一种基于大语言模型的人机协同方法及装置与流程
本发明涉及自然语音处理,具体而言,涉及一种基于大语言模型的人机协同方法及装置。
背景技术:
1、目前,语音客服可以分为三类拨打模式:纯人工外呼模式、纯机器人外呼模式和人机协同外呼模式。其中:人机协同外呼模式综合了前两种模式的优点,既能够保证拨打效率又能对高意向客户进行高质量的营销和服务。在人机协同外呼模式中,先通过语音机器人给用户拨打电话,如果用户在与语音机器人交互的过程中表现出高意向,则转接给人工坐席。显然,在这种模式中如何自动判断合适的通话和转接时机尤为重要。
2、现有的自动判断转接时机的方案有:
3、方案一、根据语音机器人播报节点,配置转接规则。比如:播报完成某段录音(意向筛选)后或者介绍来意后,如果用户没有挂机则进行转接。
4、方案二、根据用户意图,配置转接规则。具体可以利用文本分类模型,对于用户的回复进行分类,如果命中正向意图,则进行转接。
5、方案三、根据转接转化率预估模型的预测结果,配置阈值。比如,对话进行到某一轮,预估模型的预测结果为此时转接到人工座席的转化率为5%,超过设定阈值4%,则发生转接。
6、以上方案判断出的转接时机都不够精准,比如:在前两种方案中,命中同一个节点的客户、命中同一个意图的客户很多,但是意向程度不同,如果按照前两种方案配置转接规则,没有办法对于单条规则下的客户进行细分。而在第三种方案,配置的阈值是固定的,比如4%,但是实际通话中,即使某一轮对话得到了一个高分预估结果5%,但是如果此时不进行转接,在未来的通话中可能出现某个轮次更加适合转接,预估授信率可能达到10%。显然,这种方案无法判断用户的最优转接轮次。
技术实现思路
1、有鉴于此,本发明主要目的在于提出一种基于大语言模型的人机协同方法及装置,以期至少部分地解决上述技术问题中的至少之一。
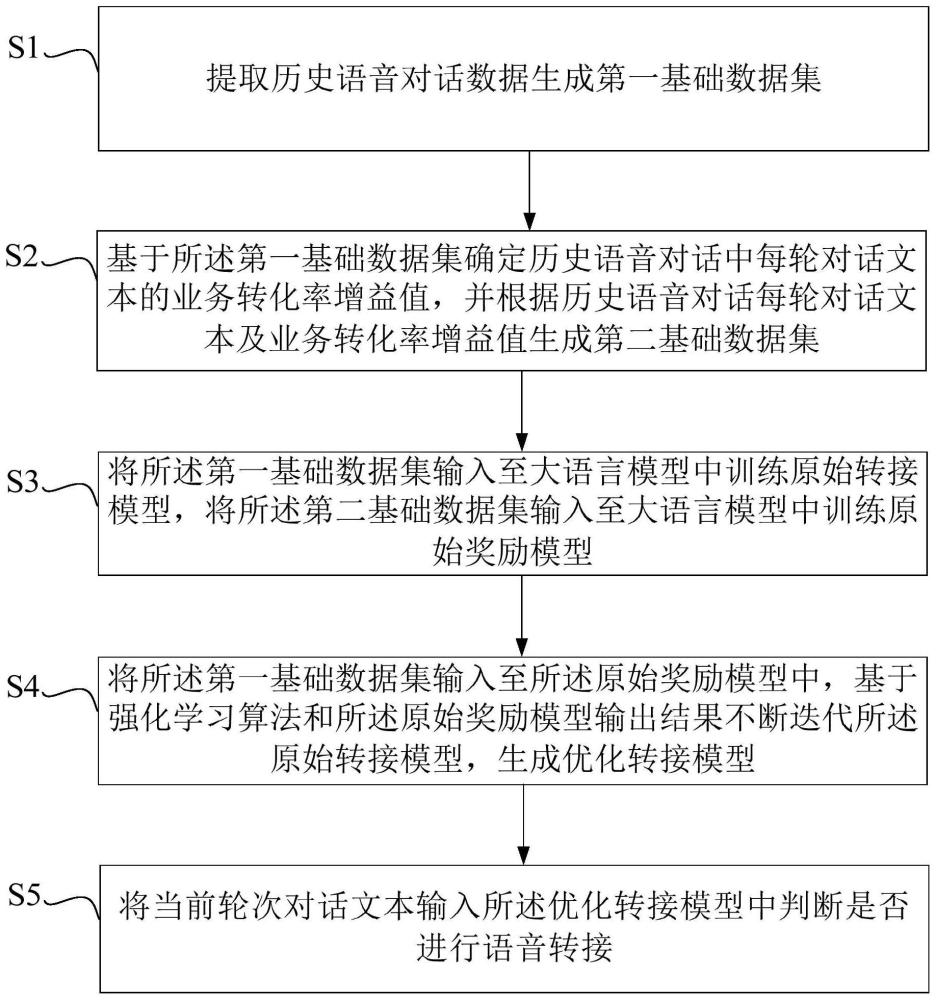
2、为了解决上述技术问题,本发明第一方面提出一种基于大语言模型的人机协同方法,所述方法包括:
3、提取历史语音对话数据生成第一基础数据集;
4、基于所述第一基础数据集确定历史语音对话中每轮对话文本的业务转化率增益值,并根据历史语音对话每轮对话文本及业务转化率增益值生成第二基础数据集;
5、将所述第一基础数据集输入至大语言模型中训练原始转接模型,将所述第二基础数据集输入至大语言模型中训练原始奖励模型;
6、将所述第一基础数据集输入至所述原始奖励模型中,基于强化学习算法和所述原始奖励模型输出结果不断迭代所述原始转接模型,生成优化转接模型;
7、将当前轮次对话文本输入所述优化转接模型中判断是否转接至人工座席。
8、根据本发明一种优选实施方式,所述基于所述第一基础数据集确定历史语音对话每轮对话文本的业务转化率增益值包括:
9、根据所述第一基础数据集中的转接标签元素将所述第一基础数据集分为转接数据子集和未转接数据子集;
10、基于所述转接数据子集和未转接数据子集确定历史语音对话每轮对话文本的业务转化率增益值。
11、根据本发明一种优选实施方式,所述基于所述转接数据子集和未转接数据子集确定历史语音对话每轮对话文本的业务转化率增益值包括:
