一种考虑机器均衡负载的混合流水车间智能排产方法
本发明涉及车间生产计划管理,特别提供改进灰狼算法规划混合流水车间排产问题。
背景技术:
1、目前传统制造业企业为追求更高的竞争力,纷纷开始数字化转型与智能化升级。智能排产是制造企业实现数字化、柔性化、智能化生产的核心,也是满足客户个性化、定制化、多样化需求的基础,而高效的排产方法有助于提升企业生产效率,降低成本。本文考虑的混合流水车间排产模型是典型的np-hard问题,包含多条并行的流水线,不同阶段的并行机不同,同一工件在不同机器的加工时间也不同,更符合制造企业排产实际情况。本文以所有机器最小化最大负载为目标函数,保证生产过程中机器的负载均衡,从而保证高效的持续生产能力。
2、求解混合流水车间模型的方法主要包括精确式方法、群智能算法。传统精确式算法能够保证排产结果的最优,通过精确的规划排产来减少成本。而随着排产规模的增加,精确式算法的响应能力难以满足大规模排产快速响应的需求,进而影响排产效率。群智能算法是受自然生物的群体行为启发而发明的算法,旨在通过有限次迭代得到接近更优的解,从而在一定范围内快速搜索出接近最优值的解。灰狼算法结构简单、控制参数较少,但存在搜索后期种群多样性差、收敛速度慢、易陷入局部最优等缺点,同时灰狼算法是为解决连续问题而提出,在求解排产调度等离散性问题上存在局限性。
技术实现思路
1、本发明为了解决上述现有技术存在的不足之处,提出一种考虑机器均衡负载的混合流水车间智能排产方法,以期能保证搜索过程中种群多样性,提升算法后期搜索效率,从而能更符合现实排产中快速响应需求,提高排产效率,减少时间成本;并能有效避免部分机器长时间高负载运转,以提升机器持续运行能力。
2、本发明为达到上述发明目的,采用如下技术方案:
3、本发明一种考虑机器均衡负载的混合流水车间智能排产方法的特点在于,是按照如下步骤进行:
4、步骤1、获取待加工工件集合,记为j={j1,j2,…,jn,…,jn},jn表示第n个工件,n表示工件数量;获取每个工序加工的并行机器集合,记为m={m1,…,mi,…,mi},mi表示第i道工序下的并行机器集合,且mik表示第i道工序下的第k台并行机器,i表示工序数量,ki表示第i道工序下的并行机器数量;令on={on1,…,oni,…,oni}表示加工第n个工件jn的工序集;oni表示加工第n个工件jn所对应的第i道工序,记录每个工件在对应并行机器的加工时间为t={t111,…,tnik,…,tnik},tnik表示第n个工件jn的第i道工序在第k台并行机器上加工的时间;令所有工件的完工时间集合为c={c1,c2,…,cn,…,cn},其中,cn表示第n个工件jn的完工时间;k表示所有机器的数量,且
5、步骤2、构建混合流水车间的排产模型;
6、步骤2.2.1、利用式(1)构建排产模型的目标函数l:
7、min l=max{l1,l2,…,lh,…,lk} (1)
8、式(1)中,lh为第h台并行机器mh的总加工时间,且其中,xnik表示决策变量,若第n个工件jn的第i道工序下在第k台并行机器上加工,则令xnik为1,否则,令xnik为0;
