一种知识迁移的点云人体姿态估计模型的训练和识别方法
本技术涉及计算机,具体而言,涉及一种知识迁移的点云人体姿态估计模型的训练和识别方法。
背景技术:
1、人体姿态估计是多数研究方向的基础,在实际应用中,人体姿态估计常常转化为对人体关键点的预测,例如行为分析、步态识别以及人物跟踪等,均需要结合精确的关键点坐标位置进行进一步分析和判断。在目前的技术方案中,常采用毫米波雷达获取对应的点云数据以进行人体姿态估计,然而,大部分单芯片雷达存在雷达天线少、点云密度稀疏等问题,基于单芯片雷达所获取的点云数据进行姿态估计使得识别结果的准确度较低。由此,如何在现有毫米波雷达获取的稀疏点云的基础上,提高人体姿态识别结果的准确度成为了亟待解决的技术问题。
技术实现思路
1、本技术的实施例提供了一种知识迁移的点云人体姿态估计模型的训练和识别方法,进而至少在一定程度上可以在现有毫米波雷达获取的稀疏点云的基础上,提高人体姿态识别结果的准确度。
2、本技术的其他特性和优点将通过下面的详细描述变得显然,或部分地通过本技术的实践而习得。
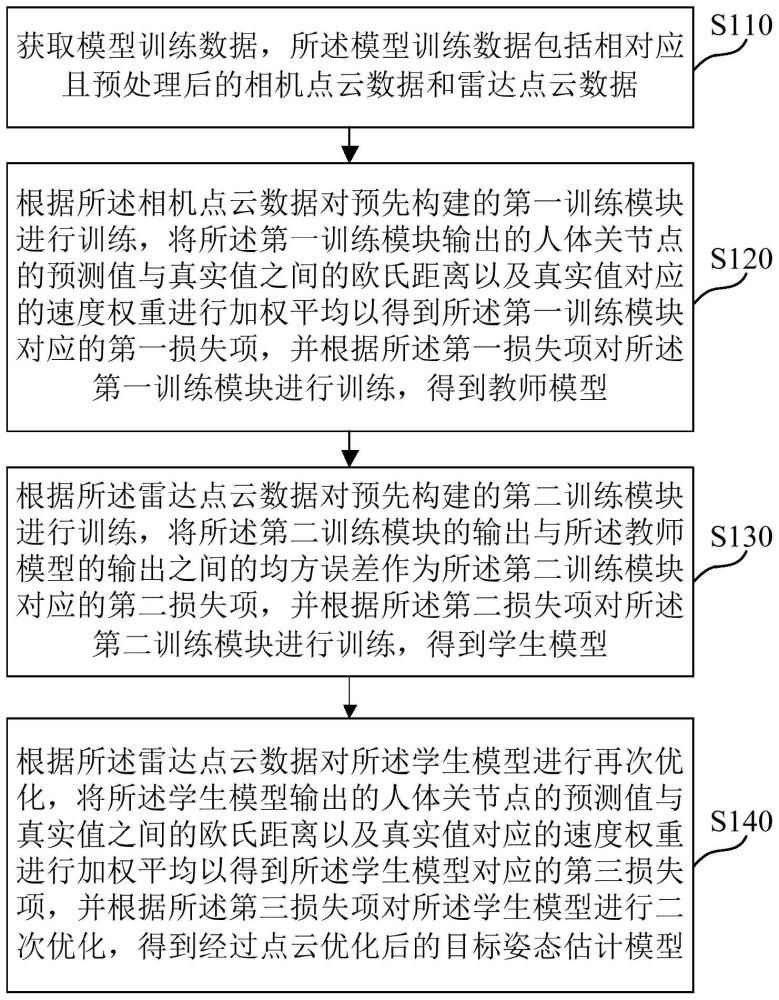
3、根据本技术实施例的一个方面,提供了一种知识迁移的点云人体姿态估计模型的训练方法,包括:
4、获取模型训练数据,所述模型训练数据包括相对应且预处理后的相机点云数据和雷达点云数据;
5、根据所述相机点云数据对预先构建的第一训练模块进行训练,将所述第一训练模块输出的人体关节点的预测值与真实值之间的欧氏距离以及真实值对应的速度权重进行加权平均以得到所述第一训练模块对应的第一损失项,并根据所述第一损失项对所述第一训练模块进行训练,得到教师模型;
6、根据所述雷达点云数据对预先构建的第二训练模块进行训练,将所述第二训练模块的输出与所述教师模型的输出之间的均方误差作为所述第二训练模块对应的第二损失项,并根据所述第二损失项对所述第二训练模块进行训练,得到学生模型;
7、根据所述雷达点云数据对所述学生模型进行再次优化,将所述学生模型输出的人体关节点的预测值与真实值之间的欧氏距离以及真实值对应的速度权重进行加权平均以得到所述学生模型对应的第三损失项,并根据所述第三损失项对所述学生模型进行二次优化,得到经过点云优化后的目标姿态估计模型。
8、根据本技术实施例的一个方面,提供了一种点云人体姿态的识别方法,该方法包括:
9、获取待识别雷达点云数据;
10、将所述待识别雷达点云数据输入至预先训练完成的姿态估计模型,以使所述姿态估计模型输出对应的姿态识别结果,所述姿态估计模型由如上述实施例所述的训练方法训练得到。
11、根据本技术实施的一个方面,提供一种人体姿态估计的网络模型,包括:获取训练数据集,在原有空间信息基础上,添加一维时间信息,构建时间连续的点云时空序列数据,以确知毫米波点云所处的时间;利用denseblock增加点云通道数,提取点云帧特征,结合特征连接的方法共同作为下一层的输入;利用点4d卷积对点云视频中的时空局部结构进行编码,用于嵌入点云视频中呈现的时空局部结构,将位置信息结合到点云特征中,然后transformer通过对嵌入的局部特征进行自注意力机制来捕获整个视频中的外观和运动信息,从而更好地提取点云的动态特征;将经过p4transformer处理的点云数据根据先前计算保存的每帧点云数量列表进行点云数据分割,确定每帧点云后计算每一帧的最大值、最小值和平均值,通过这种混合池化连接的方法强调点云特征并固定每帧点数,进而最终完成t帧长度为c的点云特征的提取,为后续姿态预测网络提供点云特征。利用相机点云信息训练ttransformer网络;接着利用ttransformer网络训练stransformer网络的前半部分,即特征提取部分,先由ttransformer网络通过相机点云提取特征信息,然后stransformer网络利用与相机点云同源的毫米波点云提取特征信息,优化两者特征之间的差值;最后利用毫米波点云信息微调stransformer网络,通过双流数据融合输出基于骨骼点表示的3d人体姿态。