12、通过转接数据子集训练第一预估模型,并通过未转接数据子集训练第二预估模型;
13、将历史语音对话每轮对话文本分别输入第一预估模型和第二预估模型,并根据第一预估模型和第二预估模型的输出结果确定历史语音对话每轮对话文本的业务转化率增益值。
14、根据本发明一种优选实施方式,所述基于所述第一基础数据集确定历史语音对话每轮对话文本的业务转化率增益值包括:
15、将第一基础数据集中的历史语音对话每轮对话文本元素及转接标签元素作为输入特征,业务转化标签作为训练标签训练综合预估模型;
16、将历史语音对话每轮对话文本分两次输入所述综合预估模型,分别得到第一预测结果和第二预测结果;
17、根据所述第一预测结果和第二预测结果确定历史语音对话每轮对话文本的业务转化率增益值。
18、根据本发明一种优选实施方式,所述将所述第一基础数据集输入至所述原始奖励模型中,基于强化学习算法和所述原始奖励模型输出结果不断迭代所述原始转接模型,生成优化转接模型包括:
19、生成步骤:将第一基础数据集中历史语音对话的多轮对话文本序列输入原始转接模型,生成转接人工座席的概率分布;
20、采样步骤:在所述概率分布中采样历史语音对话的多轮对话文本序列,并将采样序列中的每轮对话文本输入至原始奖励模型,得到积累的业务转化率增益值;
21、更新步骤:根据积累的业务转化率增益值和强化学习算法更新原始转接模型,生成优化转接模型;
22、判断步骤:判断更新后的优化转接模型是否符合优化标准,若符合,则停止优化,若不符合,返回依次执行采样步骤、更新步骤和判断步骤。
23、根据本发明一种优选实施方式,所述更新步骤包括:
24、判断积累的业务转化率增益值是否大于阈值;
25、若大于,通过策略梯度算法更新原始转接模型的参数,得到优化转接模型;
26、若小于,调整原始转接模型的参数,得到优化转接模型。
27、根据本发明一种优选实施方式,所述在所述概率分布中采样历史语音对话的多轮对话文本序列包括:
28、在所述概率分布中随机采集预定个数的历史语音对话的多轮对话文本序列;
29、或者,预先给不同的样本赋予不同的被采出来的权重,在所述概率分布中根据权重采集历史语音对话的多轮对话文本序列。
30、为解决上述技术问题,本发明第二方面提供一种基于大语言模型的人机协同装置,所述装置包括:
31、提取模块,用于提取历史语音对话数据生成第一基础数据集;
32、生成模块,用于基于所述第一基础数据集确定历史语音对话中每轮对话文本的业务转化率增益值,并根据历史语音对话每轮对话文本及业务转化率增益值生成第二基础数据集;
33、训练模块,用于将所述第一基础数据集输入至大语言模型中训练原始转接模型,将所述第二基础数据集输入至大语言模型中训练原始奖励模型;
34、优化模块,用于将所述第一基础数据集输入至所述原始奖励模型中,基于强化学习算法和所述原始奖励模型输出结果不断迭代所述原始转接模型,生成优化转接模型;
35、判断模块,用于将当前轮次对话文本输入所述优化转接模型中判断是否转接至人工座席。
