一种面向大场景的群体轨迹预测方法
本发明属于群体分析,涉及一种面向大场景的群体轨迹预测方法。
背景技术:
1、群体轨迹预测是指利用各种技术和方法对群体移动模式和趋势进行预测和分析,群体轨迹预测需要处理海量的位置数据,这些数据可能来自各种传感器、gps跟踪设备、社交媒体等多种途径。涉及的应用领域非常广泛,包括交通管理、公共安全、城市规划、广告营销等领域。
2、例如,交通管理是群体轨迹预测的一个重要应用领域。通过对交通流量数据的分析和预测,可以帮助交通管理部门了解交通状况、制定交通疏导方案、预测交通事故等。群体轨迹预测技术可以通过分析历史交通流量数据来预测未来的交通流量,从而为交通管理部门提供决策支持。此外,群体轨迹预测技术还可以通过监测人群的移动轨迹来预测拥堵区域和时间,以便采取相应的措施来缓解交通压力。公共安全也是群体轨迹预测的重要应用领域之一。通过对群体移动轨迹的监测和分析,可以帮助政府部门了解公众聚集情况、预测可能发生的突发事件等。群体轨迹预测技术可以通过分析历史群体聚集数据的模式和趋势来预测未来可能发生群体聚集事件的时间和地点,从而采取相应的措施来维护社会稳定。此外,群体轨迹预测技术还可以通过对社交媒体数据的分析来了解公众的情绪和行为,以便采取相应的措施来维护社会稳定。城市规划是群体轨迹预测的另一个重要应用领域。通过对城市中人们移动轨迹的分析,可以了解城市交通状况、人口密度分布、人们的行为习惯等情况,从而为城市规划提供参考依据。群体轨迹预测技术可以通过分析城市居民的移动轨迹来预测城市交通流量和拥堵情况,从而为城市规划提供参考依据。此外,群体轨迹预测技术还可以通过对城市人口密度数据的分析来确定城市发展的方向和规模,从而为城市规划提供重要的参考依据。
3、社交力模型使用手工函数来描述行人之间的相互作用,已被广泛应用于多目标跟踪任务。然而,基于cnn的方法,如社交-lstm已经流行起来,利用社交池化机制和lstm模型进行预测。
4、为了捕捉随机性,使用了生成对抗网络,如gans,social-gan。此外,还将行人视为图中的节点,使用图卷积网络(gcns)和图注意力网络(gats)。考虑到群体内的相互作用,出现了群体感知方法。例如group-lstm。然而这些方法往往缺乏目标引导。
5、目标引导的方法利用环境信息来引导轨迹生成过程。这些方法通常采用两阶段预测方法。在第一阶段,预测目标位置,并使用2d图像通过图像分割来估计目标在环境中最可能的位置。在第二阶段,轨迹逐渐被引导到估计的最终位置。最近的工作,如zhao等人提出的tnt和dendorfer等人提出的goal-gan,将其他信息纳入轨迹预测过程。tnt引入了“目标状态”的概念并生成条件轨迹状态序列,而goal-gan利用过去的轨迹信息和场景中的视觉文本估计目标位置的多元模态概率分布。通过整合这些额外的信息源,这些方法取得了改善的预测结果。然而,现有的轨迹预测方法忽略了大规模场景中人群的自发目标生成。传统方法往往由于图像分割方法的限制而无法将场景中的人群目标估计为目标。因此,这些方法难以处理大规模场景中人群的复杂分布。
6、为了解决这一局限性,本发明提出的方法专注于提高大规模场景中人群生成目标的估计精度。通过考虑人群行为的独特特征,本发明旨在提高这些场景中轨迹预测的准确性和鲁棒性。
7、通常,包含广视场(fov)和成百上千人同时描述人群行为和互动的图像由千兆像素相机拍摄。panda是第一个以人为中心的大型视频数据集,用于大规模、长期和多目标的视觉分析。由panda驱动的作品已有现有技术发表,gigadet由pgn模块和decdet模块组成。pgn用于从高分辨率输入构建的缩略图中提取感兴趣的区域。然后,decdet用于检测提取的区域中的对象。区域被组织成适当的尺寸,并且检测任务并行执行。gigamvs是第一个基于千兆像素图像的3d重建/渲染基准,用于超大规模的真实场景。crowd3d是第一个从单个大型场景图像中以全局一致性重建数百人的3d姿势、形状和位置的框架。dsgnet是基于深度学习的第一个千兆像素大型场景图像的细粒度社交分组框架,它由图引导的全局到局部分区策略和一个学习社交对的隐式表示的深度分组网络组成。当前的多个行人轨迹预测数据集主要关注自动驾驶中遇到的在道路上的行人意图难以预测问题,而忽视了群体场景中的行人预测问题。