9、步骤2.2.2、利用式(2)-式(6)构建排产模型的约束条件:
10、snik+ynipqk×b≥epqk (2)
11、spqk+(1-ynipqk)×b≥enik (3)
12、sn(i+1)k≥eniu (4)
13、
14、enik=snik+tnik (6)
15、式(2)和式(3)表示同一时刻一台并行机器只能加工一个工件的一道工序;其中,ynipqk表示决策变量,若在第k台并行机器上加工第n个工件jn所对应的第i道工序oni先于加工第p个工件jp所对应的第q道工序opq加工,则令ynipqk=1,否则,令ynipqk=0;snik表示在第k台并行机器上加工第n个工件jn所对应的第i道工序oni的开始时间,enik表示在第k台并行机器上加工第n个工件jn所对应的第i道工序oni的结束时间,spqk表示在第k台并行机器上加工第p个工件jp所对应的第q道工序opq的开始时间,epqk表示在第k台并行机器上加工第p个工件jp所对应的第q道工序opq的结束时间,b表示无穷大的数;
16、式(4)表示同一工件只有前一道工序完成后才能开始加工下一道工序;其中,sn(i+1)k表示在第k台并行机器上加工第n个工件jn所对应的第i+1道工序on(i+1)的开始时间,eniu表示在第u台并行机器上加工第n个工件jn所对应的第i道工序oni的结束时间;
17、式(5)表示每道工序只能选择并行机器中的一台进行加工;
18、式(6)表示加工开始时间与结束时间的关系;
19、步骤2.2.3、构建两个排产规则:
20、第一排产规则:优先选择负载小的并行机器;若完成上一道工序的加工后,在选择下一道工序加工的并行机器时,选择最小负载的闲置并行机器加工工件;
21、第二排产规则:优先选择加工时间小的并行机器;若完成上一道工序的加工后,在选择下一道工序加工的并行机器时,选择加工时间最小的闲置并行机器加工工件;
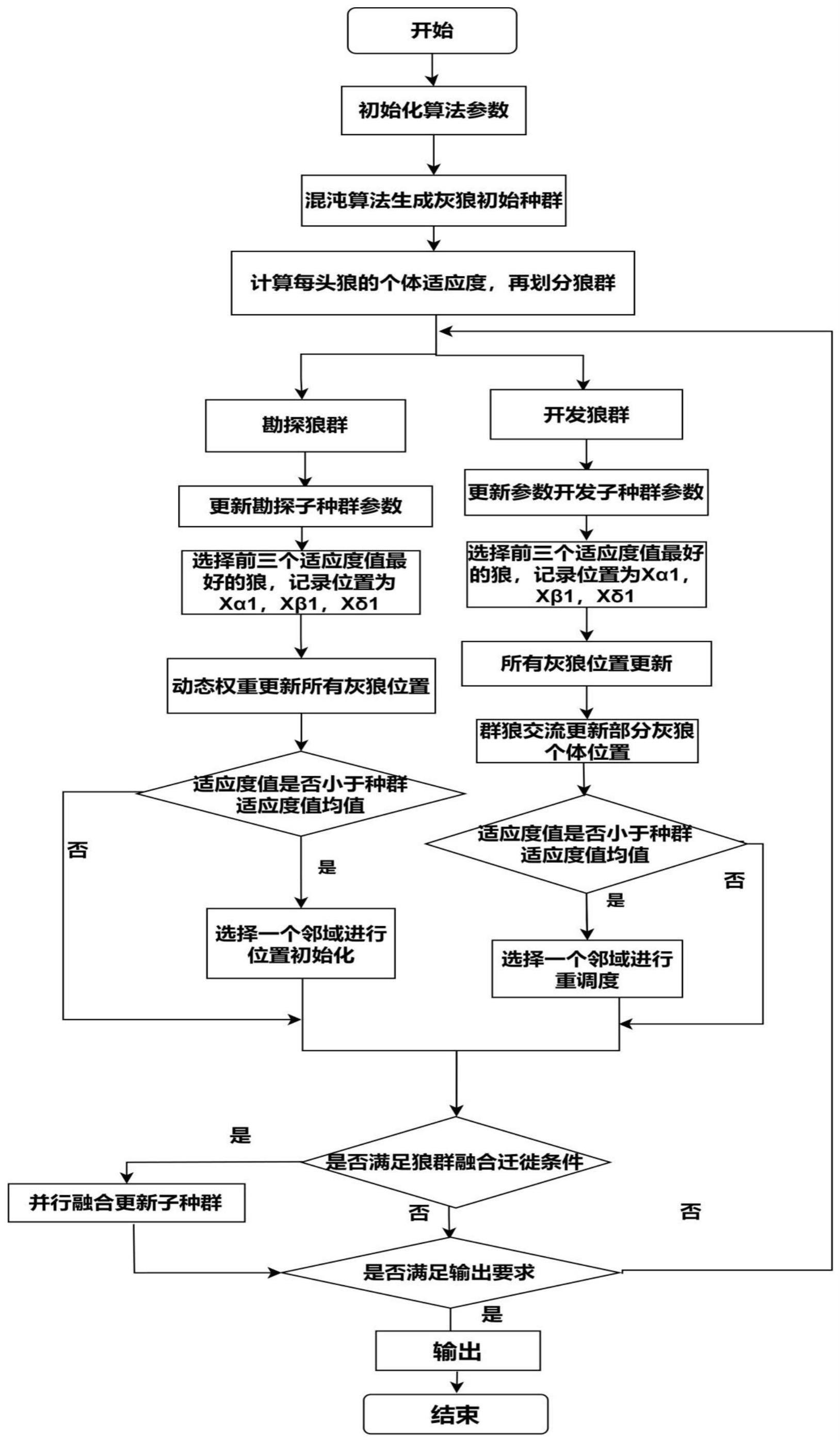
22、步骤3、按照两个排产规则,利用改进的灰狼算法对排产模型进行求解;
23、步骤3.1、参数初始化:当前迭代次数为t,并初始化t=1,定义最大迭代次数为max_t;定义倍数τ,并初始化τ=1;
24、步骤3.2、利用改进的bernouilli shift映射法生成位置向量,并对位置向量进行解码以获取第t代的第s个排产方案;
25、步骤3.3、根据并行融合机制划分第t代勘探种群、第t代开发种群;
26、步骤3.4、将第t代勘探种群中适应度值最小、次小、第三小的灰狼个体作为第t代勘探种群的三个领导狼,记为α1狼、β1狼、δ1狼,并将第t代勘探种群中的三个领导狼的位置向量分别记为
27、通过动态权重机制更新第t代勘探种群,得到初步更新后的第t代勘探种群;
28、若初步更新后的第t代勘探种群中灰狼个体的适应度值小于初步更新后的第t代勘探种群适应度值的均值,则采取轮盘赌法选择一种位置初始化法对初步更新后的第t代勘探种群中当前灰狼个体的位置向量进行更新,否则,保持当前灰狼个体的位置向量不变,从而得到最终更新后的第t代勘探种群;
