训练方式是用包含手臂的人员图像进行训练得到,表示输入的图像,w和h分别表示输入图像的宽和高,表示cnn输出的三个尺度的特征图;
51、步骤b102,在特征提取得到的特征图上进行分类和回归预测,得到目标的坐标框信息和类别信息,具体计算公式为:
52、
53、式中,表示特征融合操作,表示特征融合后得到的特征图,表示后处理过程,包括目标框预测、目标分类、阈值处理和非极大值抑制过程,
54、其中,在由特征图进行目标框预测时,是直接在特征图上预测目标的左上角和右下角的坐标,去掉了传统的通过修正先验框的偏移量来进行坐标框的预测过程;
55、分别表示预测的类别和预测的坐标框,和分别表示目标的左上角坐标与右下角坐标;
56、步骤b103,根据得到的手臂坐标信息,由设定的规则判断是否存在举手动作,具体判断规则包括:
57、规则一:检测到手臂且手臂为非水平状态,计算公式为:
58、
59、式中,和分别表示目标的左上角坐标与右下角坐标。
60、规则二:时间大于设定的阈值,计算公式为:
61、
62、式中,表示检测到举手目标后的累计时间,表示设置的阈值;
63、当规则一和规则二同时成立,则认为检测到了举手动作,否则认为没有发生举手动作。
64、步骤b2,如果检测到学生的举手动作,则由学生系统侧的计算模块对采集到的语音进行语音转文本识别,并将语音转文本识别的结果和学生的姓名一起发送给所述教师系统侧,具体识别过程包括步骤:
65、步骤b201,对采集到的音频进行预处理,具体地,预处理是对音频进行降噪处理,其计算公式为:
66、
67、式中,表示经过特征提取后的带噪音频,表示带噪音频,表示纯净音频,表示噪声音频,i表示时域帧,k表示频点,
68、lstm表示训练得到的神经网络,其训练方式是用学生系统侧播放音频时的背景声进行训练得到,infer_post表示用训练得到的神经网络模型进行推理和后处理过程;
69、步骤b202,对预处理后的音频进行特征提取,即通过语音频谱图将音频信号转为频谱特征,得到特征向量;
70、步骤b203,由声学模型根据声学特性计算每一个特征向量在声学特征上的概率,得到因素信息;
71、步骤b204,由语言模型根据得到的因素信息,获取不同词组序列的概率,
72、步骤b205,对词组序列根据字典进行解码,得到最终文本。
73、步骤b3,所述教师系统侧接收所述学生系统侧发送过来的文字和学生的姓名,并由教师系统侧的显示模块对学生的姓名和提问的文字进行显示。
74、本发明提出了一种线上教学问答互动的方法及系统,与现有的技术相比,具有以下有益效果:
75、本发明针对当前线上教育模式下,老师和学生存在难以问答互动的难点,提出了在音频视频传输的基础上,分别以语音算法模块和视觉算法模块来进行提问模式和回答模式的识别,实现了线上教学场景中自动识别老师的提问场景和学生的问答场景,解决了当前线上教育系统因多终端输出存在的多屏共存、多音源播放而导致的难以进行教学问答互动的问题。
76、本发明提供的系统和方法,在视觉算法进行目标检测的基础上,提出了举手动作的识别方法,为后续的提问模式和问答模式提供了依据。
77、本发明提供的系统和方法,根据实际线上教学场景中存在多音源播放而导致语音识别算法存在干扰的问题,提出了训练深度学习网络拟合环境噪声来来对音频进行降噪处理,能够有效地去除线上教学环境因为音频播放导致的干扰,从而提高算法识别的准确率。
78、本发明考虑到实际应用场景中,其终端设备算力存在不足,提出了一种去掉先验眶的检测算法来进行目标检测,有效地提高了算法的推理速度,实现了举手动作的检测算法能够在一些互联网终端产品上的快速推理。
79、本发明提供的系统和方法,在语音识别的基础上,提出了训练分类器来进行问题语句和非问题语句的识别,在小计算量的前提下实现了问题语句和非问题语句的定位,能够为后续问题语句的定位和截取提供依据。
80、本发明提供的系统和方法,在问题语句和非问题语句的基础上,提出了问题语句的定位和截取的方法,并对问题语句进行文字显示,使得线上教育过程中的问答互动更加直观和生动。
- 还没有人留言评论。精彩留言会获得点赞!