一种用于多模态命名实体识别的交互对比学习方法
本发明属于自然语言处理,尤其涉及一种用于多模态命名实体识别的交互对比学习方法。
背景技术:
1、命名实体识别是自然语言处理领域的一项重要工作,旨在从非结构化文本中提取结构化信息,帮助研究人员梳理知识。同时,它也是构建知识图谱的重要步骤。随着互联网的飞速发展,信息不再局限于文本形式,而是向多模态发展。这对传统的ner任务提出了重大挑战,其中最重要的是文本的内容变得模糊,如果没有图像等其他模态信息的帮助,就不可能清楚地确定所包含的实体及其类型。因此,出现了一个新的任务mner。mner并不局限于nlp研究,而是扩展到多模态领域,其任务定义为m(s,i),其含义为利用模型m和给定的文本s和相应的图像i,以识别文本中的实体。
2、值得注意的是,由于上下文长度的原因,文本可能无法提供足够的语义依赖,文本中也可能存在歧义词,导致传统的ner方法无法正确识别和分类。例如,如图1所示,“mickey”是一个家喻户晓的动漫角色,因此在一些文本中,它可以被归类为[per]类别;而在另一个文本中,“mickey”是宠物的名字,应归类为[misc]类别;类似地,也有一些景点的名字是“米奇”([loc]类别)。虽然它们是同一个名字,但在不同的语境中代表着不同的含义和类别。人类可能不难理解,但机器很难理解,需要指导才能理解真正的含义,因此mner任务是必要的。
3、mner任务的主要挑战,除了必须应对缺乏上下文依赖性之外,还有几个问题需要解决。问题1:如何确定哪些视觉提示对mner任务有用。粗粒度视觉信息不仅对mner不实用,而且还反映了大量的噪声,这些噪声会误导模型做出错误的确定。问题2:视觉特征和文本特征的特征空间有很大不同。统一视觉特征和文本特征以减少特征空间差异带来的不利影响也是一个重大挑战。
4、先前的研究已经在功能上实现了mner,但对上述两个问题的解决方案并不令人满意。最古老的相关研究使用注意力机制来融合多模态信息,但将粗粒度特征应用于视觉端,这引入了过多的噪声。最近的一些研究表明,将视觉特征分解为目标级特征对mner更有利,可以有效地减少噪声的影响。对于问题2,在clip的提议下,对比学习方法统一了不同模态的特征空间,减少了由于特征空间差异造成的负面影响。尽管现有的研究已经尽可能地通过各种创新来应对上述重大挑战,但仍有一些方面需要改进,例如,不同模态的不同粒度之间的关系,过度依赖文本特征而忽视视觉特征,以及缺乏有效减少多模态数据特征空间差异方法。
技术实现思路
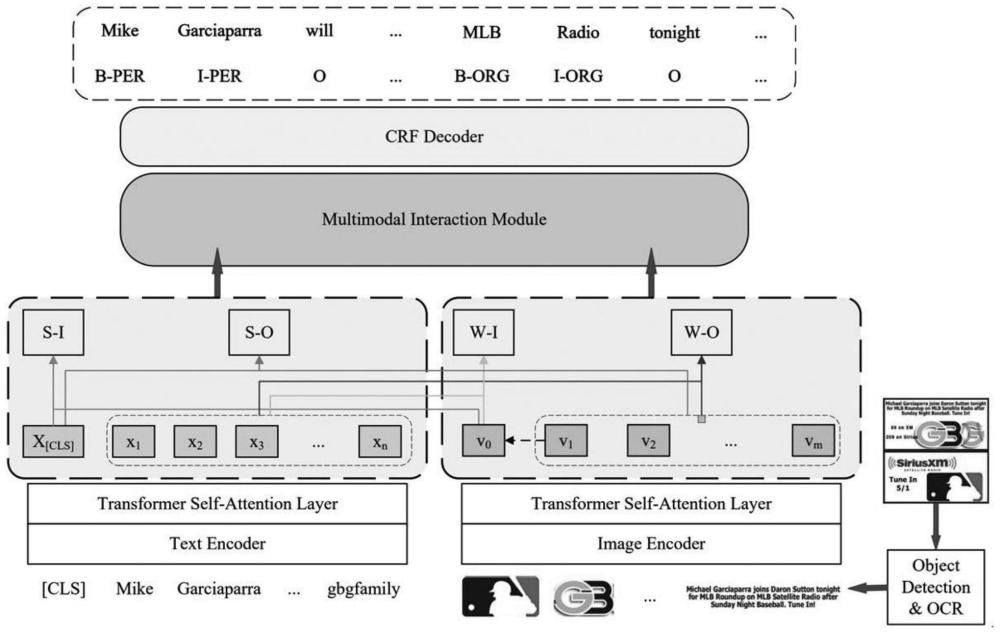
1、有鉴于此,本发明提出了一种用于mner任务的多粒度交互对比学习框架,即mgicl。mgicl将数据分为不同的粒度,即文本的句子级别/词语标记级别,图像的图像级别/目标级别。通过利用具有不同粒度的多模态特征,该框架实现了交叉对比,并缩小了模态之间的特征空间差异。此外,它有助于文本获得有价值的视觉特征。此外,引入了一种视觉门控机制来动态选择相关的视觉信息,从而减少了视觉噪声的影响。实验结果表明,本发明提出的mgicl框架通过增强多模态数据的信息交互和减少噪声的影响,成功地解决了mner的挑战,从而有效地提高了mner性能。
2、本发明公开的用于多模态命名实体识别的交互对比学习方法,包括以下步骤:
3、获取文本s和图像i,并分别进行编码;
4、将文本和图像分割成具有不同粒度的特征,并将它们交叉进行对比学习,具体包括多模态表示、多模态交互对比学习;所述多模态表示将获得的文本和图像表示序列输入自注意力层计算,以更新表示序列,并将词语标记特征组合成矩阵;所述多模态对比学习包括句子-图像对比,句子-目标对比,词语标记-图像对比,词语标记-目标对比,在此基础上计算包含多粒度对比的相似性;
5、以文本侧为主体构建查询q,以图像侧为主体构造关键字k和值v,进行交互式注意力计算,得到融合了视觉特征增强的文本表示;
6、使用视觉门控机制以动态选择对文本更有价值的视觉特征,避免视觉噪声对识别性能产生负面影响;
7、在获得视觉特征增强的文本表示之后,使用crf层确定文本中包含的实体的类型,利用交叉熵来优化模型的参数,
8、训练后的模型接收新的输入数据,并输出预测结果。
9、进一步地,对于文本s={w1,w2,...,wn},使用预训练的编码器进行编码,获得初始化的文本表示如下:
10、s={w[cls],w1,w2,...,wn},
11、其中w[cls]表示句子级别的文本特征,wi表示词语特征,n表示文本长度;
12、在对图像i进行编码之前,进行目标检测ob和光学文字识别ocr,以获得关键目标o,o=ob/ocr(i)={o1,o2,...,om},在从图像中提取的文本被计数为关键目标的图像中,oi表示图像i中的第i个关键目标;
13、此外,还利用预训练的编码器对检测到的关键目标进行编码:
14、o={o[cls],o1,o2,...,om},
15、其中o[cls]对应于可学习的[class]嵌入,oi表示图像i中的第i个关键目标,m表示通过ob/ocr获得的关键目标的数量。
16、进一步地,为了获得序列的内部依赖关系,将获得的文本和图像表示序列送入自注意力层进行计算,以更新表示序列,
17、
18、
19、表示句子级别的特征,表示图像特征,进一步地,将符号简化为并且所有的词语标记特征被组合成矩阵t(v)。
20、进一步地,多粒度的对比学习包括:
21、句子-图像对比:给定句子级表示t∈rdim和图像级表示v∈rdim×m,使用矩阵乘法来评估句子和图像之间的相似性,公式化为:
22、cs-i=ttv,
23、其中t为给定句子级表示,v为图像级表示,t为转置运算,cs-i是句子图像相似性得分;
24、句子-目标对比:对于给定的句子级表示t∈rdim和目标级表示向量v∈rdim×m,使用矩阵乘法来计算句子表示和每个目标表示之间的相似性,表示如下:
25、cs-o=ttv,
26、其中,t为转置运算,cs-o∈r1×m是句子和图像中的每个目标之间的相似性向量,m是关键目标的数量;
27、词语标记-图像对比:计算词语表示t∈rdim×n和图像表示v∈rdim之间的相似性,其公式化如下:
28、cw-i=ttv,
29、其中,t为转置运算,cw-i∈rn×1是每个词语的标记表示和图像之间的相似性向量,n是句子中词语表征的数量;
30、c'w-i的计算如下:
31、
32、i表示向量第i行,j表示向量第j行,τ表示softmax的温度参数;
33、词语标记-目标对比:词语表示和目标表示之间的细粒度相似性矩阵使用矩阵乘法来获得:
34、cw-o=ttv,
35、其中,t为转置运算,cw-o∈rn×m是细粒度相似性矩阵,n和m分别是词语标记和关键目标的数量;