29、步骤3.5、将第t代开发种群中适应度值最小、次小、第三小的灰狼个体作为第t代开发种群的三个领导狼,记为α2狼、β2狼、δ2狼,并将第t代开发种群中的三个领导狼的位置向量分别记为
30、通过领导狼的位置引导更新第t代开发种群,得到初步更新后的第t代开发种群,再利用群狼交流机制进一步更新,得到再次更新后的第t代开发种群;
31、若再次更新后的第t代开发种群中灰狼个体适应度值小于再次更新后的第t代开发种群适应度值的均值,则采取轮盘赌法选择一种邻域搜索方法对再次更新后的第t代开发种群中灰狼个体位置向量进行重调度,否则保持当前灰狼个体的位置向量不变,从而得到最终更新后的第t代开发种群;
32、步骤3.6、判断t=τ×δ是否成立,若成立,则将τ+1赋值给τ,并将第t代勘探狼群和第t代开发狼群整合成一个第t代种群,再返回步骤3.3顺序执行,否则,执行步骤3.7;其中,δ表示局部迭代阈值;
33、步骤3.7、取第t代勘探种群中的α1狼与第t代开发种群中的α2狼中较小适应度值作为第t代的局部最优应度值,当t=1时,将第t代的局部最优值即为全局最优适应度值;当t≥2时,将第t代的局部最优适应度值与全局最优适应度值进行比较,若第t代的局部最优适应度值更优,则第t代的局部最优适应度值赋值给全局最优适应度值,否则,全局最优适应度值不变;
34、步骤3.8、判断t=max_t是否成立,若成立,则将全局最优适应度值所对应的灰狼个体作为最优排产方案,否则,将t+1赋值给t后,返回步骤3.4顺序执行。
35、本发明所述的考虑机器均衡负载的混合流水车间智能排产方法的特点也在于,所述步骤3.2包括:
36、步骤3.2.1、利用式(7)生成第t代种群中第s个灰狼个体的位置向量从而生成第t代种群中2s个灰狼个体的位置向量
37、
38、式(7)中,λ表示映射调整参数;表示经过bernouilli shift映射得到的第t代种群中第s个灰狼个体的第n+1个位置标量,表示第t代种群中第s个灰狼个体的第n个位置标量,当n=1时,令为(0,1)中的随机数;
39、步骤3.2.2、在混沌映射中,若或m表示位置向量的序号,且m={0,1,2,3,4},则采取式(8)对进行扰动,使重新进入混沌;
40、
41、式(8)中,mod表示取余,rand(0,1)表示生成(0,1)的随机数;
42、步骤3.2.3、采取rov规则与排产规则对位置向量进行解码,得到第t代的第s个排产方案。
43、所述步骤3.2.3包括:
44、步骤3.2.3.1、对中的位置标量进行升序排序,并根据排序的序号对中各个位置标量的取值进行赋值,从而得到第一道工序的工件加工顺序;
45、步骤3.2.3.2、在第二道工序至最后一道工序中,对于每个完成上一道工序生产的工件,先根据所述第一排产规则选择并行机器进行排产,若不存在最小机器负载,则根据所述第二排产规则选择并行机器进行排产。
46、所述步骤3.3包括:
47、步骤3.3.1、计算第t代种群中每个灰狼个体的目标函数l并作为其适应度值,再按照适应度值的降序对第t代种群中每个灰狼个体进行排序,得到排序后的第t代种群,其对应的适应度值记为其中,表示排序后的第t代种群中第i个灰狼个体的适应度值;s第表示t代勘探种群或开发种群中的灰狼个体数量;
48、步骤3.3.2、将排序后的第t代种群间隔划分成第t代勘探种群和第t代开发种群其中,表示第t代勘探种群中第e1个灰狼个体的适应度值,表示第t代开发种群中第e2个灰狼个体的适应度值。
49、所述步骤3.4中的动态权重机制包括:
50、步骤3.4.1、将第t代勘探种群的α1狼、β1狼、δ1狼中的任意一个领导狼记为第u1个领导狼,并根据记录的位置向量计算每个领导狼的适应度值;
51、步骤3.4.2、对第u1个领导狼的适应度值的倒数进行归一化后,得到第t代勘探种群中第u1个领导狼的归一化适应度值
52、步骤3.4.3、利用式(9)计算第t代勘探种群中第u1个领导狼的熵值
53、
54、步骤3.4.4、利用式(10)计算第t代勘探种群中第u1个领导狼的权重
55、
56、步骤3.4.5、定义第t代勘探种群的递减参数为a1,并初始化a1=2,定义第t代勘探种群中第一勘探种群随机向量为a11、第二勘探种群随机向量为a12、第三勘探种群随机向量为a13、第一勘探种群调整向量为c11、第二勘探种群调整向量为c12、第三勘探种群调整向量为c13,并初始化a11、a12、a13、c11、c12、c13为0;
57、步骤3.4.6、利用式(11)更新第u1个勘探种群随机向量a1,u1,得到更新后的第u1个勘探种群随机向量a'1,u1:
58、a'1,u1=2a1·r1-a1 (11)
59、式(11)中,r1是(0,1)的随机数;
60、步骤3.4.6、利用式(12)更新第u1个勘探种群调整向量c1,u1,得到更新后的第u1个勘探种群调整向量c'1,u1:
61、c'1,u1=2·r2 (12)
62、式(12)中,r2是(0,1)的随机数;
63、步骤3.4.7、利用式(13)更新a1,得到更新后的勘探种群递减参数a'1:
64、
65、步骤3.4.8、利用式(14)计算第t代勘探种群中第u1个领导狼到猎物之间的距离向量
66、
67、式(14)中,表示第t代勘探种群中第u1个领导狼的位置向量,表示第t代勘探种群中第e1个灰狼个体的位置向量;
68、步骤3.4.9、利用式(15)得到第t代勘探种群中第e1个灰狼个体更新的位置向量
69、
70、步骤3.4.10、采取rov规则和排产规则对位置向量进行解码,获取第t代的第e1个排产方案;并分别计算和的适应度值,若的适应度值更优,则赋值给否则,保持不变;
71、步骤3.4.11、按照步骤3.4.6-步骤3.4.10的过程,对第t代勘探种群中的每个灰狼个体进行处理,从而得到初步更新后的第t代勘探种群。
72、所述步骤3.4中的位置初始化法包括四种:
73、第一种位置初始化法为:随机初始化第t代勘探种群中第e1个灰狼个体的位置向量;每个位置向量的各个维度均随机生成(0,1)之间的随机数并替代原始的位置向量;
