一种基于人工反馈强化学习的自动化文本信息抽取方法与流程
本发明涉及文本报告智能分析,尤其涉及一种基于人工反馈强化学习的自动化文本信息抽取方法。
背景技术:
1、目前,网络信息的发展进入到了一个全新的时代,相应产生的数据持续加速增长,大量的文本报告以自然语言的形式存在,文本文本报告成为文本报告分析过程中重要的信息来源,其中文本信息抽取是智能分析的重要环节,通过信息抽取将非结构化文本数据中的信息进行结构化,为后续的文本报告知识图谱构建、自动化计算、智能分析提供基础,人工分析处理文本报告、进行信息抽取需要具备一定的专业领域知识,且费时费力,评估效率低下,难以应对与日俱增的海量数据,对于一篇文本报告,相关信息通常分散在整篇文章中,各个要素之间存在错综复杂的关系,信息抽取的准确性显得尤为重要,甚至直接决定了后续文本报告分析的效果,针对这种情况,人们对自动化文本信息抽取方法进行了大量研究当前主要采用的信息抽取方法主要有:
2、1.基于人工规则的方法:首先了解需要抽取的文本信息特点,例如文本中常用的语法句法格式,文中关键句中常用的关键词等,通过了解抽取文本的特点运用正则表达式和spacy等python函数将文本中涉及的语法规则编写出来并且建立关键词词库用于提取原文语句中的信息。
3、存在的问题:该方法完全依靠人工进行规则的总结和编写,需要技术人员同时具备该业务领域经验和自然语言处理的专业知识,对人员的要求较高。此外,该方法只能适用于特定领域的数据和具体类型的信息抽取任务,当数据领域变化或抽取任务有新增和修改时,需要人工重新总结并实现相应的规则,并且难以适应复杂的文本结构和多样化的语言表达方式。
4、2.基于统计及机器学习的方法:通过使用机器学习的句法分析,从标注好的训练数据中学习模式和规律,进而进行文本信息抽取,句法分析算法包括基于概率的短语结构分析方法pcfg,条件随机场(crf),基于最大间隔马尔可夫网络的句法分析,基于移进归约的句法分析,该类方法能一定程度上解决复杂文本结构和多样化语言表达方式的问题。
5、存在的问题:该方法需要手动设计和提取特征,同样需要技术人员具备一定的领域经验,且设计迭代过程较为耗时,对于标注数据的需求较高,需要大量的标注样本进行训练,难以进行泛化,对于新的领域或任务,需要重新训练和调整模型。
6、3.基于深度学习的方法:采用卷积神经网络(cnn)、循环神经网络(rnn)、长短期记忆网络(lstm)、注意力机制(attention)等,对文本进行建模和表示,从而实现信息抽取任务,这些方法通常需要大量的标注数据和计算资源,但在处理复杂结构和语义理解方面表现较好。
