一种基于Transformer和对比学习的无监督Web攻击检测方法
本发明属于web数据异常检测,涉及一种基于transformer和对比学习的无监督web攻击检测方法。
背景技术:
1、web日志数据:web应用广泛,用户和web服务器使用http(s)协议来交换信息和数据。http请求包括get和post请求。http中的get方法主要用于检索资源(如网页、图像等)并允许通过url参数传递少量数据。另一方面,post方法主要用于提交数据(如表单数据、文件上传等)发送到服务器,并允许传递大量数据。图1(a)和(b)分别给出了csic 2010数据集中get和post http请求的示例。
2、get请求通常由两部分组成,即请求行和请求头。请求行包含http方法“get”、url(方案、主机、端口、路径和查询字符串)和http版本。请求头包含cookie和连接等信息。
3、post请求通常由三部分组成,即请求行、请求头和请求体。请求行包含http方法“post”、url(方案、主机、端口、路径)和http版本。请求头与get方法一致。请求体包含要发布或修补的数据。
4、请求体是可选的,因为在一些请求体中可能没有什么要表达的,比如使用get方法的资源检索。图2显示了一个典型的url,它由方案、主机、端口、路径和查询字符串组成。查询字符串包括键和值。不受控制的用户输入可能会导致web攻击,这些输入通常包含在httpget查询字符串和post请求体中。攻击者可以利用它们来创建或操纵对web服务器的请求,并执行恶意操作。因此,为了检测攻击,关注get请求中的url,以及post请求中的url和请求体。为了简单起见,仍然使用url来指代post请求的url和请求体。
5、传统的web攻击检测方法可以分为两类:基于规则的检测方法和基于行为的检测方法。基于规则的方法根据已知攻击建立检测模型,将任何具有相应攻击特征的行为识别为攻击。相反,基于行为的方法开发了一个可接受行为的配置文件,并将任何偏离标记为攻击。
6、深度学习和机器学习能够从数据中提取模式和特征,以自动区分各种对象类型。各种机器学习方法已被用于检测web攻击,如hqtn、svm optimization、开源one-classsvm。这些方法手动选择特征,例如属性名、属性值、属性长度、属性字符分布、结构推理、属性顺序等。为了自动提取特征,深度学习被应用于web攻击检测。由于web日志包含大量的单词,许多方法使用自然语言处理(natural language processing)技术,如n-gram、单词嵌入来提取特征,并利用lstm、自动编码器和rnn来检测异常行为,如elsv、logbert-bilstm、deepwaf和autoencoder。
7、传统的web攻击检测方法需要足够的异常或正常行为的特征和表现,而针对新攻击更新规则是一项耗费人力和时间的任务。机器学习方法需要手工提取特征,而这依赖于专家知识,并且消耗大量的时间和资源。同时这些方法通常为每种类型的url训练一个单独的模型,并且一个模型仅适合一种类型的url,导致大量的模型降低了效率。深度学习很难检测未知的web攻击,同时检测模型需要处理长序列数据,然而大多数方法利用cnn和lstm模型,它们不能有效地捕捉长的长期依赖性。现实生活中往往web日志的标签很少,人工标记消耗了大量的劳动和时间;web日志数据不足,用大量的数据训练一个合理的模型,既不实际,也没有效率。
