基于行人穿越意图预测网络的行人穿越意图预测方法
本发明涉及轨迹预测领域,具体涉及一种基于行人穿越意图预测网络的行人穿越意图预测方法。
背景技术:
1、行人作为vulnerable road users(vrus),其在道路上的安全尤为重要,全球道路死亡人数已达到每年135万人,这个数据最近几年不断攀升,其中近一半的交通事故受害者是vrus。排除因为车辆技术原因导致的车祸,大部分行人的伤亡是因为驾驶员或者智能设备无法准确预测行人的穿越意图以及无法做出及时的反应。因此如何精准并且快速地预测行人的穿越意图在保护行人的生命安全方面尤为重要。得益于行人检测领域的快速发展,交通领域越来越多的研究深入到行人穿越预测任务以期保护行人安全。
2、近些年的工作,从各个方面逐渐提升了行人穿越预测的准确度。早期工作为了提高预测的准确度,使用图片帧序列、单帧静态图片和人体姿势等单一模态数据进行行人穿越预测。部分研究通过增加不同模态的交通场景数据例如行人检测框、人体姿势、网格图片以及语义分割等信息提高预测的效果。另一部分研究选择精细地设计网络结构例如各种注意力机制、场景关系建模以及视觉信息提取。
3、最近的工作在预测行人穿越任务上解决了许多问题,并显著地提高了预测效果,但依然存在以下问题:(1)使用单一模态数据对行人穿越进行预测,没有考虑到交通场景等其他信息对行人穿越意图的影响;(2)部分研究通过改进网络结构来增加多模态数据进行提高模型预测效果,不仅提高模型过拟合风险而且需要耗费大量的计算资源,导致预测的实时性较差;(3)行人穿越预测的输入特征以时间序列形式为主,上述工作直接使用循环神经网络提取各种模态数据在时间维度上的信息,因此使用了大量的线性层极易造成过拟合导致预测效果不佳;(4)人体姿势数据同时包含了时间维度信息和空间结构信息,直接使用循环神经网络处理人体姿势丢失了人体空间结构信息,无法挖掘深层次的行人时空动作信息,因而使用了数据泛化、数据增强等方法加强模型对特征的学习。使用额外的技术虽然能提升模型所学特征的泛化性和显著性,但是对数据的原始特征做出了未知的改变,增加了模型预测结果的不确定性。
技术实现思路
1、本发明要解决的技术问题是克服现有技术的缺陷,提供一种基于行人穿越意图预测网络的行人穿越意图预测方法,它可以在交通场景中快速准确地预测行人穿越行为。
2、为了解决上述技术问题,本发明的技术方案是:一种基于行人穿越意图预测网络的行人穿越意图预测方法,包括:
3、构建行人穿越意图预测网络,并训练;
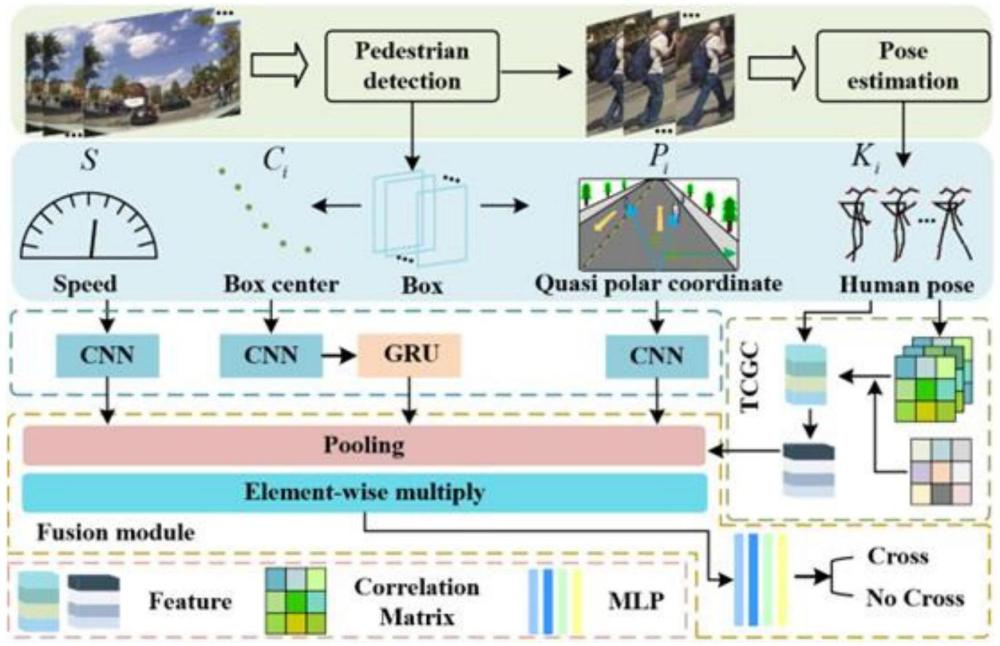
4、获取自车速度s、行人i的人体姿势ki、行人i在自车视角中的人体检测框中心点位置ci以及行人i在自车视角中的类极坐标pi;
5、利用所述行人穿越意图预测网络,预测行人穿越意图;其中,所述预测行人穿越意图步骤,包括:
6、基于自车速度s,获取自车速度特征fs;
7、基于行人i的人体姿势ki,获取行人i的动作特征
