一种具有隐私保护的个性化联邦学习方法、装置和介质
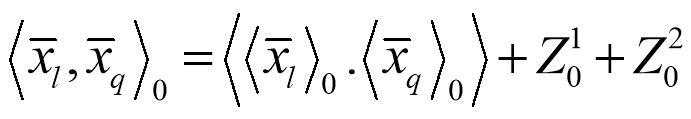
本发明涉及一种具有隐私保护的个性化联邦学习方法、装置和介质,属于云计算、联邦学习。
背景技术:
1、在传统的集中式机器学习中,参与培训的客户通常需要将本地培训数据上传到中央服务器。由于数据远离本地,数据安全和隐私很难保护。谷歌在2016年提出了联邦学习,可以在不上传原始数据的情况下完成模型的训练。具体来说,参与的客户端需要上传fl中的梯度或模型参数。由于其隐私保护得到提升,fl被广泛应用于金融,医疗和交通运输。当客户端数据为独立同分布时,平均参数聚合能够生成一个对所有客户端都近似最优的模型。然而,传统fl的主要缺点是,当涉及的数据集是non-iid的,也称为客户端漂移时,全局模型可能会出现缓收敛速度慢甚至是较差的模型性能。在这种情况下,全局模型可能会偏离局部最优模型。在数据异构场景中,通过传统的联邦学习生成的全局模型并不能很好的推广到每一个客户端。因此个性化的联邦学习被提出来应对数据异构的挑战。如何在保护客户机数据隐私的同时,有效地处理概念偏移数据,是一个值得注意的问题。在本发明中我们提出了基于隐私保护自适应聚类的个性化联邦学习框架来应对上述挑战。
技术实现思路
1、本发明目的是提供了一种具有隐私保护的个性化联邦学习方法、装置和介质,提高模型的性能,使其适应自身的个性化数据,并实现对于客户端隐私的保护。
2、本发明为实现上述目的,通过以下技术方案实现:
3、步骤1:将计算服务器拆分为两个不相互勾结的计算服务器,并利用算术秘密共享技术在训练过程中对私密数据进行秘密共享。
4、通过计算服务器发布联邦学习任务,将全局模型发送给客户端,客户端接收到全局模型根据进行更新,并根据本地平均梯度算法获取本地梯度向量。
5、步骤2:将所有客户端作为一个客户端集群,通过聚类算法根据本地梯度向量将客户端集群分为两个子节点客户端集群。
6、步骤3:将各个子节点客户端集群通过个性化本地训练算法训练,并将在总通信轮数下的所有子节点客户端集群的模型准确率返回到梯度聚类算法中。
7、梯度聚类算法比较当前最新划分的子节点客户端集群与其父客户端集群准确率是否小于准确率阈值,迭代步骤3直至所有子节点客户端集群准确率与其父客户端集群准确率的差均小于阈值。
8、步骤4:取准确率最高的那一次迭代中的客户端集群划分方式,通过个性化本地训练算法为每个客户端集群训练个性化学习模型。
9、步骤5:计算服务器获取每个客户端集群训练完成的个性化学习模型,处理当前任务。
10、优选的,所述本地平均梯度算法具体如下:
11、第个客户端对全局模型进行迭代更新,执行梯度下降更新,得到本地模型最后一层的梯度。
12、并将梯度累加到得到,根据计算平均梯度,其中表示本地更新周期,如果当前交互轮数等于总的交互轮数减一,则将平均梯度返回给计算服务器。
13、将更新完成的本地模型上传给计算服务器进行聚合,得到聚合后的全局模型,聚合方式如下:
14、,
15、表示参与训练的客户端总的数量,表示第个客户端本地模型参数。
16、在交互结束后,客户端在本地计算个性化梯度,客户端上的梯度计算为:
17、,
18、其中,表示第个客户端在第次迭代中最后一层的梯度值,表示平均后的梯度,根据所有客户端本地梯度建立本地梯度向量。
19、优选的,所述聚类算法为梯度聚类算法根据本地梯度向量将客户端集群分为两个子节点客户端集群,具体如下:
20、取所有客户端或上一次迭代客户端集群作为父节点客户端集群,并设定准确率阈值和总通信轮数,始化子节点客户群集。
21、通过本地平均梯度算法计算父节点客户端集群在总通信轮数下的准确率。
22、。
23、使用二元聚类算法将父节点客户端集合划分为两个子节点客户端群集。
24、使用个性化本地训练算法计算子节点客户端群集在总通信轮数下的准确率和,如果且,则停止对当前客户集群进行分组,并返回当前子节点客户集群,否则,继续调用梯度聚类算法进行进一步分组。
25、所述总通信轮数通过一下方式计算:
26、,其中,其中t表示允许模型达到完全收敛所需的最小通信轮数。
27、优选的,所述二元聚类算法中使用余弦距离定义两客户端梯度数据,所述余弦距离计算公式如下:
28、,
29、其中,、表示任意两客户端梯度数据,表示和之间的内积,表示的向量范数,表示的向量范数。
30、优选的,所述个性化本地训练算法训练过程具体如下:
31、获取子节点客户端集群的总通信轮数,集群大小,计算服务器初始化全局模型。
32、对客户端集群进行次迭代更新,其中每个客户端在迭代更新中需要计算服务器发送全局模型给客户端。
33、然后客户端使用接收到的全局模型进行本地模型更新操作。
34、更新操作过程如下:
35、通过一下公式计算平均嵌入向量,
36、,
37、其中,表示包含第类所有训练样本的数据子集,表示为样本的嵌入向量。
38、根据本地损失函数,对本地模型进行迭代更新,迭代完成后,返回第个客户端在次迭代的本地模型参数。
39、通过以下公式更新本次迭代的全局模型,
40、,
41、其中,表示集群大小,迭代结束后客户端根据本地测试集获取本地模型准确率,并将其发送至计算服务器。
42、计算服务器计算得到准确率,并将其与当前的客户端集群的本地模型返回给客户端。
43、本地损失函数如下:,
44、其中,表示本地模型的神经网络结构的输出结果,表示对应的标签,表示超参数,表示第个类别的嵌入向量。为了使嵌入向量能够接近平均嵌入向量并最小化预测误差损失,在本地损失中添加一个正则化项。
45、优选的,还包括本地平均梯度算法和个性化的本地训练算法的隐私保护,具体方式如下:
46、客户端使用可加性秘密共享对模型参数进行分割,通过安全通道将分割的秘密份额传输给两个计算服务器,计算服务器使用安全聚合协议完成模型参数聚合,完成模型聚合后,计算服务器向全局添加高斯噪声,并将其发送给客户端。
47、优选的,所述计算服务器使用安全聚合协议完成模型参数聚合,具体方式如下:
48、在客户端上传模型参数值前,配对映射将模型参数从实数域映射到,表示模的整数环,为一个大整数。
49、客户端生成一个随机数作为第一个秘密份额,配对计算第二个秘密份额,其中,表示第i个客户端本地的模型参数,表示一个随机整数,客户端将、分别发送到两个计算服务器、。
50、计算服务器从不同客户端接收秘密份额并执行安全聚合协议,两个计算服务器分别聚合各自的秘密份额和,其中,。将发送给,用于获取全局聚合模型,。
51、优选的,所述聚类算法为安全二进制聚类算法,具体方式如下:
52、在执行客户端聚类前,客户端对梯度进行归一化处理得到梯度,具体公式如下:
53、,
54、客户端通过加法秘密共享将梯度拆分为两个秘密份额,将秘密份额上传给计算服务器、,计算服务器、使用安全二进制聚类算法实现客户端聚类。
55、所述安全二进制聚类算法,具体方式如下:
56、通过梯度聚类算法将一个父节点客户端集群生成两个子节点客户端集群。
57、计算服务器生成两个向量和,分别为单位向量和的第一个秘密共享,生成两个向量和,分别为单位向量和的第二个秘密共享。
58、计算服务器、请求标量积协议计算客户端的梯度与聚类中心之间的标量积,使用标量积计算余弦距离。
59、计算服务器根据余弦距离确定客户端属于客户端集群,在所有梯度都被分配到两个客户端集群后,计算服务器、根据以下公式计算两个新的聚类中心:
60、,,
61、其中,表示当前客户端集群梯度的平均值,表示第个客户端的梯度。
62、对客户端集群进行安全计算,安全地计算当前客户端集群中梯度的平均值。
63、计算服务器、继续迭代这个过程,直到聚类中心不再发生变化,并获得客户的最终聚类结果。
64、优选的,所述标量积协议如下:
65、计算服务器持有和,分别为向量的第一个秘密份额,表示整数值是维的模的整数环,计算服务器持有和,分别为向量的第二个秘密份额。
66、协议生成,给计算服务器,生成以及,给计算服务器,并满足,、表示整数值是维的模的整数环中的向量,、表示模的整数环中的数值。
67、客户端向量进行归一化,使用定点表示将从实数域映射到,计算标量积,具体过程如下:
68、计算服务器发送到计算服务器,计算服务器收到并计算,计算服务器发送给计算服务器,计算服务器收到计算。
69、计算服务器向计算服务器发送,计算服务器收到并计算,计算服务器发送给计算服务器,计算服务器收到计算。
70、计算服务器计算第一个部分的标量积,计算服务器计算第二个部分的标量积。
71、计算服务器将发送给计算服务器,计算服务器将标量积与标量积相加得到标量积。
72、本发明的优点在于:本发明有效地解决数据的概念偏移,本发明提出了一个个性化的联邦学习框架。为了进一步提高模型的性能,使其适应自身的个性化数据,该方案采用了自适应聚类和正则化方法。利用秘密共享和差分隐私技术来实现对于客户端隐私的保护,以抵御潜在的隐私攻击。
- 还没有人留言评论。精彩留言会获得点赞!