12、根据本技术实施例的一个方面,提供了一种知识迁移的点云人体姿态估计模型的训练装置,包括:
13、第一获取模块,用于获取模型训练数据,所述模型训练数据包括相对应且预处理后的相机点云数据和雷达点云数据;
14、模型训练模块,用于根据所述相机点云数据对预先构建的第一训练模块进行训练,将所述第一训练模块输出的人体关节点的预测值与真实值之间的欧氏距离以及真实值对应的速度权重进行加权平均以得到所述第一训练模块对应的第一损失项,并根据所述第一损失项对所述第一训练模块进行训练,得到教师模型;根据所述雷达点云数据对预先构建的第二训练模块进行训练,将所述第二训练模块的输出与所述教师模型的输出之间的均方误差作为所述第二训练模块对应的第二损失项,并根据所述第二损失项对所述第二训练模块进行训练,得到学生模型;根据所述雷达点云数据对所述学生模型进行再次优化,将所述学生模型输出的人体关节点的预测值与真实值之间的欧氏距离以及真实值对应的速度权重进行加权平均以得到所述学生模型对应的第三损失项,并根据所述第三损失项对所述学生模型进行二次优化,得到经过点云优化后的目标姿态估计模型。
15、根据本技术实施例的一个方面,提供了一种点云人体姿态的识别装置,包括:
16、第二获取模块,用于获取待识别雷达点云数据;
17、数据处理模块,用于将所述待识别雷达点云数据输入至预先训练完成的姿态估计模型,以使所述姿态估计模型输出对应的姿态识别结果,所述姿态估计模型由上述实施例所述的训练方法训练得到。
18、根据本技术实施例的一个方面,提供了一种计算机可读介质,其上存储有计算机程序,所述计算机程序被处理器执行时实现如上述实施例中所述的知识迁移的点云人体姿态估计模型的训练方法、点云人体姿态的识别方法。
19、根据本技术实施例的一个方面,提供了一种电子设备,包括:一个或多个处理器;存储装置,用于存储一个或多个程序,当所述一个或多个程序被所述一个或多个处理器执行时,使得所述一个或多个处理器实现如上述实施例中所述的基于知识迁移的点云人体姿态估计模型的训练方法、点云人体姿态的识别方法。
20、根据本技术实施例的一个方面,提供了一种计算机程序产品或计算机程序,该计算机程序产品或计算机程序包括计算机指令,该计算机指令存储在计算机可读存储介质中。计算机设备的处理器从计算机可读存储介质读取该计算机指令,处理器执行该计算机指令,使得该计算机设备执行上述实施例中提供的知识迁移的点云人体姿态估计模型的训练方法、点云人体姿态的识别方法。
21、在本技术的一些实施例所提供的技术方案中,通过获取模型训练数据,该模型训练数据包括相对应且预处理后的相机点云数据和雷达点云数据,根据相机点云数据对预先构建的第一训练模块进行训练,将第一训练模块输出的人体关节点的预测值与真实值之间的欧氏距离以及真实值对应的速度权重进行加权平均以得到第一训练模块对应的第一损失项,并根据第一损失项对第一训练模块进行训练,得到教师模型,接着,根据雷达点云数据对预先构建的第二训练模块进行训练,将第二训练模块的输出与教师模型的输出之间的均方误差作为第二神经网络对应的第二损失项,并根据第二损失项对第二训练模块进行训练,获得更加精确的姿态估计模型,即学生模型,再根据雷达点云数据对学生模型进行再次优化,并将学生模型输出的人体关节点的预测值与真实值之间的欧氏距离以及真实值对应的速度权重进行加权平均以得到学生模型对应的第三损失项,根据该第三损失项对学生模型进行二次优化,以得到目标姿态估计模型。由此,采用双路数据(即相机点云数据和雷达点云数据)输入融合训练得到的目标姿态估计模型,在实际应用过程中,可以在仅获取毫米波雷达获取的点云数据的基础上,提高姿态识别结果的准确度。
22、另外,根据速度优化后的mpjpe(平均(每)关节位置误差)作为损失项进行模型训练,在人体运动时若只有部分骨骼点发生运动,则能够增加对有速度的运动部分的骨骼点的关注,进而提高了姿态识别结果的准确度。
23、应当理解的是,以上的一般描述和后文的细节描述仅是示例性和解释性的,并不能限制本技术。
- 还没有人留言评论。精彩留言会获得点赞!