7、存在的问题:需要大量的标注数据进行训练,否则无法使用,标注成本较高,训练过程相对较慢,需要较高的计算资源,模型可解释性相对较差,难以理解和调试模型的内部机制,无法引入专业领域的人工经验。
8、综上所述,目前的文本信息抽取方法普遍存在着泛化性不好,难以快速适应不同领域;需要领域专家深度参与或大量人工标注数据,费时费力;遇到bad case或需要对抽取任务进行调整时,难以灵活响应,需要重新训练模型等问题,因此,迫切需要一种能够快速适应相关领域、具备引入人工在专业领域的经验,在少量标注数据条件下即可有效工作的文本报告信息抽取方法和装置,此外,该方法还需要具备根据抽取效果快速调整和修改的能力。
9、因此,有必要提供一种基于人工反馈强化学习的自动化文本信息抽取方法解决上述技术问题。
技术实现思路
1、本发明提供一种基于人工反馈强化学习的自动化文本信息抽取方法,解决了目前的文本信息抽取方法普遍存在着泛化性不好,难以快速适应不同领域;需要领域专家深度参与或大量人工标注数据,费时费力;遇到bad case或需要对抽取任务进行调整时,难以灵活响应,需要重新训练模型等的问题。
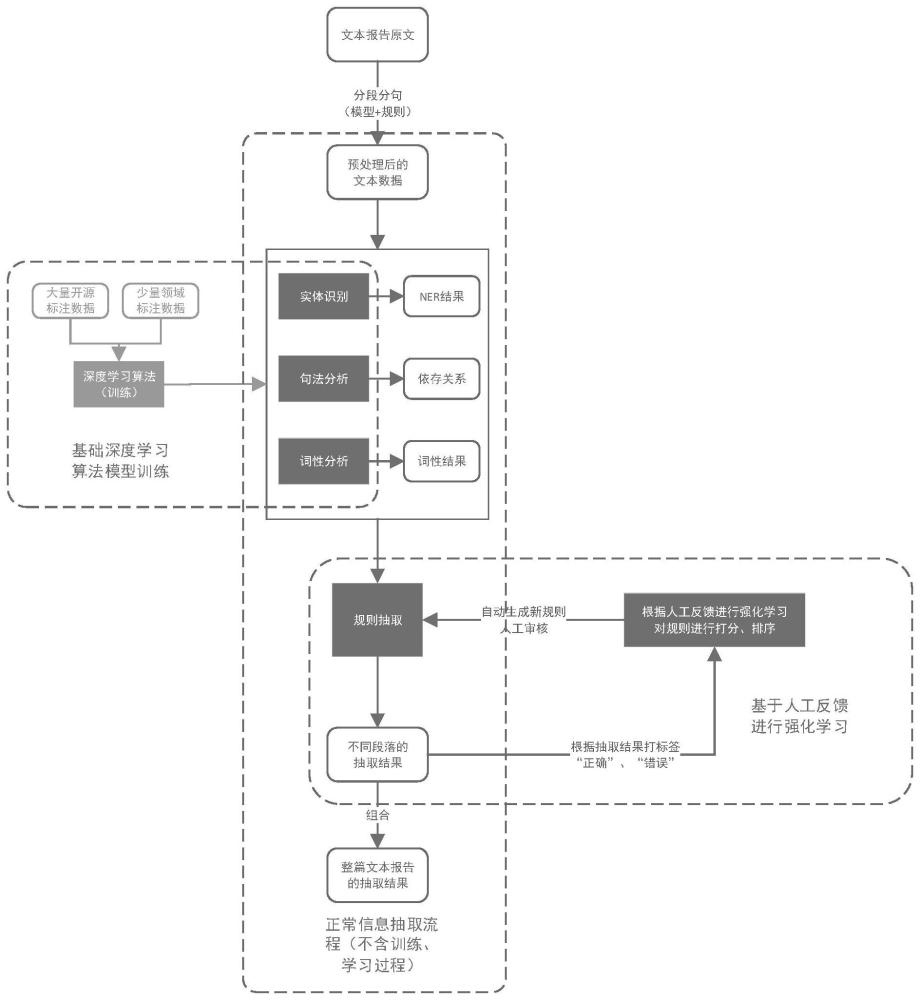
2、为解决上述技术问题,本发明提供的一种基于人工反馈强化学习的自动化文本信息抽取方法,包括以下步骤:s1:建立待抽取的命名实体、关系、事件的种类及具体形式;
3、s2:收集开源中文语料数据,对基础命名实体识别模型进行训练;
4、s3:对整篇人力文本报告进行预处理,整篇文本报告通常分为情况概述、详细情况、涉及人员信息、后续处理情况等四个部分,顺序不固定;
5、s4:使用经过训练的ner模型、词性分析模型、依存句法分析模型对单句文本报告进行命名实体识别、词性分析、句法分析;
6、s5:针对不同的部分,结合原始语料和得到的三类模型ner模型、词性分析模型和依存句法分析模型分析结果,进行不同的后续分析;
7、s5:对于属于涉及人员情况段落的句子,对单句中的人名、证件号、地址、电话号码等信息进行聚合,得到单条的人员详细结构化信息;
8、s6:将抽取的信息进行融合,根据人名完成人员匹配,将抽取到的关系对和事件信息中人名替换为唯一证件号,便于后续进行知识图谱的实体链接。
9、优选的,所述命名实体包括人名、时间、地点、组织机构;关系包括常见人物亲属及社会关系;事件为文本报告业务关注的发表不满言论、不满管理、网上异常行为等。
10、优选的,所述收集开源中文语料数据中,按照一定比例替换其中的人名,并加入人工标注的文本报告业务数据,顺序进行随机打乱,形成定制化的适用于人力文本报告的训练数据集。使用基于预训练语言模型的类bert网络对输入数据进行编码,后续接入lstm及global pointer网络架构进行解码,完成命名实体识别网络搭建,使用梯度下降算法进行训练,调整各层参数,直至收敛完成训练。
