一种敏感词识别方法、装置、设备及介质与流程
本技术涉及数据处理,尤其是涉及一种敏感词识别方法、装置、设备及介质。
背景技术:
1、互联网平台中的多数信息均是以文本形式呈现,如,人们可以通过互联网观看视频或者网页,同时可以通过评价系统发表评论,或者通过互联网进行对话等等。在用户通过对话系统或者评价系统输入文本内容时,可能存在一些不当的言论或者内容,不可避免的出现一些敏感词,那么,为了营造一个良好的互联网使用环境,对文本内容的监管显得尤为重要。
2、对文本内容的监管,多采用包括各类型敏感词的敏感词库进行敏感词的类型识别以及位置检测。随着人工智能的发展,也会有一些敏感词检测融入了大数据技术,如,通过n-gram模型进行新词发现扩充敏感词库,但是,构建以及维护敏感词库不仅浪费人力以及时间,部分敏感词有多重语义,容易误判正常语境下的内容,也对于一些敏感词变体很难检测出来。因此,常规的敏感词识别方式需要耗费大量人力,且识别效果较差。
技术实现思路
1、本技术目的是提供一种敏感词识别方法、装置、设备及介质,能够提高敏感词检测效果及效率。
2、本技术的上述申请目的一是通过以下技术方案得以实现的:
3、第一方面,提供了一种敏感词识别方法,包括:
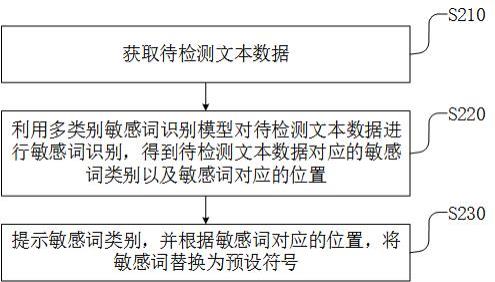
4、获取待检测文本数据;
5、利用多类别敏感词识别模型对所述待检测文本数据进行敏感词识别,得到所述待检测文本数据对应的敏感词类别以及敏感词对应的位置;
6、提示所述敏感词类别,并根据所述敏感词对应的位置,将敏感词替换为预设符号;
7、其中,所述多类别敏感词识别模型包括:膨胀卷积层、特征提取层、全连接层和crf层,所述利用多类别敏感词识别模型对所述待检测文本数据进行敏感词识别,包括:
8、确定所述待检测文本数据对应的词向量序列,所述词向量序列能够表示上下文信息;
9、根据所述词向量序列利用所述膨胀卷积层进行膨胀卷积操作,得到第一特征向量;
10、根据所述第一特征向量,利用所述特征提取层进行随机失活以及数据变换,得到第二特征向量;
11、基于所述第二特征向量利用所述全连接层进行敏感词多分类分析,得到所述待检测文本数据对应的若干敏感词类别;
12、根据所述第二特征向量,利用所述crf层,确定敏感词对应的位置以及对应的敏感词类别。
13、通过上述技术方案,采用idcnn-crf模型进行敏感词类型识别识别以及敏感词位置检测,将待检测文本数据转换成能够表示上下文信息的词向量序列后,利用膨胀卷积层对词向量序列进行特征向量提取;再通过特征提取层对提取得到的第一特征向量进行随机失活以及数据变换;然后通过全连接层对特征提取得到的第二特征向量进行敏感词多分类;再利用crf层对第二特征向量进行敏感词定位,进而,根据所述敏感词对应的位置进行敏感词脱敏,本方案提供的用于敏感词识别的多类别敏感词识别模型,能够通过扩大感受野的方式更好的理解上下文的语义,相较于相关技术中采用敏感词库的方式进行敏感词识别,能够快速精准的捕获敏感词以及其变体,提高了敏感词识别的准确度以及效率。
14、在一种可能的实现方式中,所述多类别敏感词识别模型训练过程,包括:
15、基于训练集训练初始多类别敏感词识别模型,得到训练后多类别敏感词识别模型,其中,训练集包括:多条敏感词训练样本以及各敏感词训练样本对应的标签,所述标签包括多类别标签和敏感词位置标签;
16、基于验证集,确定所述训练后多类别敏感词识别模型的损失值,并根据损失值和预设损失值调整所述训练后多类别敏感词识别模型的模型参数,进行迭代训练,得到所述多类别敏感词识别模型。
17、通过上述技术方案,基于训练集进行模型训练,然后基于验证集确定训练后多类别敏感词识别模型的损失值,再根据损失值来进行模型的参数修正,得到多类别敏感词识别模型。
18、在一种可能的实现方式中,还包括:
19、在迭代训练过程中,当连续预设轮次训练的损失值的变化幅度小于预设幅度阈值时,根据优化样本更新所述训练集和所述验证集,并根据更新后的训练集和验证集继续进行迭代训练。
20、通过上述技术方案,当连续预设轮次训练的损失值的变化幅度小于预设幅度阈值时,根据优化样本更新训练集和验证集,可提高对模型的优化效率和效果,避免过拟合。
21、在一种可能的实现方式中,所述利用多类别敏感词识别模型对所述待检测文本数据进行敏感词识别,得到所述待检测文本数据对应的敏感词类别以及敏感词对应的位置之前,还包括:
22、基于触发条件确定敏感词识别模式;所述触发条件至少包括以下一种:所述待检测文本数据的文本来源是否为网络来源时;识别精准度是否大于预设精准度阈值;检测到用户触发的指令中的指定识别模式;
23、当所述敏感词识别模式包括语义分析模式时,执行利用多类别敏感词识别模型对所述待检测文本数据进行敏感词识别,得到所述待检测文本数据对应的敏感词类别以及敏感词对应的位置;
24、当所述敏感词识别模式包括匹配模式时,利用敏感词字典树确定所述待检测文本数据对应的敏感词类别以及所述敏感词对应的位置。