8、现有的深度学习存在的问题是很难检测到未知攻击。虽然大多数基于深度学习的方法考虑了语义特征,但是这些方法是有监督的,需要异常标记,并且不能识别新的攻击。autoencoder是无监督的,但它直接用ascii码替换字符,并忽略语义特征。与有监督的方法相比,它实现了较低的性能。可以知道,恶意查询具有更大的值长度。检测模型需要处理长序列数据。然而,大多数方法利用cnn和lstm模型,它们不能有效地捕捉长系列的长期依赖性。
9、现有的监督方法存在的问题是web日志的标签更少。一般来说,正常的授权访问行为可能会留下相对较多的web日志。此外,在许多情况下,攻击者和普通用户生成的web日志是相似的,这使得没有丰富知识和经验的专家很难区分这两者。web日志数据的人工标记消耗了大量的劳动和时间。
10、现有方法在模型训练上存在的问题是web日志数据不足。现实中公共和私有web日志数据集的数量比计算机视觉和自然语言处理数据集的数量要少。用大量的数据训练一个合理的模型,既不实际,也没有效率。因此,模型需要用较少的数据进行训练。
技术实现思路
1、现有的监督的深度学习的方法只能粗浅的学习语义特征,不能处理自然语言的长期依赖和复杂的语义关系,并需要大量的标签和web日志数据才能训练出一个较好的模型。本发明提出了一种基于transformer和对比学习的无监督web攻击检测方法解决了上述问题。
2、一个web日志数据集d={s1,s2,...,sn}包含n个url,其中数据集d的url都正常,随机分成数据量相等的d1和d2两部分,其中si代表d1的第i个url,sj代表d2的第j个url。训练一个分类器c:si→[0,1],去判断新到达的url是否异常,其中0为正常,1为异常。
3、步骤1:建立web攻击检测框架
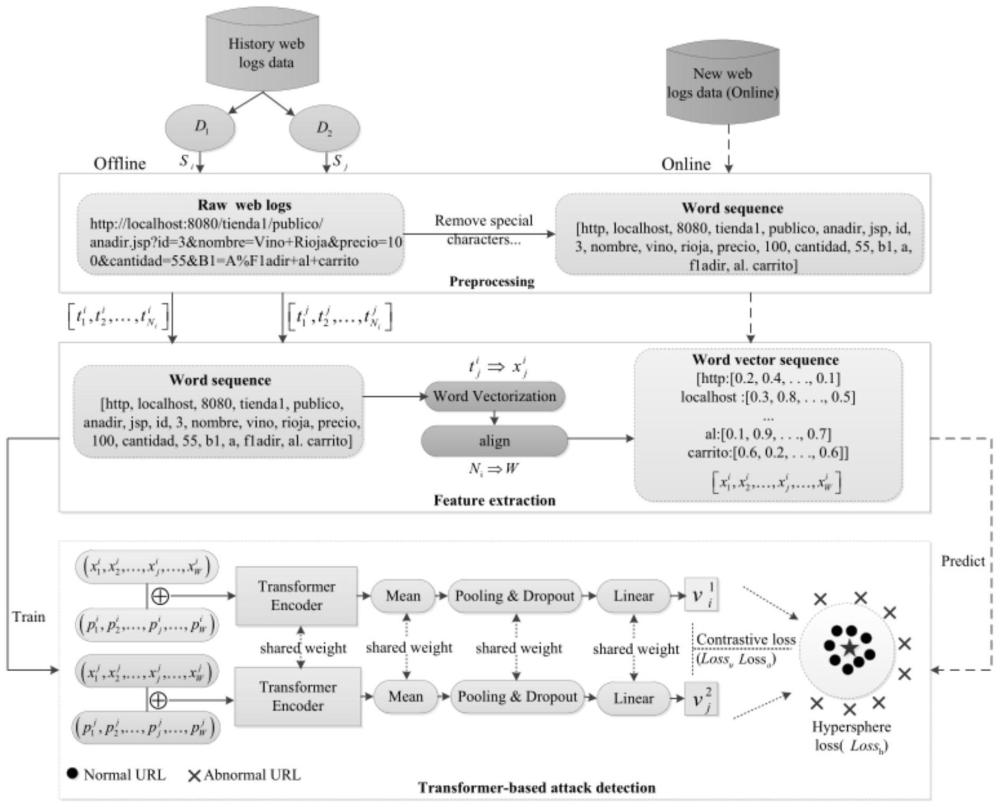
4、为了识别未知的web攻击,提高攻击检测的准确性,提出了一种基于transformer和对比学习的无监督web攻击检测方法。uwadt利用transform代替lstm,后者捕获长期依赖关系并处理复杂的语义关系。uwadt利用超球损失函数代替交叉熵损失函数,避免了对异常标记的要求。对比学习的好处,uwadt用较少的数据达到与大量数据同样好的效果。uwadt由预处理、特征提取和攻击检测三个模块组成。图3是uwadt的框架。
5、一是预处理:它删除特殊字符,如“/、=”,并将url转换为单词序列。因此,si可以用表示,其中表示第i条url中的第j个单词,ni是url中包含的单词数。单词数不一样。
6、二是特征提取:提取url的特征表示。word2vec用于获取单词的向量表示,即每个单词都转换成一个d维向量一个url可以用url中单词的向量序列来表示。url中的字数是不同的。因此,为了适合下面的转换器模型,url通过截断或填充与w个单词对齐,这由
7、三是基于transformer的攻击检测:通过超球面和对比学习,训练transformer模型,让正常日志相互靠近。那么对于新到达的url,它远离超球中心的形式被视为异常。
8、步骤2:预处理模块
9、在自然语言中,url被视为一个字符串,繁琐且不方便处理。因此,为了便于处理和捕获url的语义,通过预处理将url分成一个单词串(单词序列)。主要步骤包括小写、拆分和解码。
10、1)小写。因为url不关心大小写,将每个字符都小写以使词汇量更小。
11、2)分割。url可以由特殊字符如“/”、“&”、“=”和“+”分隔成单词,并用逗号分隔。
12、3)解码。由于url中支持的字符有限,一些特殊字符(如空格、@等。)和中文需要用url编码。攻击者经常使用这些编码来隐藏攻击负载。所以把解码放在拆分之后,主要是为了尽可能多的保留攻击信息。
13、图4示出了url“https://www.example.com/search?q=%40openai%2fgptpt-3.5。它由特殊字符分隔。最后,%40和%2f解码成“@”和“/”。“gpt”变成了“gpt”。