11、优选的,所述人力文本报告训练段落分类模型,并结合业务专家总结的规则,使用模型+规则的方式对整篇人力文本报告的各段进行分类,分段后,使用基于标点符号的方法对每段语料进行分句。
12、优选的,所述模型分析结果由专家对少量数据进行分析,对不同种类的关系和事件建立基础抽取规则,规则具体为:什么样的触发词,前后有什么样的实体或关键词,属于什么样的关系或事件要素,例如:人名+造谣说。
13、优选的,所述人名通过ner识别结果,所述造谣说的触发词,词性分析结果为动词,依存句法分析为人名的父节点。
14、优选的,所述训练得到的深度学习模型和基础抽取规则对文本数据进行分析,根据系统抽取,由业务人员对整篇和单句的抽取结果进行评价,评价方式为根据抽取结果是否正确打标签“正确”和“错误”。
15、优选的,所述系统根据业务人员打标签的结果进行强化学习,自动生成及更新待抽取关系和事件的规则或模式,通过实体识别、词性分析、句法分析结果组成规则对,在标记为“正确”的数据中,对与抽取结果相关的规则增加分数;在标记为“错误”得数据中,对与抽取结果相关的规则减少分数,与抽取结果相关的规则为该条规则中涉及抽取结果中的实体,如涉及一个人名或地点,且涉及实体的多少影响该条规则赋分的绝对值,实时更新各个规则的分数,对分数超过一定阈值的,认为是系统学习到的新规则或模式。
16、优选的,所述数据被学习后,由业务专家对所述系统根据业务人员打标签的结果进行强化学习,自动生成及更新待抽取关系和事件的规则或模式两个步骤重复进行步骤生成的新规则或模式进行人工评价,根据是否符合业务要求对自动生成的规则或模式进行保留或修改,及人工审核该规则是否合理。
17、优选的,所述系统根据训练得到的深度学习模型和基础抽取规则对文本数据进行分析抽取和所述系统根据业务人员打标签的结果进行强化学习,自动生成及更新待抽取关系和事件的规则或模式两个步骤重复进行,人工只进行打标签和对生成的新规则或模式审核,无需其他标注,由系统自动更新算法,直至系统抽取准确率符合要求。
18、与相关技术相比较,本发明提供的一种基于人工反馈强化学习的自动化文本信息抽取方法具有如下有益效果:
19、本发明提供一种基于人工反馈强化学习的自动化文本信息抽取方法,通过采用深度学习和人工反馈强化学习技术,自动完成垂直领域文本的信息抽取,降低了对业务人员的要求及标注数据量要求,与现有技术方案相比,本发明具有更好的多领域适应性、可解释性和更低的算力要求,适用于多业务领域的信息抽取任务,有助于减少开发及标注成本,提高抽取准确率,本发明的技术方案和实现方法具有广阔的应用前景和市场价值。
- 还没有人留言评论。精彩留言会获得点赞!