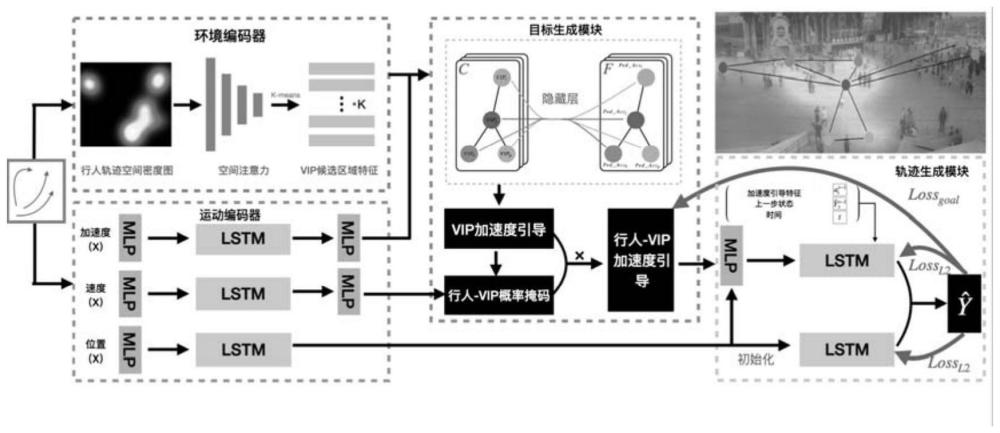
8、综上,单人轨迹预测方法没有考虑行人的局部环境,只关注如何对单个观测轨迹进行处理以获得准确的预测结果。面向团体的轨迹预测方法没有考虑行人的目标导向,只关注如何融合局部动态特征和观测轨迹特征,以利用附近行人的轨迹作为引导来生成轨迹结果。最后,目标条件轨迹预测方法考虑了人群的自组织特性,关注如何生成来自场景图像的场景语义分割的不同目标提议产生的概率。vip-net不仅能够捕获受到全场景物体和群体的运动引导特征,而且能够在物理空间中借助由lstm组成的运动编码器捕获不同行人的邻居影响。vip-net使用运动编码器对行人轨迹特征进行编码,此外,还使用环境编码器和目标生成模块捕获每个行人的受到全场景物体和群体的引导。
9、在数百个人的大型场景中,基于目标的多人轨迹预测对于人群分析和公共安全至关重要。然而,现有的单人轨迹预测方法很难处理包含数百人的大型场景中,由于人数过多,交互大量且交互行为复杂,导致的行人目的地不明确的问题,大规模人群场景中的行人同时受到场景静态物体和场景动态人群的影响。
技术实现思路
1、针对背景技术中存在的技术问题,本发明的目的在于提供一种面向大场景的群体轨迹预测方法。
2、为了实现上述目的,本发明采用了如下技术方案:
3、一种面向大场景的群体轨迹预测方法,包括以下步骤:
4、s1、对每个人的观测轨迹进行hermite差值并采样,得到离散轨迹位置,然后计算对应离散轨迹位置的一阶导数和二阶导数作为行人运动的速度和加速度;然后将观测轨迹的位置、观测轨迹的速度、观测轨迹的加速度送入运动编码模块,获取运动模式特征,即完整行人轨迹;
5、s2、利用群体历史轨迹数据生成密度图,然后利用gmm-em算法计算生成的密度图的每个类的区域以及聚类中心,作为环境编码模块的输入,从而获取每个vip候选区域的运动特征;
6、s3、群体加速度引导感知并与行人运动模式进行匹配,利用s1和s2中计算得到的完整行人轨迹和vip候选区域的聚类中心,以两者之间的距离初始化行人-vip的分类矩阵;然后获取p个vip候选区的群体运动模式特征作为vip加速度引导特征,利用加速度和速度之间的关系将每个行人匹配与全局vip的加速度引导模式匹配结果,得到行人-vip加速度引导(高维)特征;
7、s4、利用s3得到的行人-vip加速度引导的(高维)特征,经过一个多层感知机获取,获得行人未来受到群体的加速度,并于真实值计算损失,同时获取的位置编码特征以及lstm的门控制状态矩阵用于初始化轨迹生成模块中的lstm,利用预测的加速度结果作为偏差步进式引导下一步轨迹的生成,并行的lstm是为了生成在没有群体影响下的轨迹预测结果,保持了单人的随机性;将这两阶段的轨迹生成结果进行合并通过一个多层感知机,用于合并具有群体引导性和在具有单人随机性的情况下最终的轨迹预测结果,作为最终的群体轨迹预测输出结果。
8、优选地,步骤s1中,所述对每个人的观测轨迹进行hermite差值并采样,得到离散轨迹位置,然后计算对应离散轨迹位置的一阶导数和二阶导数作为行人运动的速度和加速度;然后将观测轨迹的位置、观测轨迹的速度、观测轨迹的加速度送入运动编码模块,获取运动模式特征,即完整行人轨迹,包括以下步骤:
9、s101、轨迹数据插值:
10、首先,对过去的轨迹采用作为动态特征提取器用于捕捉行人的速度和方向的运动编码器进行编码,获得每条观测轨迹的位置xpos、观测轨迹的速度xvel和观测轨迹的加速度xacc,具体如下所示:
11、x={xpos,xvel,xacc]
12、其中,xvol和xacc是通过对序列tobs指定的时间点上xpos的离散观测应用hermite插值获得的;