25、通过上述技术方案,可支持至少两种敏感词识别模式,基于触发条件自动确定当前采用的识别模式,能够满足用户的多种需求。
26、在一种可能的实现方式中,当敏感词识别模式为匹配模式和语义分析模式时;
27、所述根据所述敏感词对应的位置,将敏感词替换为预设符号之后,还包括:
28、根据所述匹配模式确定所述待检测文本数据的补充敏感词及补充敏感词对应的位置;
29、根据所述补充敏感词对应的位置,将所述补充敏感词替换为预设符号。
30、通过上述技术方案,在同时选择匹配模式和语义分析模式后,可以利用语义分析模式对匹配模式进行补充或者替换,提高了敏感词识别的可靠性。
31、在一种可能的实现方式中,所述利用敏感词字典树确定所述待检测文本数据对应的敏感词类别以及所述敏感词对应的位置,包括:
32、利用敏感词字典树识别所述待检测文本数据的若干敏感词;
33、从若干敏感词中确定是否存在与预设关联词集匹配的成对敏感词;
34、根据所述成对敏感词对所述若干敏感词进行筛选,得到最终的有效敏感词及敏感词位置。
35、通过上述技术方案,设置成对敏感词,在通过匹配模式进行敏感词识别时只有命中成对敏感词才能确定最终的有效敏感词及敏感词位置,提高敏感词识别的准确率,减少敏感词漏检情况的发生。
36、在一种可能的实现方式中,所述获取待检测文本数据之后,还包括:
37、判断所述待检测文本数据的句子数量是否超过第一预设数量阈值;
38、若是,则对所述待检测文本数据按照句子之间的关联性以及第二预设数量阈值进行切片处理,得到多个文本切片;
39、所述利用多类别敏感词识别模型对所述待检测文本数据进行敏感词识别,得到所述待检测文本数据对应的敏感词类别以及敏感词对应的位置,包括:
40、利用多类别敏感词识别模型依次对所述多个文本切片进行敏感词识别,得到所述待检测文本数据对应的敏感词类别以及敏感词对应的位置。
41、通过上述技术方案,当待检测文本数据的句子数量超过第一预设数量阈值时,可能影响识别的准确性,通过按照第二预设数量阈值以及相邻句子之间的关联性对待检测文本数据进行切片处理,综合考虑句子语义以及数据大小,以提高敏感词识别的精准度。
42、第二方面,提供了一种敏感词识别装置,包括:
43、获取模块,用于获取待检测文本数据;
44、识别模块,用于利用多类别敏感词识别模型对所述待检测文本数据进行敏感词识别,得到所述待检测文本数据对应的敏感词类别以及敏感词对应的位置;
45、脱敏模块,用于提示所述敏感词类别,并根据所述敏感词对应的位置,将敏感词替换为预设符号;
46、其中,所述多类别敏感词识别模型包括:膨胀卷积层、特征提取层、全连接层和crf层,所述识别模块还用于:确定所述待检测文本数据对应的词向量序列,所述词向量序列能够表示上下文信息;根据所述词向量序列利用所述膨胀卷积层进行膨胀卷积操作,得到第一特征向量;根据所述第一特征向量,利用所述特征提取层进行随机失活以及数据变换,得到第二特征向量;基于所述第二特征向量利用所述全连接层进行敏感词多分类分析,得到所述待检测文本数据对应的若干敏感词类别;根据所述第二特征向量,利用所述crf层,确定敏感词对应的位置以及对应的敏感词类别。
47、第三方面,提供了一种电子设备,该电子设备包括:
48、一个或多个处理器;
49、存储器;
50、一个或多个应用程序,其中一个或多个应用程序被存储在存储器中并被配置为由一个或多个处理器执行,一个或多个应用程序配置用于:执行根据第一方面中任一可能的实现方式所示的敏感词识别方法对应的操作。
51、第四方面,提供了一种计算机可读存储介质,存储介质存储有至少一条指令、至少一段程序、代码集或指令集,至少一条指令、至少一段程序、代码集或指令集由处理器加载并执行以实现如第一方面中任一可能的实现方式所示的敏感词识别方法。
52、综上所述,本技术包括以下至少一种有益技术效果:
53、 1.采用idcnn-crf模型进行敏感词类型识别识别以及敏感词位置检测,将待检测文本数据转换成能够表示上下文信息的词向量序列后,利用膨胀卷积层对词向量序列进行特征向量提取;再通过特征提取层对提取得到的第一特征向量进行随机失活以及数据变换;然后通过全连接层对特征提取得到的第二特征向量进行敏感词多分类;再利用crf层对第二特征向量进行敏感词定位,进而,根据所述敏感词对应的位置进行敏感词脱敏,本方案提供的用于敏感词识别的多类别敏感词识别模型,能够通过扩大感受野的方式更好的理解上下文的语义,相较于相关技术中采用敏感词库的方式进行敏感词识别,能够快速精准的捕获敏感词以及其变体,提高了敏感词识别的准确度以及效率。
54、2.当待检测文本数据的句子数量超过第一预设数量阈值时,可能影响识别的准确性,通过按照第二预设数量阈值以及相邻句子之间的关联性对待检测文本数据进行切片处理,综合考虑句子语义以及数据大小,以提高敏感词识别的精准度。
- 还没有人留言评论。精彩留言会获得点赞!