跨平台与跨组织的驾驶风险识别方法与系统与流程
本技术涉及车辆行驶风险技术,具体地,涉及对跨平台与跨组织的不同车组的行驶风险识别方法与系统。
背景技术:
1、随着车辆联网服务的普及,以adas(advanced driving assistance system,高级驾驶辅助系统)为代表的车联网设备种类更加丰富。车联网设备能在车辆行驶过程中实时采集多种行驶数据,并基于采集数据与报警配置信息做出报警。车辆网设备做出的报警为向指定的接收方传输具有与报警配置信息相关含义的信息。
2、但目前对车联网设备没有统一的规范标准,体现为各地政策、硬件设备和用户设置的差异。各地交通部相继出台车载终端技术规范,明确设备报警参数区间,其中江苏省发布最早,但具体报警参数由制造厂商和使用者在规范区间内自行设定。此外不同地区出台的规范略有差异,作为举例,表1列举了苏标和陕标中各项报警参数的定义。
3、表1苏标、陕标对比表
4、
5、
6、
7、各家硬件制造厂商的报警配置信息也有不同,体现为报警类型和报警触发条件的差异。此外用户可根据实际需求自行设置报警触发条件,加大了不同用户车队之间的报警差异。表2对比展示了市场上a、b、c三家公司的设备设置。
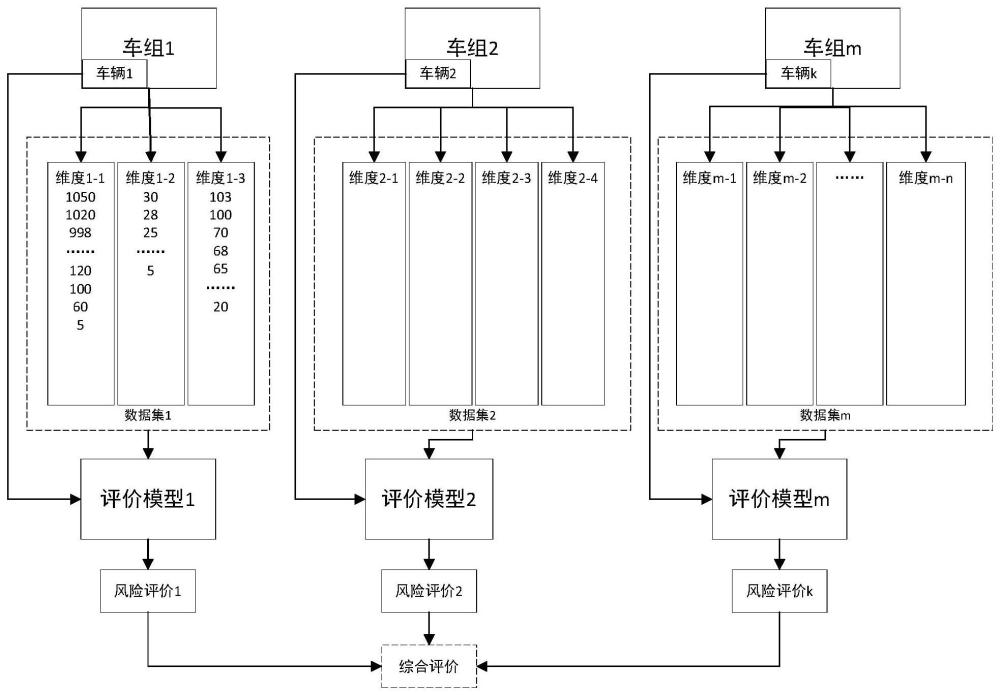
8、由于车联网硬件设备无统一规范,各地区各车队采购不同厂商的车联网设备,甚至单一车队内部署了来自不同厂家的不同车联网设备,各车辆可能使用了不同的车联网设备报警配置,导致采集的车联网报警数据存在特征差异。部署了车联网设备的车辆通常属于不同的单位或组织,为了清楚的目的,将属于相同单位或组织的车辆集合称为车队;而将采用了相同的车联网设备并配置了相同的报警配置信息的车辆集合称为车组。
9、
10、
11、
技术实现思路
1、基于车联网设备与报警配置信息,解决了对车辆个体在行驶过程中的风险事件识别问题。例如,能够识别车速过快、车距过近、疲劳驾驶等风险事件。对于车组,其采用相同的车联网设备与报警配置信息,使得对车组内的不同车辆的报警结果是统一的,从而能一定程度在长时间范围内基于报警结果来评价车组内的不同车辆,以识别风险事件的累积效应,例如估计车辆寿命、预测车辆行驶风险、识别不良驾驶行为、评价驾驶技能、制定保险费率等。这些评价一方面需要在时间上累积各车辆报警结果,另一方面也需要在各车辆的统计数据之间进行比较,从而识别出哪些车辆相对于其他车辆存在更高的安全隐患,或者哪些驾驶员相对于其他驾驶员拥有更好的驾驶技能。
2、然而,对于车队,其车辆可能属于不同车组,从而其使用了不同的车联网设备和/或报警配置信息。这种情况下,在长时间范围内累积的报警结果对于车队的各车辆或各车组缺乏比较意义。例如,对于车辆d1与d2,d1在1个月内出现超速报警10次,而车辆d2在1个月内出现超速报警15次,然而当车辆d1与d2的超速报警触发条件不同、两车车型或工作场景不同时,10次与15次的数值比较并不能有效反应两车的驾驶风险。而车联网设备给出的报警事件种类(参看表1与表2)有数十乃至上百种,这进一步加剧了在时间上累积各车辆报警结果在各车辆、车组之间缺乏比较意义,进而在识别风险事件的累积效应中无法得到准确或有意义结果的问题。基于类似的理由,在车队之间也无法识别、比较或评价风险事件的累积效应,例如无法识别出哪个车队相对于其他车队存在更高的安全隐患,也无法识别出车队的安全隐患随时间变化情况。
