基于注意力增强的文本处理方法、装置、设备和介质与流程
本发明属于自然语言处理中的实体识别领域,涉及一种基于注意力增强的医学文本处理方法、装置、设备和介质。
背景技术:
1、随着信息技术的飞速发展,大数据时代的医疗服务和医疗信息系统以数字化的形式呈现了患者治疗的全过程,形成了海量的数据形式丰富、结构复杂且词汇构成专业化的医学文本数据,这些非结构化的医学文本使信息的可读性变差,难以分析和处理,可用性低。因此,进行医学文本挖掘已经成为获取有用信息的重要途径。医学文本挖掘最重要的一步即是医学命名实体识别,通过识别医学文本中重要的医学相关实体,例如疾病、药物和手术等,并进一步分析这些实体之间的关系,从而加快人们对医学文本核心内容的理解和把握,并为后续构建医学知识图谱以及指导临床诊疗决策提供了坚实的数据基础。然而,在实现本发明的过程中,发明人发现传统的医学文本的实体识别技术仍然存在着识别准确率不够高的技术问题。
技术实现思路
1、针对上述传统方法中存在的问题,本发明提出了一种基于注意力增强的文本处理方法、一种基于注意力增强的文本处理装置、一种计算机设备和一种计算机可读存储介质,能够大幅提高医学文本的实体识别准备率。
2、为了实现上述目的,本发明实施例采用以下技术方案:
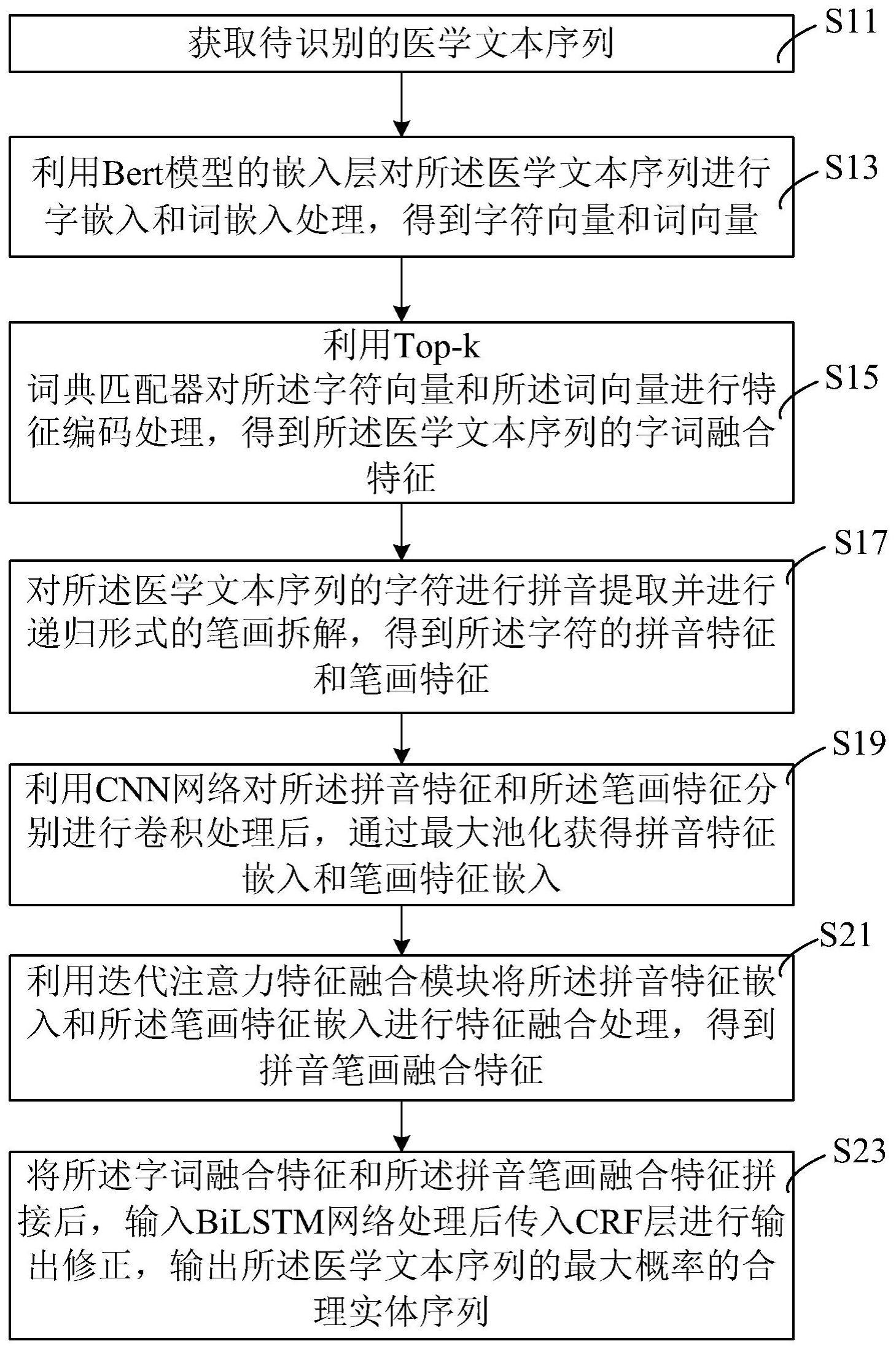
3、一方面,提供一种基于注意力增强的文本处理方法,包括步骤:
4、获取待识别的医学文本序列;
5、利用bert模型的嵌入层对医学文本序列进行字嵌入和词嵌入处理,得到字符向量和词向量;
6、利用top-k词典匹配器对字符向量和词向量进行特征编码处理,得到医学文本序列的字词融合特征;
7、对医学文本序列的字符进行拼音提取并进行递归形式的笔画拆解,得到字符的拼音特征和笔画特征;
8、利用cnn网络对拼音特征和笔画特征分别进行卷积处理后,通过最大池化获得拼音特征嵌入和笔画特征嵌入;
9、利用迭代注意力特征融合模块将拼音特征嵌入和笔画特征嵌入进行特征融合处理,得到拼音笔画融合特征;
10、将字词融合特征和拼音笔画融合特征拼接后,输入bilstm网络处理后传入crf层进行输出修正,输出医学文本序列的最大概率的合理实体序列。
11、在其中一个实施例中,利用top-k词典匹配器对字符向量和词向量进行特征编码处理,得到医学文本序列的字词融合特征的步骤,包括:
12、将词向量进行非线性映射,与字符向量进行维度对齐;
