一种适用于大数据下模型的高效特征选择方法与流程
本发明涉及数据处理,具体地说,是一种适用于大数据下模型的高效特征选择方法。
背景技术:
1、目前搜索推荐相关的算法应用前沿领域,数据量越来越大,特征维度也越来越高,样本和特征之间的关系也越来越复杂,模型学习各种特征参数,最终预测用户对各类场景下的点击概率。而那些早就过亿级别的数据和千万级别的特征,使得线上模型的训练和迭代越来越复杂,对我们的计算和存储带来挑战,同时过多的无效特征参数也会对模型效果带来损益。所以,节省计算资源的同时还能快速提高模型效果是业界非常关心的问题。
2、面对越来越复杂的数据和特征,现有的优化思路主要来自两方面:
3、一种是提升模型在实际中的计算能力,即增加部署的机器数量或者提升机器运行效率。这种虽然能短时间加快模型的迭代效率,一定量级的数据下能产出结果。但还是没解决冗余的无效特征的情况,而且随着数据量的继续增加,场景的复杂,机器成本进一步增加,越往后投入产出比越低。
4、另一种就是在模型输入部分就尽可能的减少无效特征,尽可能的输入关联的有效特征,也就是常见的特征选择。传统的特征选择要么非常依赖人工的专家经验,受人工主观因素影响较大,人工长期投入难以科学的保证理想效果,在不同场景下难以复用,人力投入成本较大;另一种方式就是可以先通过有些模型本身的特点去做特征选择,例如常见的树模型(xgboost,lgb),主要原理就是利用树的结构生成过程中,具有根据特征来进行节点分裂的特性,在训练过程中得到特征的相对重要性大小,从而只选择打分较高的特征输入到模型的输入端。但缺点是,现实情况下,各类特征不是完全独立的,很大概率有相互依赖的情况出现,这种方式难以找到全部的有效重要特征,有一定局限性,从而影响模型在实际场景中的应用效果。
技术实现思路
1、本发明的目的就是能解决在大数据量、高维特征的复杂场景下,模型训练迭代成本高、实际效果难以提升的问题。能够做到在降低机器和人力成本的同时,还能更快更好的的提升模型的迭代效果。
2、本发明采用的具体技术方案如下:
3、一种适用于大数据下模型的高效特征选择方法,主要包括两个模块设定为模块一和模块二,具体包括以下步骤:
4、模块一:
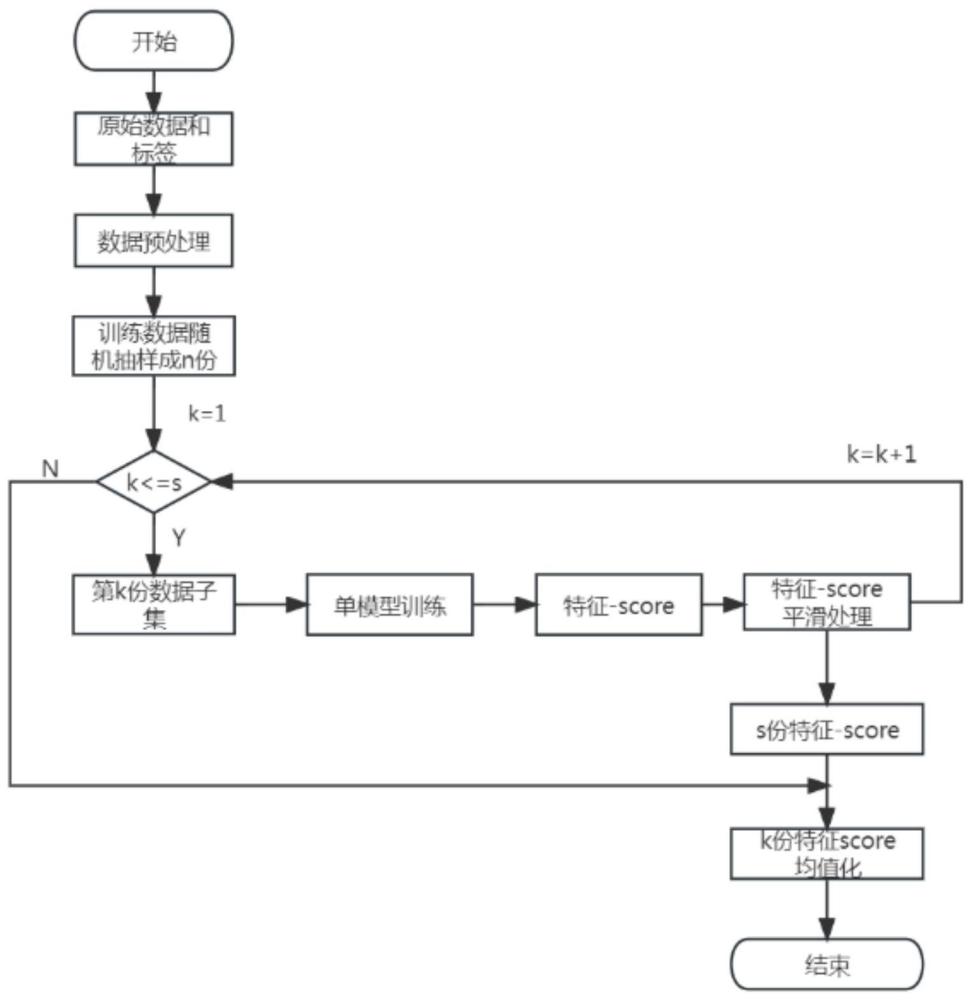
5、步骤1.1、拿到原始的数据(m行数据n个特征)和标签,对原始数据做清洗和特征工程,这中间大致包括:对乱码脏数据的过滤,不规则数据的规则化;连续特征分箱;离散特征热编码;交叉特征处理等等,总之尽可能的做好数据预处理,处理成模型干净可用的数据和特征。
6、步骤1.2、处理后的数据拆分成两部分:训练数据和预测数据(比例大约7:3),两部分数据集任意一个中的正负标签比例和拆分前的标签比例尽量保持一致。
7、步骤1.3、对整理好的训练数据抽样切分成s份,切分过程中有两个点要注意:一个是尽可能的保证每一份数据都是随机采样;另一个是考虑到后续对模型训练的影响,正负标签样本抽样尽可能1:1的比例(比例稍微有倾斜也不要倾斜太大)。
8、步骤1.4、对切分好的子数据集,取其中一份,送入到常见模型中进行训练。
9、步骤1.4.1、在这训练模型的选择,一般选择树模型xgboost,主要有以下几个优点:第一,训练速度快,适合训练时快速调整迭代达到一定的效果;第二,对机器资源的消耗相对别的模型(如神经网络)比较小;第三,xgboost在训练过程中,通过树在生成过程中通过对特征的选择来进行节点分裂,能相对科学的方法得到特征重要性打分,而且技术应用成熟,能调整适应满足各种算法指标(如准确率、召回率、auc指标等)。这几个优点非常适合本发明的应用场景。
10、步骤1.4.2、训练前设置好模型效果的评估指标,和场景最终目标一样,本发明场景下一般选用auc指标来作为最终的评估指标。