3、车联网设备厂商尝试提供互联网平台来基于自身的硬件车联网设备提供车辆行驶数据采集、存储查询与报警等服务。然而由于不同车联网设备之间的报警配置信息的多样性,使得难以有效依据多种车联网设备的数据来识别和比较部署了不同车联网设备的车辆的行驶风险差异。
4、为解决上述问题,根据本技术实施例提供了跨平台与跨组织的驾驶风险识别方法。平台代表车联网设备和/或数据采集平台,组织代表制定报警配置信息的车队和/或车组。通过探索不同的驾驶风险评价模型,建立统一的评估标准,实现不同车队车辆间的驾驶风险评价值直接可比。根据本技术第一方面,提供了根据本技术第一方面的第一跨平台与跨组织的驾驶风险识别方法,包括:获取多个车辆的行驶数据作为样本构造第一类数据集,其中提供构成同一个第一类数据集的多个样本的多个车辆具有相同的车联网设备与报警配置信息,车辆利用其具有的车联网设备与报警配置信息生成行驶数据,样本包括多个维度;根据第一类数据集的每个,构造多个第一类数据序列,第一类数据序列包括多个元素,第一类数据序列具有维度使得第一类数据序列对应于第一类数据集的样本的多个维度之一,第一类数据序列的多个元素分别来自第一类数据集的多个样本之一;对多个第一类数据序列的每个按其包括的元素进行排序,剔除排序在最前和/或最后的指定数量的元素,并将排序后的每个第一类数据序列的元素映射到指定区间并进行归一化来更新所述多个第一类数据序列,其中通过建立每个第一类数据序列各自的元素的取值范围到所述指定区间的线性映射将每个第一类数据序列的元素映射到指定区间;对多个第一类数据序列的每个计算其信息熵;根据多个第一类数据序列的每个的信息熵在所述多个第一类数据序列的信息熵之和中的占比,得到所述多个第一类数据序列的每个的权重;对于每个第一类数据集,用其所有第一类数据序列各自的所述线性映射以及其所有第一类数据序列各自的权重形成的权重序列,构造其驾驶风险评价模型;获取待识别驾驶风险的第一车辆的第一行驶数据作为待识别样本;获取与所述第一车辆对应的第一类数据集所对应的第一驾驶风险评价模型;用第一驾驶风险评价模型的线性映射将所述第一行驶数据的各维度数据映射为多个单维度得分,将所述多个单维度得分根据所述第一驾驶风险评价模型的权重序列加权求和,得到所述第一行驶数据的驾驶风险评价值;根据所述第一行驶数据的驾驶风险评价值生成所述第一车辆的驾驶风险。
