预测前列腺癌风险分层的非线性变换集成学习模型和方法
本发明属于临床数据处理、数据分析、机器学习和stacking集成学习,具体涉及预测前列腺癌风险分层的非线性变换集成学习模型和方法。
背景技术:
1、前列腺癌(pca)是全世界男性中第二常见的癌症。pca的发病率和死亡率随着男性年龄的增长而增加。对于pca患者,基于穿刺活检的病理组织检查是诊断的金标准。在几乎所有与pca相关的研究中,gleason评分(gs)是pca最重要的预测因素之一。一般来说,pca风险分层是根据血清前列腺特异性抗原(psa)、gs和一系列临床指标来评估的,将pca分为低、中、高风险,以指导临床医生的治疗和预后判断。不同的风险分层,pca患者的治疗方法也有很大差异。例如,极低和低风险患者采用主动监测,中等风险患者采用根治性治疗,高风险和转移性患者采用基于adt(雄激素剥夺治疗)的综合治疗。显然,对pca患者不适当的风险评估将可能会导致严重的心理问题和经济损失。因此,开发一种非侵入性的方法来有效、准确地确定pca患者的良性和恶性,并预测其风险分层是非常必要的。
2、目前pca风险分层工作大致分为基于临床记录的传统机器学习(ml)方法和基于临床记录和医学图像的多模态数据的深度学习方法。2019年,hoodet等利用遗传算法(ga)和统计测试(stat)算法从32个临床特征中选出8个特征来构建特征子集。并将三个k-近邻(knn)模型进行组合,实现了pca的恶性分类和低中/高风险二分类的预测。2021年,liang等人基于多参数放射学模型和临床-放射学联合模型,在预测pca恶性程度方面取得了良好的表现。然而,这些研究使用了相对较小的临床数据集,并且没有进行风险三分层的预测和验证。
3、近年来,集成学习方法在机器学习算法中得到了广泛应用,特别是在提高特定疾病诊断系统的可靠性和准确性方面取得了显著进展。集成学习是一种将多个弱学习器组合成一个强学习器的方法,通过将多个不同的机器学习算法或同一算法的不同变体进行组合。集成学习可以有效地提高模型的鲁棒性和泛化能力。在临床决诊断工具的开发中,集成学习方法可以用于构建多个模型,并将它们的预测结果进行整合,从而得到更可靠和准确的诊断结果。例如,在前列腺癌的辅助检测和良恶性分析中,可以使用集成学习方法来整合多种特征提取方法和分类算法,以提高前列腺癌的风险分层准确性。
4、尽管现有集成学习在前列腺癌风险分层的预测问题上取得了较大进展,但集成学习方法的准确性并没有完全满足临床需求。模型性能存在一些不足,为了应对这一挑战,我们开发一种性能优异,基于非线性变换算法池和特征拼接的stacking集成策略,以帮助前列腺患者进行无创诊断和风险分层评估。
技术实现思路
1、本发明要解决的技术问题是:提供预测前列腺癌风险分层的非线性变换集成学习模型和方法,用于提升预测前列腺癌低中高风险分层的机器学习模型的性能。