8、基于行人i在自车视角中的人体检测框中心点位置ci,获取行人i在自车视角中的人体检测框中心位置在时间维度上的特征
9、基于行人i在自车视角中的类极坐标pi,获取行人i在自车视角中的类极坐标特征
10、按照通道维度分别对特征fs、及进行全局池化,并按元素相乘,得到多模态融合后的行人意图特征
11、基于所述行人意图特征得到行人穿越预测结果。
12、进一步,所述基于自车速度s,获取自车速度特征fs,包括:
13、使用一维卷积聚合自车速度s邻域时间内的特征,得到自车速度特征fs,具体公式为:
14、fs=view(conv1d1(s;w1))
15、其中,view表示特征维度变换;w1是一维卷积conv1d1的参数;s∈rt×1;fs∈rc×t′;c表示特征维度;t表示时间维度;t′表示经过时间卷积后的时间维度。
16、进一步,所述基于行人i的人体姿势ki,获取行人i的动作特征包括:
17、所述基于行人i的人体姿势ki,获取行人i的动作特征包括:
18、sa,行人i的人体姿势ki分别经过线性转换函数φ和进行转换,并计算差值,然后以非线性函数激活差值作为和之间的联系值γ,具体公式为:
19、
20、其中,σ表示激活函数;wφ和分别表示线性转换函数φ和的参数;和表示t时刻行人i的第m和第n个关键点的坐标;ki∈rt×n×c;t表示时间维度;n表示关键点数量;c表示特征维度;
21、sb,人体各个时刻任两个关键点之间的联系值γ集合为xγ∈rt×n×n,t表示时间维度,n表示关键点数量;
22、sc,聚合时间维度上关键点之间的联系值xγ的全局变化得到的最终的拓扑增强结构部分的矩阵adje,具体公式为:
23、adje=φ(xγ)=mean(abs(var y(xγ)))
24、其中,vary()表示求相邻时间帧之间特征的变化值,abs()表示取绝对值操作,mean()表示对时间维度上的特征变化求均值;
25、sd,基于所述最终的拓扑增强结构部分的矩阵adje增强预定义好的人体结构矩阵adj,得到最终的人体结构adjn,具体公式为:
26、adjn=ψ(adj,α,adje)=adj+α⊙adje
27、其中,⊙表示按元素相乘,α表示权重矩阵,为随机生成的可训练的n×n的矩阵;adj∈rn×n表示预定义好的人体结构矩阵;
28、se,将行人i的人体姿势人体姿势ki首先经过维度转换变为ki∈r(c×t)×n;然后与最终的人体结构adjn进行矩阵相乘,再进行维度转换得到k′∈rc×t×n,最后得到行人i的动作特征具体公式为:
29、k′i=view(mul(view(ki),adjn))
30、
31、其中,view()表示特征维度变换,mul表示矩阵相乘,k′∈rc×t′×n,w4和w5分别表示2个卷积操作的参数,bn和relu分别表示归一化操作和激活函数,t′为经过时间卷积后的时间维度大小。
32、进一步,所述基于行人i在自车视角中的人体检测框中心点位置ci,获取行人i在自车视角中的人体检测框中心位置在时间维度上的特征包括:
33、在一维卷积的基础上使用gru提取人体检测框中心位置在时间维度上的特征具体公式为:
34、
35、其中,gru表示门控循环单元;view表示特征维度变换;w3表示一维卷积conv1d3的参数;ci∈rt×2;c表示特征维度,t表示时间维度;t′表示经过时间卷积后的时间维度大小。
36、进一步,所述行人i在自车视角中的类极坐标pi的获取方法包括:
37、s1、分别以自车摄像头拍摄画面的底部左边沿点o1、中心点o2及右边沿点o3为极点,以向量为极轴,逆时针为正方向构建三准极坐标系,其中,on为自车摄像头拍摄画面的底部上位于o3右侧的点;
38、s2,t时刻行人i在三准极坐标系中的坐标为其中,分别为t时刻行人i在汽车视角中的横向方位;
39、s3,获取行人i在自车视角中的类极坐标,具体公式为:
40、
41、其中,concatenate操作表示将作为行人i在t=1时刻的坐标,将时间长度为obs-1的相对变化序列拼接到t=1时刻的坐标中,时间长度为obs-1的相对变化序列表示为:
42、
43、进一步,基于行人i在自车视角中的类极坐标pi,获取类极坐标特征包括:
44、使用一维卷积聚合行人i在自车视角中的类极坐标pi邻域时间内的特征,得到类极坐标特征具体公式为:
45、
46、其中,view表示特征维度变换;w2是一维卷积conv1d2的参数;pi∈rt×3;t表示时间维度;c为特征维度;t′为经过时间卷积后的时间维度大小。
47、进一步,基于所述行人意图特征得到行人穿越预测结果,包括:
48、将行人意图特征送入多层感知机mlp中,得到行人穿越预测结果,具体公式为:
49、
50、其中,argmax表示取元素中最大值的下标,softmax为激活函数,mlp为多层感知机,wmlp为多层感知机的函数。
51、采用上述技术方案后,本发明设计了轻量化的快速行人穿越预测网络,该网络采用了多模态数据输入,并从原理上分析了这些数据对行人过街意图的作用并多角度改进来增强结果预测;为了解决输入特征冗余和挖掘富含行人意图信息的模态数据,本发明从人车互动角度采用类极坐标作为人车互动的特征表达;为了高效地进行交通场景下不同模态数据的融合,从特征互补和增强方面提出了新的简单有效的数据融合方法,提高了融合效率以及预测准确率;为了缓解使用循环神经网络出现的过拟合问题,采用了一维卷积神经网络处理时间序列问题,通过不同的卷积核大小获取不同的感受野,而不是在每一个时间步使用全连接层;为了处理非欧几里得几何的人体姿势数据以及深入地学习和提取行人穿越动作的显著特征,我采用temporal-channel sharing enhanced topology graphconvolution(tcgc),从全局时间维度的人体姿势关键点间相关性的变化强调关键点之间的联系,对原人体结构进行增强,并提出了时间通道共享的人体拓扑结构思路。本发明可以在交通场景中快速准确地预测行人穿越行为。
- 还没有人留言评论。精彩留言会获得点赞!