5、根据本技术第一方面,提供了根据本技术第一方面的第二跨平台与跨组织的驾驶风险识别方法,其中,驾驶风险评价模型的线性映射被表达为yi=max_score-(xi-ai)*bi,其中i用于索引第一类数据集的样本的多个维度之一,x代表第一类数据集的样本,xi代表样本的由i索引的维度的数据,ai是第一类数据集的由i索引的排序后的第一类数据序列的元素的下限值,bi=max_score/(upi-downi),upi是第一类数据集的由i索引的排序后的第一类数据序列的元素的上限值,downi=ai,max_score为单维度评分的最大值。
6、根据本技术第一方面,提供了根据本技术第一方面的第三跨平台与跨组织的驾驶风险识别方法,其中,驾驶风险评价模型被表达为z=∑βiyi,其中z代表由驾驶风险评价模型得到的驾驶风险评价值,βi是第一类数据集的由i索引的第一类数据序列的权重。
7、根据本技术第一方面,提供了根据本技术第一方面的第四跨平台与跨组织的驾驶风险识别方法,其中,所述指定区间是从0到max_score的区间;以及其中所述将所述第一行驶数据的各维度数据映射为多个单维度得分,包括将所述第一行驶数据的小于downi的维度数据映射的单维度得分为0,将所述第一行驶数据的大于upi的维度数据映射的单维度得分为max_score。
8、根据本技术第一方面,提供了根据本技术第一方面的第五跨平台与跨组织的驾驶风险识别方法,其中,所述对多个第一类数据序列的每个计算其信息熵,包括:对于每个第一类数据序列,计算其各元素yij所对应的指标占比其中j为第一类数据序列中元素的索引,ni为由i索引的第一类数据序列中元素的个数;对于每个第一类数据序列,计算其信息熵对于每个第一类数据序列,计算其权重其中m为第一类数据集的维度数。
9、根据本技术第一方面,提供了根据本技术第一方面的第六跨平台与跨组织的驾驶风险识别方法,还包括:用多个第一类数据集构造第二类数据集,其中所述多个第一类数据集各自的多个维度分别相同,以及其中通过将各第一类数据集的相同维度的第一类数据序列合并得到第二类数据集,第二类数据集包括多个第二类数据序列;对第二类数据集的各第二类数据序列,按其包括的元素进行排序,并对排序后的每个第二类数据序列的元素映射到指定区间并进行归一化来更新第二类数据集的第二类数据序列,其中通过建立每个第二类数据序列各自的元素的取值范围到所述指定区间的线性映射将每个第二类数据序列的元素映射到指定区间;对多个第二类数据序列的每个计算其信息熵;根据多个第二类数据序列的每个的信息熵在所述多个第二类数据序列的信息熵之和中的占比,得到所述多个第二类数据序列的每个的权重;对于第二类数据集,用其所有第二类数据序列各自的所述线性映射以及其所有第二类数据序列各自的权重形成的权重序列,构造第二驾驶风险评价模型;获取待识别驾驶风险的第二车辆的第二行驶数据作为待识别样本;获取与所述第二车辆对应的第二类数据集所对应的第二驾驶风险评价模型;用第二驾驶风险评价模型的线性映射将所述第二行驶数据的各维度数据映射为多个单维度得分,将多个单维度得分根据所述第二驾驶风险评价模型的权重序列加权求和,得到所述第二行驶数据的驾驶风险评价值。