14、经过预处理后,第i个url用其中是第i个url的第j个字,i∈[1,n],j∈(0,ni),ni是第i条url的单词数。不同url的单词数不一样。
15、步骤3:特征提取模块
16、为了获得url的特征,首先通过词嵌入获得单词向量,单词序列可以用一个单词向量序列来表示,也就是将urlsi转换成语义向量序列xi,如图3的第二块所示。
17、自然语言处理中的单词嵌入是指将自然语言中的单词映射成数值的一种方式。具体来说,将一个高维空间嵌入到一个维数低得多的连续向量空间中,每个词映射到实数域的一个向量中。这个向量往往可以描述词语附近的上下文词语信息,捕捉各种语义关系,从而真正理解这些自然语言。目前有几种单词嵌入方法,如one-hot编码、共生矩阵、word2vec、glove等。word2vec使用只有一个隐层的浅层神经网络,以大文本语料库为输入,最终生成向量空间。在向量空间中,语料库中的每一个唯一词都被映射到一个d维向量上,该向量可以充分捕捉自然语言中词与词之间的内在关系(即语义相似度)。word2vec的训练速度快,可以处理大量的数据。因此,利用word2vec通过其包含的单词向量序列来表示url。
18、在下面的检测模型中,transformer只处理具有相同长度的统一序列。但是每个url包含的字数是不一样的。为了支持transformer,使单词的数量一致,并用窗口大小w截断或填充url的单词向量序列,即其中表示第i个url中第j个单词的向量。
19、窗口大小w的设置会影响性能。如果太大,url的词向量序列是稀疏的,消耗更多的计算资源;而如果它太小,就会丢失太多信息。因此,设置窗口大小w来覆盖90%的url。
20、步骤4:基于transformer的攻击检测模块
21、在特征提取之后,每个url si被转换成词向量序列有了这样的语义向量序列,的方法使用基于语义的转换器进行web攻击检测,以应对未知的攻击。
22、引入transformer是为了克服长期依赖性,并且可以处理复杂的语义关系,包括位置编码和transformer编码器,如图5所示。transformer从词向量序列中提取语义向量序列oi,然后将语义向量序列组合成深度特征vi来表示url。
23、位置编码:url的不同部分通常需要按照特定的顺序排列。例如,dt攻击是使用路径的攻击,如果url中的路径顺序是正确的,就可以防止这种攻击。因此,url中的词序传达了web攻击检测任务的重要信息。在word2vec中,语义相近的词之间的距离更近。然而,这些向量不包括单词在url中的相对位置信息。因此,应用正弦编码器来为序列xi中的单词位置j生成位置嵌入pji[31],如等式(1)所示。
24、
25、
26、其中j是指单词在单词序列中的位置,d是单词向量的维数,k∈[0,d)是嵌入在该位置中的维数索引。当k为偶数时,使用正弦编码,当k为奇数时,使用余弦编码。最后,所有维度索引的值形成一个位置嵌入向量。位置编码只取决于单词向量的维数d和当前单词在单词序列中的位置j。
27、然后,如图3的第三块所示,在位置j将加到词向量上,并将馈送到transformer编码器。因为序列中的每个单词都有相对位置,所以模型可以学习该信息并区分处于不同位置的单词。
28、transformer编码器:它包括一个自关注层和一个前馈层。给定一个输入位置嵌入是在它进入transformer之前添加的。在transformer模型中,多头注意力层用不同的注意力模式计算每个词的注意力得分矩阵。注意力得分是通过训练查询q和关键k矩阵得到的,它考虑了哪个词重要。如等式(2)所示用线性映射wo将多个头部连接在一起。