74、第二种位置初始化法为:利用式(16)更新第t代勘探种群中第e1个灰狼个体的位置向量从而得到更新后的位置向量
75、
76、式(16)中,ra为(0,1)的随机数;
77、第三种位置初始化法为:利用式(17)更新第t代勘探种群中第e1个灰狼个体的位置向量从而得到更新后的位置向量
78、
79、式(17)中,rb为(0,1)的随机数;
80、第四种位置初始化法为:利用式(18)更新第t代勘探种群中第e1个灰狼个体的位置向量从而得到更新后的位置向量
81、
82、式(18)中,rc为(0,1)的随机数。
83、所述步骤3.5包括:
84、步骤3.5.1、定义第t代开发种群的递减参数为a2,并初始化a2=2,定义第一开发种群随机向量为a21、第二开发种群随机向量为a22、第三开发种群随机向量为a23、第一开发种群调整向量为c21、第二开发种群调整向量为c22、第三开发种群调整向量为c23,并初始化a21、a22、a23、c21、c22、c23为0;
85、步骤3.5.2、利用式(19)更新第u2个开发种群随机向量a2,u2,得到更新后的第u2个开发种群随机向量a'2,u2:
86、a'2,u2=2a2·r3-a2 (19)
87、式(19)中,r3是(0,1)的随机数;
88、步骤3.5.3、利用式(20)更新第u2个开发种群调整向量c2,u2,得到更新后的第u2个开发种群调整向量c'2,u2:
89、c'2,u2=2·r4 (20)
90、式(20)中,r4是(0,1)的随机数;
91、步骤3.5.4、利用式(21)更新a2,得到更新后的勘探种群递减参数a'2:
92、
93、步骤3.5.5、利用式(22)计算第t代开发种群中第u2个领导狼到猎物之间的距离向量
94、
95、式(14)中,表示第t代开发种群中第u2个领导狼的位置向量,表示第t代开发种群中第e2个灰狼个体的位置向量;
96、步骤3.5.6、利用式(23)得到第t代开发种群中第e2个灰狼个体更新的位置向量
97、
98、步骤3.5.7、采取rov规则和排产规则对位置向量进行解码,获取第t代的第e2个排产方案;并分别计算和的适应度值,若的适应度值更优,则赋值给否则,保持不变;
99、步骤3.5.8、按照步骤3.5.2到步骤3.5.7的过程,对第t代开发种群中每个灰狼个体进行更新,得到初步更新后的第t代开发种群;
100、步骤3.5.8、依据群狼交流机制对初步更新后的第t代开发种群进行更新;
101、步骤3.5.8.1、按照适应度值的降序对初步更新后的第t代开发种群中的狼群个体进行排列,找到适应度值的中位数的狼群个体,从而将初步更新后的第t代开发狼群分为两组狼群,且两组狼群的数量相差小于等于1;
102、步骤3.5.8.2、根据式(24)确定第t代开发种群中狼群个体的更新总次数d:
103、
104、式(24)中,dmin,dmax分别表示交流更新比例最小值和最大值,表示向下取整操作;
105、步骤3.5.8.3、在当前次更新下,从两组狼群中各随机选择一个狼群个体,并利用式(25)对适应度值较差的狼群个体进行移动,得到适应度值较差的狼群个体更新后的位置向量