13、利用双线性注意分数计算方式,计算每个词向量对应词语的双线性注意力分数矩阵;
14、对双线性注意力分数矩阵进行top-k分数筛选,得到词向量的稀疏注意力分数矩阵和每个词语所占权重;
15、对于每个字符向量所匹配到的每个词语所占权重,对词向量进行加权求和,得到每个字符向量的加权词语向量;
16、将字符向量与匹配的加权词语向量相加,得到特征融合向量后经过随机失活、层归一化和残差连接操作,输出字词融合特征。
17、在其中一个实施例中,拼音特征包括字符的拼音和声调。
18、在其中一个实施例中,利用迭代注意力特征融合模块将拼音特征嵌入和笔画特征嵌入进行特征融合处理,得到拼音笔画融合特征的步骤,包括:
19、将cnn编码的拼音特征嵌入和笔画特征嵌入相加后,输入迭代注意力特征融合模块的多尺度通道注意力模块;
20、将多尺度通道注意力模块的输出再次输入多尺度通道注意力模块,得到拼音笔画输出权重;
21、将拼音笔画输出权重与输入的拼音特征嵌入和笔画特征嵌入进行加权求和,得到拼音笔画融合特征。
22、另一方面,还提供一种基于注意力增强的文本处理装置,包括:
23、文本获取模块,用于获取待识别的医学文本序列;
24、嵌入处理模块,用于利用bert模型的嵌入层对医学文本序列进行字嵌入和词嵌入处理,得到字符向量和词向量;
25、特征编码模块,用于利用top-k词典匹配器对字符向量和词向量进行特征编码处理,得到医学文本序列的字词融合特征;
26、拼画特征模块,用于对医学文本序列的字符进行拼音提取并进行递归形式的笔画拆解,得到字符的拼音特征和笔画特征;
27、特征卷积模块,用于利用cnn网络对拼音特征和笔画特征分别进行卷积处理后,通过最大池化获得拼音特征嵌入和笔画特征嵌入;
28、特征融合模块,用于利用迭代注意力特征融合模块将拼音特征嵌入和笔画特征嵌入进行特征融合处理,得到拼音笔画融合特征;
29、拼接输出模块,用于将字词融合特征和拼音笔画融合特征拼接后,输入bilstm网络处理后传入crf层进行输出修正,输出医学文本序列的最大概率的合理实体序列。
30、在其中一个实施例中,特征编码模块包括:
31、对齐子模块,用于将词向量进行非线性映射,与字符向量进行维度对齐;
32、分数子模块,用于利用双线性注意分数计算方式,计算每个词向量对应词语的双线性注意力分数矩阵;
33、权重子模块,用于对双线性注意力分数矩阵进行top-k分数筛选,得到词向量的稀疏注意力分数矩阵和每个词语所占权重;