11、步骤1.4.3、在这一步中,训练一般不止一次,适当的调整模型参数,使得训练指标(auc)达到预期效果。
12、步骤1.5、模型训练好后,就能得到所有的特征和他的重要性打分(score)。考虑到数据子集和特征本身特性的影响,会使得特征score相互之间的特征重要性的高低程度被放大了。这时候需要解决特征score间的可比性的问题,本发明采用归一化的方式来平滑score之间的大小:
13、f′i=(fi-min(fi))/(max(fi)-min(fi))
14、其中,fi为任意一个特征归一化前的特征重要性分数,fi’为对应归一化之后特征重要性分数,max(fi)为归一化前最大的fi,min(fi)为归一化之后的最小fi。
15、步骤1.6、将每次平滑处理好的特征-score存储下来,如此就完成了一次数据子集的特征打分采集。
16、步骤1.7、继续下一次数据子集的特征打分采集,不断循环1.4-1.6的步骤操作,直到所有的数据子集全部处理完毕。
17、步骤1.8、将s份采集的数据子集的特征打分加和平均下,如此就完成了模块一的全部工作,具体公式如下:
18、
19、其中,fij代表第i个特征第j次训练的score。
20、模块二:
21、步骤2.1、拿到原始数据和标签,原始数据为m行数据n个特征,将数据特征对应的标签完全打乱,这儿不能直接简单的将正负标签完全取反,主要原因是标签完全取反之后,模型学习用到的特征系数只要也全部取反,就能得到和原来一样的拟合标签的效果,这样的后果是特征重要性score也和原来一模一样,失去了本方案预期想要的效果。
22、有如下方法可以在实际中应用:
23、a.通过rand(0,1)随机生成0或1的自然数x
24、b.新标签=if x=0then旧标签else(1-旧标签)end。
25、步骤2.2、重复模块一中的步骤1.1到步骤1.8,对数据预处理,对数据集切分成s份,依次进行训练得到特征score,归一化平滑处理,最后全部汇总均值化。(这里模型参数和模块一中参数保持一致)
26、步骤2.3、对标签打乱前后的两份特征-score集合,计算偏离度:
27、biasi=abs(f1i-f2i)/f1i
28、其中,biasi代表第i个特征的偏离度,f1i代表第i个特征在模块一中的score,f2i代表第i个特征在打乱标签后的score。实际场景下,越是和标签强相关的特征,在标签变化前后的偏离度越大,这也符合客观理论认知。
29、步骤2.4、特征偏离度bias按照从大到小一次排列,利用测试集数据,依次测试前k个特征在测试集上的指标效果,自动化操作可以初始化k=1,实际场景中也可以根据对数据场景的理解或者偏离度的大小初始化k=x。
30、步骤2.5、前k个特征输入模型得到的效果为第k次测试,一般来说,前面的特征对指标效果提升明显。本发明还需要将第k次的测试效果和第k-1次的作对比,低于一定的阀值threshold就终止测试。
31、步骤2.6、至此完成了所有的操作,这时候得到的特征数量为k个特征的特征组,就是本发明最终筛选出来的场景下的有效特征。可以将这组特征用在线上数据的实际预测中,线上模型的选择可以选择本发明用到的测试模型,也可以选择其他更加复杂的模型。根据实际场景的需要,都可以灵活选择。
32、本发明的有益效果:本发明可以非常精准的筛选出具体场景下全量的有效特征,适用于任意有监督的数据场景。本发明建立了自动化、智能化的流程机制,整个过程客观公正,不受人为主观因素影响,不会出现遗漏有效特征的情况;整个过程实现,运行成本很低,中间环节选用的模型和数据都可以灵活方便的调整。降低了线上模型的复杂度,较少了无效特征,提高了性能,为后续各类线上模型的快速有效迭代提供了非常强有力的支持。
- 还没有人留言评论。精彩留言会获得点赞!