106、
107、式(25)中,表示在当前次更新下,从两组狼群中选各择一个狼群个体中适应度值较优狼群个体的位置向量,表示适应度值较差狼群个体的位置向量;r5表示(0,1)的随机数;
108、步骤3.5.8.4、按照步骤3.5.8.3的过程执行d次,从而得到再次更新后的第t代开发种群。
109、所述步骤3.5中的邻域搜索方法包括两种:
110、第一种邻域搜索方法为:从再次更新后的第t代开发种群中随机选择一个位置向量的三个元素进行顺序打乱后,得到打乱后的位置向量;计算打乱前、后的位置向量的适应度值,若打乱后的适应度值优于打乱前的适应度值,则将打乱前的位置向量替换为打乱后的位置向量,否则,保持打乱前的位置向量不变;
111、第二种邻域搜索方法为:从再次更新后的第t代开发种群中随机选择一个位置向量,并按照奇偶位置将位置向量中的位置标量分为两组,并分别打乱两组位置标量内部各自的顺序,再按照奇偶位置将打乱后的两组位置标量合并后,得到打乱后的位置向量;计算打乱前、后的位置向量的适应度值,若打乱后的适应度值优于打乱前的适应度值,则将打乱前的位置向量替换为打乱后的位置向量,否则,保持打乱前的位置向量不变。
112、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述混合流水车间智能排产方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
113、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述混合流水车间智能排产方法的步骤。
114、与现有技术相比,本发明的有益效果在于:
115、1、本发明将改进的灰狼算法用于求解混合流水车间排产问题,能够应用到制造企业大规模排产问题的求解,算法以最小化最大机器负载为目标,并在工件选择机器底层机制考虑机器负载,使工件优先选择机器负载小的机器进行加工,从而求解出负载均衡的排产方案,更符合生产实际,也有利于企业持续高效生产。
116、2、本发明通过多种群机制融入灰狼优化算法,将原算法的单个种群划分为两个子种群,通过狼群迁徙机制增强两个子种群间的信息交流,保证两个子种群中都存在较优的排产方案以及多样化的非较优排产方案,通过两个子种群的独立搜索机制和较优排产方案的引导,进一步增强算法整体能搜索到最优排产方案的能力。
117、3、本发明对灰狼算法的种群更新机制与勘探机制进行改进,通过动态权重更新机制保证新排产方案与较优排产方案有更高的相似度,并对适应度值较差的个体进行重新初始化,保持种群中较差排产方案的多样性,有效防止了搜索过程中候选排产方案高度重合,从而导致难以搜索到更优的排产方案。
118、4、本发明对灰狼算法的开发机制进行改进,结合开发种群的群狼交流、邻域重调度机制,增强子种群开发潜在更优排产方案的能力,开发更新机制简洁,生成新排产方案效率高,有利于算法快速迭代更新,减少了生成最优排产方案时间,从而更快获得机器负载更为均衡的排产方案。
- 还没有人留言评论。精彩留言会获得点赞!