10、根据本技术第一方面,提供了根据本技术第一方面的第七跨平台与跨组织的驾驶风险识别方法,还包括:利用多个第一类数据集的每个所对应的第一驾驶风险评价模型,对构成每个第一类数据集的样本计算其驾驶风险评价值;用对应每个第一类数据集的样本的驾驶风险评价值序列构造第三类数据集;对第三类数据集的每个驾驶风险评价值序列计算其信息熵;根据第三类数据集的每个驾驶风险评价值序列的信息熵在第三类数据集的所有驾驶风险评价值序列的信息熵之和中的占比,得到第三类数据集的每个驾驶风险评价值序列的权重;对于第三类数据集,用第三类数据集的每个驾驶风险评价值序列的权重形成的权重序列,构造第三驾驶风险评价模型;将所述第一行驶数据的驾驶风险评价值与所述第一车辆对应的第一类数据集在所述第三类数据集中对应的权重相乘,得到所述第一行驶数据的综合驾驶风险评价值;根据所述第一行驶数据的综合驾驶风险评价值生成所述第一车辆的驾驶风险。
11、根据本技术第一方面,提供了根据本技术第一方面的第八跨平台与跨组织的驾驶风险识别方法,还包括:利用多个第一类数据集的多个相同报警事件维度分别构造多个第四类数据集,每个第四类数据集包括来自所述多个第一类数据集的每个的第四类数据序列,每个第四类数据集的所有第四类数据序列各自对应同一个相同报警事件维度;对每个第四类数据集的每个第四类数据序列计算其信息熵;根据每个第四数据集的每个第四类数据序列的信息熵在该第四类数据集的所有第四类数据序列的信息熵之和中的占比,得到每个第四类数据集的每个第四类数据序列的权重;利用第一驾驶风险评价模型与每个第四类数据集的每个第四类数据序列的权重,构造第四驾驶风险评价模型,其中所述第四驾驶风险评价模型包括与每个第一类数据集和每个相同报警事件维度对应的权重;所述第一行驶数据的所述多个单维度得分与来自所述第一驾驶风险评价模型的权重序列以及来自所述第四驾驶风险评价模型的权重序列加权求和,得到所述第一行驶数据的综合驾驶风险评价值;其中来自所述第四驾驶风险评价模型的权重序列加权包括所述第四驾驶风险评价模型中与所述第一车辆对应的第一类数据集以及所有相同报警事件维度对应的权重;根据所述第一行驶数据的综合驾驶风险评价值生成所述第一车辆的驾驶风险。
12、根据本技术第一方面,提供了根据本技术第一方面的第九跨平台与跨组织的驾驶风险识别方法,其中,所述第四驾驶风险评价模型被表达为szk=∑γi′kβki′yki′,其中k用于索引所述第一驾驶风险评价模型对应的第一类数据集,szk代表由所述第四驾驶风险评价模型得到的综合驾驶风险评价值,i′是所述第一行驶数据中各维度的索引,βki′是由k索引的第一类数据集的由i′索引的第一类数据序列的权重,yki′是由k索引的第一类数据集的由i′索引的单维度得分,γi′k是所述第四驾驶风险评价模型中与由k索引的第一类数据集和由i′索引的相同报警事件维度对应的权重。
13、提供了根据本技术第二方面的信息处理设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的程序,其特征在于,所述处理器执行所述程序时实现根据本技术第一方面的跨平台与跨组织的驾驶风险识别方法之一。
- 还没有人留言评论。精彩留言会获得点赞!