36、根据本发明一种优选实施方式,所述生成模块包括:
37、划分模块,用于根据所述第一基础数据集中的转接标签元素将所述第一基础数据集分为转接数据子集和未转接数据子集;
38、确定模块,用于基于所述转接数据子集和未转接数据子集确定历史语音对话每轮对话文本的业务转化率增益值。
39、根据本发明一种优选实施方式,所述确定模块包括:
40、第一子训练模块,用于通过转接数据子集训练第一预估模型,并通过未转接数据子集训练第二预估模型;
41、第一子确定模块,用于将历史语音对话每轮对话文本分别输入第一预估模型和第二预估模型,并根据第一预估模型和第二预估模型的输出结果确定历史语音对话每轮对话文本的业务转化率增益值。
42、根据本发明一种优选实施方式,所述生成模块包括:
43、第二子训练模块,用于将第一基础数据集中的历史语音对话每轮对话文本元素及转接标签元素作为输入特征,业务转化标签作为训练标签训练综合预估模型;
44、子输入模块,用于将历史语音对话每轮对话文本分两次输入所述综合预估模型,分别得到第一预测结果和第二预测结果;
45、第二子确定模块,用于根据所述第一预测结果和第二预测结果确定历史语音对话每轮对话文本的业务转化率增益值。
46、根据本发明一种优选实施方式,所述优化模块包括:
47、子生成模块,用于将第一基础数据集中历史语音对话的多轮对话文本序列输入原始转接模型,生成转接人工座席的概率分布;
48、采样模块,用于在所述概率分布中采样历史语音对话的多轮对话文本序列,并将采样序列中的每轮对话文本输入至原始奖励模型,得到积累的业务转化率增益值;
49、更新模块,用于根据积累的业务转化率增益值和强化学习算法更新原始转接模型,生成优化转接模型;
50、第一子判断模块,用于判断更新后的优化转接模型是否符合优化标准,若符合,则停止优化,若不符合,返回依次执行采样步骤、更新步骤和判断步骤。
51、根据本发明一种优选实施方式,所述更新模块包括:
52、第二子判断模块,用于判断积累的业务转化率增益值是否大于阈值;
53、子优化模块,用于若大于,通过强化学习算法更新原始转接模型的参数,得到优化转接模型;若小于,调整原始转接模型的参数,得到优化转接模型。
54、根据本发明一种优选实施方式,所述采样模块在所述概率分布中随机采集预定个数的历史语音对话的多轮对话文本序列;或者,所述采样模块预先给不同的样本赋予不同的被采出来的权重,在所述概率分布中根据权重采集历史语音对话的多轮对话文本序列。
55、综上所述,本发明运用大语言模型在生成式任务上优势,将是否转人工座席作为一个决策过程,基于大语言模型对多轮对话文本序列建模,根据历史语音对话的业务转化率增益值构建原始奖励模型,根据历史语音对话的转化结果构建原始转接模型,并基于两个模型迭代学习实现原始转接模型的优化,优化后的优化转接模型可以在每轮对话结束后动态决策是否转接人工座席。相较于现有技术中在每个话术节点配置固定的转接规则或转接阈值,本发明可以根据用户单轮次的对话动态判断转接时机,实现对用户最优转接轮次的判断,节约人工座席成本的同时提高转化率。
- 还没有人留言评论。精彩留言会获得点赞!