34、加权子模块,用于对于每个字符向量所匹配到的每个词语所占权重,对词向量进行加权求和,得到每个字符向量的加权词语向量;
35、融合子模块,用于将字符向量与匹配的加权词语向量相加,得到特征融合向量后经过随机失活、层归一化和残差连接操作,输出字词融合特征。
36、在其中一个实施例中,拼音特征包括字符的拼音和声调。
37、在其中一个实施例中,特征融合模块包括:
38、特征输入子模块,用于将cnn编码的拼音特征嵌入和笔画特征嵌入相加后,输入迭代注意力特征融合模块的多尺度通道注意力模块;
39、重输入子模块,用于将多尺度通道注意力模块的输出再次输入多尺度通道注意力模块,得到拼音笔画输出权重;
40、加权融合子模块,用于将拼音笔画输出权重与输入的拼音特征嵌入和笔画特征嵌入进行加权求和,得到拼音笔画融合特征。
41、又一方面,还提供一种计算机设备,包括存储器和处理器,存储器存储有计算机程序,处理器执行计算机程序时实现上述的基于注意力增强的文本处理方法的步骤。
42、再一方面,还提供一种计算机可读存储介质,其上存储有计算机程序,计算机程序被处理器执行时实现上述的基于注意力增强的文本处理方法的步骤。
43、上述技术方案中的一个技术方案具有如下优点和有益效果:
44、上述基于注意力增强的文本处理方法、装置、设备和介质,通过获取待识别的医学文本序列后,一方面利用bert模型的嵌入部分将其进行序列分割后映射成向量形式,并通过top-k词典匹配器进行特征编码处理,为每个字符匹配词向量并进行特征融合,以对引入的词汇信息进行筛选,将低相关性的词汇进行屏蔽,使模型注意力集中在最有价值的词汇上。另一方面通过cnn网络对拼音特征和笔画特征进行卷积处理,并利用迭代注意力特征融合模块将两种特征融合后与字词融合特征进行特征拼接再一同输入bilstm网络进行预测输出,最后传入crf层对bilstm网络的输出进行修正,得到该医学文本序列的最大概率的合理实体序列。
45、相比于传统技术,提出了基于top-k机制的注意力增强lebert模型,对引入的词汇信息进行筛选,将低相关性的词汇进行屏蔽,使模型注意力集中在最有价值的词汇上;通过cnn模型对字符的拼音、笔画特征进行卷积,并通过迭代注意力特征融合模块将两者进行融合后与lebert模型的输出进行拼接,让模型能有效进一步挖掘字符所蕴含的语义信息,从而大幅提高医学文本的实体识别准备率。
- 还没有人留言评论。精彩留言会获得点赞!