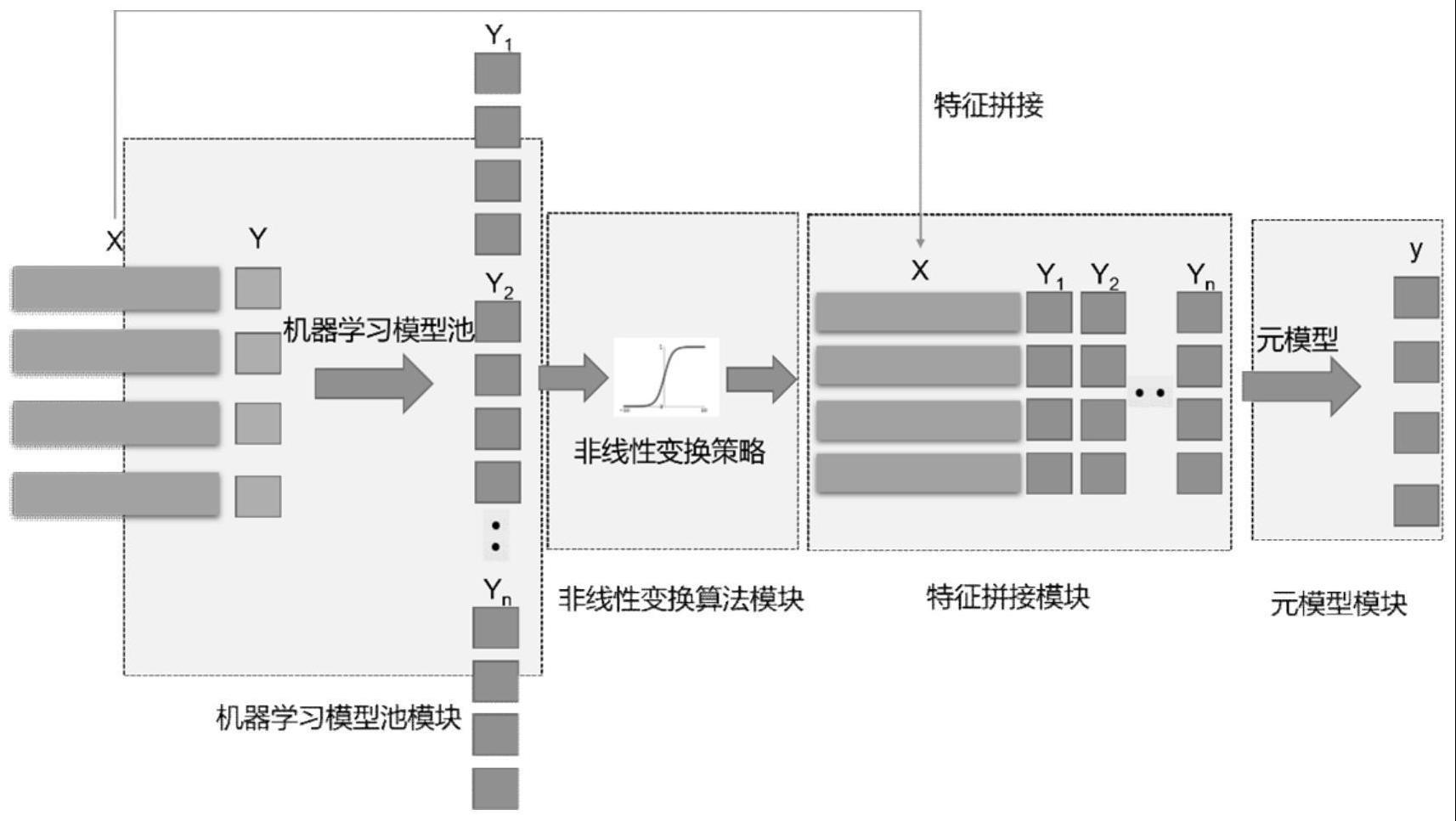
2、本发明为解决上述技术问题所采取的技术方案为:预测前列腺癌风险分层的非线性变换集成学习模型,包括依次连接的机器学习模型池模块、非线性变换算法池模块、特征拼接模块和元模型模块;机器学习模型池模块用于使用多种机器学习模型学习原始的临床数据;非线性变换算法池模块用于对多种机器学习模型的预测结果进行非线性变换;特征拼接模块用于拼接非线性变换后的特征与原始的临床数据,并构建新的数据集;元模型模块用于将不同的机器学习模型作为元模型,学习特征拼接模块得到的数据集,从而验证不同的机器学习模型作为元模型的性能。
3、按上述方案,机器学习模型池模块包括支持向量机、决策树、随机森林、xgboost和逻辑回归的多种机器学习模型;机器学习模型池模块用于采用10折交叉验证方法在包括多个特征的临床数据集中进行训练,用训练好的模型对数据集的每个样本进行风险分层概率的预测,并保存相应的预测结果。
4、进一步的,非线性变换算法模块根据多种机器学习模型的预测结果构建,用于将多个机器学习模型对每个样本的预测结果作为新的特征,将这些特征经过非线性变换函数得到非线性变换后的特征。
5、进一步的,非线性变换函数包括余弦函数cosine function、高斯误差线性单元gaussian error linear units、类s型函数sigmoid、正弦函数sine function、softplus函数and双曲正切函数hyperbolic tangent function;非线性变换算法模块还用于结合元模型模块进行性能评估后自动筛选出最优的非线性变换函数。
6、进一步的,特征拼接模块用于将非线性变换后的特征与输入机器学习模型池模块的原始的临床特征拼接起来构建新数据集;设i为患者数量,j为临床特征数量,k为模型池中的模型数量;x(i,j)代表原始临床数据,为模型池的预测结果,为非线性变换函数,则新数据集x(i,k+j)的构建公式如下:
7、
8、进一步的,元模型模块用于将新数据集输入到机器学习模型池模块中筛选性能最优的机器学习模型作为元模型,并支持使用roc曲线对提出的元模型的性能进行展示。
9、预测前列腺癌风险分层的非线性变换集成学习方法,包括以下步骤:
10、s1:构建机器学习模型池,将多个原始的临床特征组成的数据集输入到模型池中不同的机器学习模型进行训练,并保存训练好的机器学习模型的预测结果;
11、s2:构建非线性变换算法池,对机器学习模型的预测结果进行多种非线性变换的策略生成非线性变换的特征;
12、s3:将多个原始的临床特征与非线性变换的特征拼接生成新的训练数据集;
13、s4:在基于新的数据集训练生成不同的元模型中,选择性能最优的机器学习模型作为元模型的性能。
14、进一步的,还包括以下步骤:
15、采用包括roc曲线的方式评估非线性变换集成学习模型的性能。
16、一种计算机存储介质,其内存储有可被计算机处理器执行的计算机程序,该计算机程序执行预测前列腺癌风险分层的非线性变换集成学习方法。
17、本发明的有益效果为:
18、1.本发明的预测前列腺癌风险分层的非线性变换集成学习模型和方法,通过构建结合机器学习、非线性变换策略和特征拼接的stacking集成学习模型来预测前列腺癌的低中高风险分层,实现了提升预测前列腺癌低中高风险分层的机器学习模型的性能的功能。
19、2.非线性变换与特征拼接能够增加特征的多样性,并且stacking集成方法能够提升机器学习模型性能,本发明通过采用非线性变换的stacking集成方法能够有效地预测前列腺癌的风险分层,为医生提供更精准的诊断和治疗建议,从而改善前列腺癌患者的生活质量。
技术特征:
1.预测前列腺癌风险分层的非线性变换集成学习模型,其特征在于:包括依次连接的机器学习模型池模块、非线性变换算法池模块、特征拼接模块和元模型模块;机器学习模型池模块用于使用多种机器学习模型学习原始的临床数据;
2.根据权利要求1所述的预测前列腺癌风险分层的非线性变换集成学习模型,其特征在于:
3.根据权利要求2所述的预测前列腺癌风险分层的非线性变换集成学习模型,其特征在于:
4.根据权利要求3所述的预测前列腺癌风险分层的非线性变换集成学习模型,其特征在于:
5.根据权利要求3所述的预测前列腺癌风险分层的非线性变换集成学习模型,其特征在于:
6.根据权利要求5所述的预测前列腺癌风险分层的非线性变换集成学习模型,其特征在于:
7.用于权利要求1至6中任意一项所述的预测前列腺癌风险分层的非线性变换集成学习模型的非线性变换集成学习方法,其特征在于:包括以下步骤:
8.根据权利要求7所述的非线性变换集成学习方法,其特征在于:还包括以下步骤:
9.一种计算机存储介质,其特征在于:其内存储有可被计算机处理器执行的计算机程序,该计算机程序执行如权利要求7至权利要求8中任意一项所述的预测前列腺癌风险分层的非线性变换集成学习方法。
技术总结
本发明提供了预测前列腺癌风险分层的非线性变换集成学习模型和方法,通过构建结合机器学习、非线性变换策略和特征拼接的Stacking集成学习模型来预测前列腺癌的低中高风险分层,实现了提升预测前列腺癌低中高风险分层的机器学习模型的性能的功能。非线性变换与特征拼接能够增加特征的多样性,并且Stacking集成方法能够提升机器学习模型性能,本发明通过采用非线性变换的Stacking集成方法能够有效地预测前列腺癌的风险分层,为医生提供更精准的诊断和治疗建议,从而改善前列腺癌患者的生活质量。
技术研发人员:吴兴隆,方银,曹新宇,姜炎,宋文博,徐国平
受保护的技术使用者:武汉工程大学
技术研发日:
技术公布日:2024/1/16
- 还没有人留言评论。精彩留言会获得点赞!