29、multihead(q,k,v)=concat(head1,...,headh)wo
30、whereheadi=attention(qwiq,kwik,vwiv) (2)
31、层间特征连接成前馈网络,例如公式(3)包含两个完全连接的层。
32、ffn(ui)=relu(uiw1+b1)w2+b2 (3)
33、其中w1和w2为权重矩阵,b1和b2为偏置向量,ui表示多头注意力之后第i个url的归一化结果。
34、如图5所示,语义向量序列oi是transformer编码器的输出,对应于等式(4).语义向量序列平均后,进入池化层、dropout层和全连接层,得到url的深度特征vi,如等式(5)所示。
35、oi=encoder(xi+pi) (4)
36、vi=linear(dropout(pooling(mean(oi)))),vi∈v (5)
37、步骤5:超球和对比损失模块
38、为了聚类正常url的深层特征,对齐语义向量序列对并保留最大信息,通过最小化超球损失函数和对比学习损失函数(对齐损失和均匀损失)来构造总损失函数,以约束transformer的特征。
39、超球损失函数:超球损失首先应用在计算机视觉(cv,图像识别)中,也称为a-softmax损失函数,类似于nlp中的一类svm。如图3所示,超球面损失函数调整所有正态对数序列的分布。因此,异常标签不是必需的。其动机是正常的url应该集中在嵌入空间中并尽可能靠近超球面的中心,而异常的url应该尽可能远离超球面的中心。通过验证数据可以得到最佳超球面半径(决策边界)。超球面损失函数是样本到中心距离的均方误差和,如式(6)所示。
40、
41、其中c是超球面的中心,v1和v2是深层特征的集合,vi表示第i个单个url的深层特征。
42、对比损失函数:对比学习旨在通过比较两个或多个样本之间的相似性或差异来学习模式,如图6所示。对比学习通常用于目标检测、图像分类、推荐系统等领域。对比学习的优点是最大化正样本和负样本之间的距离,同时尽可能最小化正样本之间和负样本之间的距离。因此,同类的样本可以靠近,不同类的样本可以远离。为了将相似的特征分配给同类的样本并尽可能保留特征分布,引入了对齐损失和均匀性损失。对齐损失对齐或缩短同类样本对的特征距离,均匀性损失使特征均匀分布在超球面上。对齐损失函数如式(7)所示。
43、
44、其中表示d1中url的深层特征,表示d2中url的深层特征,n/2分别表示d1和d2中url的数量。
45、希望均匀性度量既渐近有效,即优化该度量的分布应收敛到均匀分布,又在少量点的情况下在经验上合理。为此,考虑高斯势核(也称为径向基函数核),并将均匀性损失定义为平均成对高斯势的对数。均匀性损失函数如式(8)所示。
46、
47、总损失函数的定义如式(9)所示:losssum=losss+α1*lossa+α2*lossu (9)
48、其中α1和α2是用于平衡三个损失函数的超参数。
49、根据上述步骤,可以训练一个模型uwadt。当新的url到来时,同样会进行预处理并提取特征为词向量序列,然后输入到训练好的transformer模型中以获得深层特征。uwadt可根据深层特征与超球面中心的距离来预测url是否异常。
50、本发明解决了长序列数据的长期依赖问题并捕捉到复杂语义,用基于超球损失函数和对比损失函数优化模型,从而达到用较少的web日志数据且无异常标签去训练,也可以得到了很好的检测性能,并准确检测各种攻击。其使用基于transformer和对比学习的无监督web攻击检测方法检测web日志中的攻击。
- 还没有人留言评论。精彩留言会获得点赞!