36、cw-o∈rn×m包含n个词语和m个目标的相似性分数,对矩阵执行两次注意力运算;获得细粒度的相似性向量,其公式如下:
37、
38、
39、其中,*表示维度中的所有元素,ctext∈r1×m和cimg∈rn×1分别是句子级别和图像级别的相似性向量,具体而言,ctext∈r1×m显示句子与m个目标的相似度,cimg∈rn×1表示n个词语和图像的相似度。
40、进一步地,对于相似性向量cs-o∈r1×m,首先使用softmax来获得相似性向量的权重,其中与查询相关的细粒度特征的分数将被赋予高权重;然后,根据获得的权重来聚合这些相似性得分,公式化如下:
41、
42、其中τ是softmax的温度参数。
43、进一步地,为了获得细粒度的实例级相似性得分,对句子级向量ctext∈r1×m和图像级别cimg∈rn×1相似性向量进行第二次注意力操作,表示如下:
44、
45、
46、其中c‘text和c'img是实例级别的相似性;
47、使用平均值作为细粒度相似性得分
48、c'w-o=(c'text+c'img)/2.
49、最终得分,包含多粒度对比的相似性c(vi,tj)表示如下:
50、c(vi,tj)=(cs-i+c's-o+c'w-i+c'w-o)/4.
51、在训练期间,一批训练数据含有b个句子图像对,将生成b×b的相似性矩阵;在相似性矩阵上使用对称的infonce损失:
52、
53、
54、lmgcl=lt2v+lv2t。
55、进一步地,进一步考虑模态之间的相互作用,包括:
56、以文本侧为主体构建查询q,以图像侧为主体构造关键字k和值v,如下所示:
57、
58、
59、其中是连接运算,t为转置运算,并且分别表示文本端特征和视觉端特征,并在随后的交互式注意力计算过程中使用;
60、
61、ai=ai(wvik)t,
62、其中和t为转置运算;
63、在经过多模态transformer层计算后,将所有的ai合并得到融合了视觉特征增强的文本表示
64、a=[a1;a2;…;an+1]t,
65、t为转置运算,a是增强视觉特征后的文本序列的表示,表示为
66、a={a[cls],a1,a2,…,an}.
67、进一步地,为了进一步减少词语在与图像信息交互后产生的噪声,使用视觉门来动态控制每个词语的视觉特征的贡献:
68、
69、其中是训练参数,是element-wise sigmoid函数;最
70、后,视觉感知的词语表示被获得为:
71、b=g·a.。
72、进一步地,在获得文本的视觉信息增强表示之后,使用crf层确定文本中包含的实体的类型:
73、
74、利用交叉熵来优化模型的参数,
75、
76、其中yi是真标签的独热向量,是预测的标签分布,c是类别的总数。
77、本发明的有益效果如下:
78、本发明提出了一个用于mner任务的多粒度交互对比学习框架mgicl,该框架实现了多粒度对比学习,以减少不同模态特征之间的差异和视觉噪声的影响;
79、为了增强模态之间的信息交互,还提出了一种多模态特征交互方法。此外,还提出了一种视觉门控机制,以动态选择视觉特征,提高mner任务的有效性;
80、在两个标准数据集上进行了验证,与现有的相同任务sota模型相比,本发明更准确;并对相关研究进行了详尽的分析。
- 还没有人留言评论。精彩留言会获得点赞!