二进制文件的漏洞检测方法及系统、电子设备、存储介质与流程
本发明涉及漏洞检测,特别地,涉及一种二进制文件的漏洞检测方法及系统、电子设备、计算机可读取的存储介质。
背景技术:
1、二进制可执行文件的安全问题一直是包括电力行业在内的全行业网络安全问题的热门话题,并一直得到广泛的关注。目前,市场上有大量针对应用程序源代码的白盒漏洞检测软件,可以较好地对源代码进行检测。但是,由于电力行业领域对软件的需求规模大、软件持续运行时间长、提供软件的厂商繁杂等特点,电力行业在运软件中有大量软件无法提供源代码用以检测漏洞,特别是对于需要长期运行但缺少厂商支持的遗留应用与外部厂商提供的专利软件,这些应用与软件均无法获取相应的源代码,且由于这些软件发明时间久或者开发过程中缺少安全管理等原因,导致其二进制文件中往往包含大量的安全漏洞。另外,目前的黑盒二进制检测也存在较多问题。例如,比较流行的模糊测试在对二进制文件进行检测时需要花费大量的时间、占用较高的系统资源,而且可检测的代码段有限,因此,这种方式只能针对特定的二进制文件,并且其检测完成度也无法得到保证。此外,也有将二进制文件通过逆向工程还原为汇编代码,但是,由于汇编代码复杂、可读性低等特性,市场上缺少成熟的、针对汇编代码的自动分析软件,因此汇编代码的漏洞分析需要经验丰富的安全工程师耗费大量时间进行分析。
2、现阶段,由于多年漏洞库的累计,以及二进制代码在反编译为汇编语言时,漏洞的特征代码会具备一定的规律性,因此,通过统计模型对汇编代码进行分析从而判断出可能存在漏洞的风险点成为了一个热门话题。其中,基于机器学习的模糊测试就是通过统计模型进行的一种改进,通过添加代码相似度的对比与原始的模糊测试相比具备更快的运行时间、更高的准确率,但是这种方法仍然需要代码的动态执行,并且还存在无法保证代码完成度、运行时间仍然难以估算等缺点。另外,一些基于机器学习的二进制漏洞检测方式由于提取的特征较为冗余,导致漏洞检测的耗费时间长、占用硬件资源多,在分析二进制漏洞时还会存在准确率与召回率偏低、多分类结果不理想等问题。
技术实现思路
1、本发明提供了一种二进制文件的漏洞检测方法及系统、电子设备、计算机可读取的存储介质,以解决现有基于机器学习的二进制漏洞检测方式存在的耗费时间长、占用硬件资源多、检测结果准确率低的技术问题。
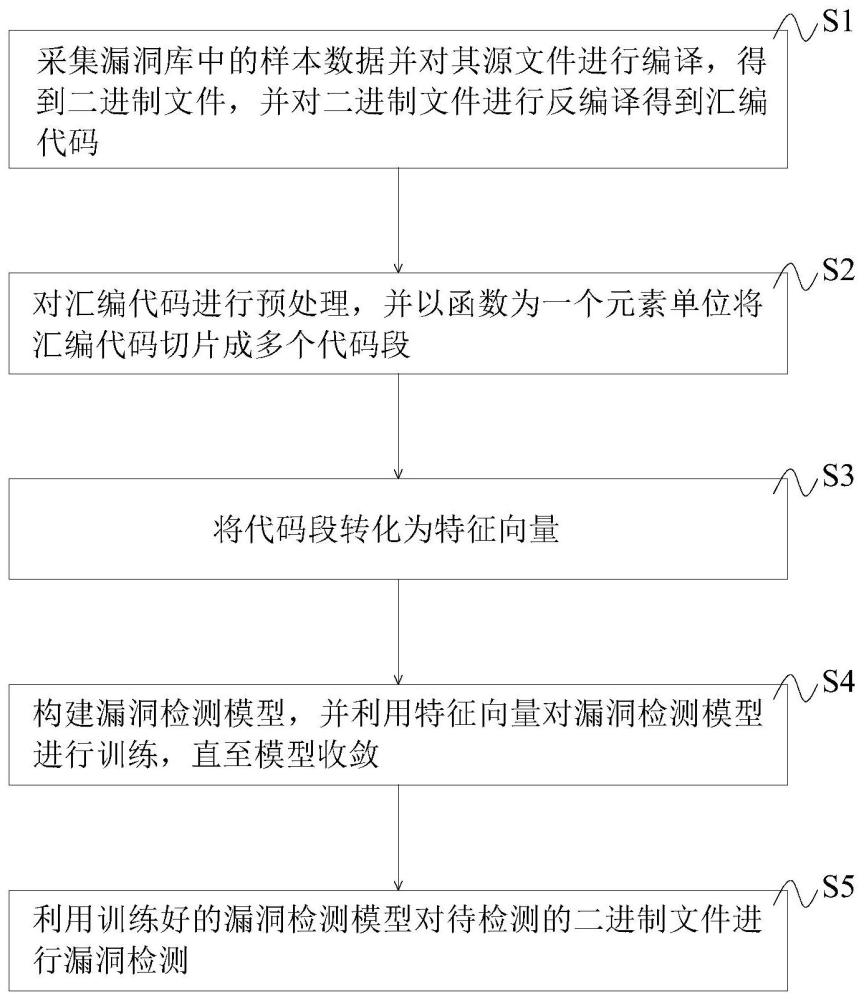
2、根据本发明的一个方面,提供一种二进制文件的漏洞检测方法,包括以下内容:
3、采集漏洞库中的样本数据并对其源文件进行编译,得到二进制文件,并对二进制文件进行反编译得到汇编代码;
4、对汇编代码进行预处理,并以函数为一个元素单位将汇编代码切片成多个代码段;
5、将代码段转化为特征向量;
6、构建漏洞检测模型,并利用特征向量对漏洞检测模型进行训练,直至模型收敛;
7、利用训练好的漏洞检测模型对待检测的二进制文件进行漏洞检测。
8、进一步地,所述对汇编代码进行预处理,并以函数为一个元素单位将汇编代码切片成多个代码段的过程包括以下内容:
9、对汇编代码中的无用文本进行清洗;
10、对清洗后的汇编代码进行格式改造,以函数为一个元素单位对整个文件进行存储。
11、进一步地,所述无用文本包括地址段、注释内容、不会对寄存器和标识符产生影响的汇编指令。
12、进一步地,所述对清洗后的汇编代码进行格式改造,以函数为一个元素单位对整个文件进行存储的过程包括以下内容:
13、对清洗后的汇编代码文本逐行读取,并在每一行后添加换行符作为标记,再判断每一行中属于变量的单词,并对其添加带有序号的标记,判断本行代码是否与上一行代码同属一个函数,若是则将本行代码与上一行代码合并为一行,从而以函数为一个元素单位对整个文件进行存储。
14、进一步地,在将汇编代码切片成多个代码段之后还包括以下内容:
15、对每个代码段进行分析,并根据每个代码段中是否存在漏洞以及漏洞种类添加相应标签。
16、进一步地,所述将代码段转化为特征向量的过程包括以下内容:
17、对于所有代码段中的全部单词进行排序,并使用一个1×n的单列矩阵代表一个单词,对于第i个单词,其单列矩阵的第i列的位置为1、其余位置为0,根据每个代码段所包含的单词将每个代码段转换为数字特征向量;
18、采用词袋模型对数字特征向量进行精简,以减少数字特征向量中的无用特征值。
19、进一步地,所述利用特征向量对漏洞检测模型进行训练的过程包括以下内容:
20、将数字特征向量中的代码特征输入cnn网络中进行代码特征值的提取,并将中间结果与数字特征向量中的函数类型特征一并输入至blstm网络进行类型特征值的提取,再对代码特征值与类型特征值进行融合,基于融合后的特征值进行softmax分类。
21、另外,本发明还提供一种二进制文件的漏洞检测系统,包括:
22、样本采集模块,用于采集漏洞库中的样本数据并对其源文件进行编译,得到二进制文件,并对二进制文件进行反编译得到汇编代码;
23、预处理模块,用于对汇编代码进行预处理,并以函数为一个元素单位将汇编代码切片成多个代码段;
24、向量转化模块,用于将代码段转化为特征向量;
25、模型训练模块,用于构建漏洞检测模型,并利用特征向量对漏洞检测模型进行训练,直至模型收敛;
26、漏洞检测模块,用于利用训练好的漏洞检测模型对待检测的二进制文件进行漏洞检测。
27、另外,本发明还提供一种电子设备,包括处理器和存储器,所述存储器中存储有计算机程序,所述处理器通过调用所述存储器中存储的所述计算机程序,用于执行如上所述的方法的步骤。
28、另外,本发明还提供一种计算机可读取的存储介质,用于存储对二进制文件进行漏洞检测的计算机程序,所述计算机程序在计算机上运行时执行如上所述的方法的步骤。
29、本发明具有以下效果:
30、本发明的二进制文件的漏洞检测方法,先采集漏洞库中的样本数据并对其源文件进行编译,以得到训练神经网络所需的二进制文件,再将二进制文件反编译为汇编代码,以便于对二进制文件进行分析和处理。然后对汇编代码进行预处理,剔除了大量无用文本,大大提高了模型的训练速度和训练质量,并以函数为一个元素单位将汇编代码切片呈多个代码段,将属于同一函数的所有代码均保存在一行中,保留了各指令间位置特征的同时对变量进行了同一化处理,在保留变量关系的同时减少了因变量名导致的特征矩阵冗余,大大提高了模型的训练时间和训练精度。然后,将代码段转换为特征向量,以符合神经网络模型的输入格式,并以函数作为训练最小单元进行特征值提取,大大提高了模型的训练效率和准确率。最后,利用训练好的漏洞检测模型对待检测的二进制文件进行漏洞检测,具有检测结果准确率高、占用硬件资源少、耗费时间短的优点。
31、另外,本发明的二进制文件的漏洞检测系统同样具有上述优点。
32、除了上面所描述的目的、特征和优点之外,本发明还有其它的目的、特征和优点。下面将参照图,对本发明作进一步详细的说明。
- 还没有人留言评论。精彩留言会获得点赞!