13、然后,计算获得的hermite插值相对于相应时间点t∈tobs的一阶和二阶导数,分别得到xvol和xacc,由于数据不完整,还需要进行二阶可导的差值并采样,hermite插值的定义如下:
14、
15、其中,n是离散观测的数量,xi表示在时间ti∈tobs观察到的位置,x′i表示相应的一阶导数,hi(t)和h′i(t)表示hermite插值基函数,公式定义如下:
16、
17、
18、s102、运动编码:
19、将xpos、xvel、xacc∈rd通过多层感知机(mlp)嵌入到一个更高维的向量中,然后输入到用于编码轨迹的lstm中,lstm的隐藏状态[hme,hme_vel,hme_acc]被其他模块用于预测目标和解码每个行人的轨迹,速度特征用于生成轨迹引导目标的概率,加速度特征用于获取由vips引导的每个行人的特征查询。
20、优选地,步骤s2中,所述利用群体历史轨迹数据生成密度图,然后利用gmm-em算法计算生成的密度图的每个类的区域以及聚类中心,作为环境编码模块的输入,从而获取每个vip候选区域的运动特征,包括以下步骤:
21、s201、生成密度图:
22、首先,考虑到观测到的轨迹,表示为x,根据群体历史轨迹的位置计算表示整个场景中行人的空间分布、尺寸大小为500*500的密度图dm。
23、接着,通过由gmm-em聚类算法生成的掩码对生成的密度图进行p次计算,每次只保留相同聚类区域的空间特征,得到生成的密度图的每个类的区域以及聚类中心,其中包括p个聚类结果作为原始vip候选区,p是vip候选区和聚类数目的数量;
24、为了计算密度图,本发明使用核密度估计(kde),可以表示为:
25、
26、其中,n是观测到的轨迹数量,(x,y)表示密度图网格中的一个点,(xi,yi)表示第i个轨迹观测的位置,k(·)是核函数,通常选择带宽为σ的高斯核,这里将其设为0.14。为了将vip的空间分布特征与需要进行预测的特征相结合,本发明将每个行人的轨迹空间分布特征加到vip的空间分布上,并进行归一化:
27、
28、
29、其中,是第n观测到的行人在时刻t时的位置;表示向上取整操作;
30、s202、获取vip候选区域的运动特征:
31、对于给定的密度图dm,计算生成的密度图的每个类的区域以及聚类中心,作为环境编码模块的输入,使用空间注意力机制来提取轨迹预测中目标选择任务的最重要区域,具体表示如下:
32、q=dm*wq,
33、k=dm*wk,
34、v=dm*wv,
35、
36、其中,q、k和v分别是注意力机制中的查询(query)、键(key)、值(value)特征矩阵;dk等于1;wq、wk、wv是从高斯分布中随机抽取的随机数,用于初始化这些矩阵;qkt是qk的转置矩阵;最终的密度图特征图为:
37、feat_dm=sadm⊙dm,
38、其中⊙表示元素级乘法(hadamard积),在sa_dm和dm之间进行相乘。
39、优选地,步骤s3中,所述群体加速度引导感知并与行人运动模式进行匹配,包括以下步骤:
40、s301、群体加速度引导感知并与行人运动模式进行匹配,利用s1和s2过程中计算得到的完整行人轨迹和vip候选区域的聚类中心(center_vip),以他们之间的距离来初始化行人-vip的分类矩阵(pvc)。
41、
42、
43、s302、获取p个vip候选区的群体运动模式特征作为vip加速度引导特征,先将以此为节点e以他们之间的特征差并乘以每个聚类中心的标准化距离作为边v构造vip-graph=<e,v>,然后借助图卷积神经网络具有通过交换不同节点之间的信息从而扩散相邻且相似的vip候选区之间的特征,得到每个vip加速度引导特征,具体表示如下:
44、vip_graph=g<venv,eenv>
45、ei,j=||(feat_dm[i])-(feat_dm[j])||1;
46、s303、利用加速度和速度的方向关系,计算s1中得到的速度编码特征与s4中得到的其与每个vip的引导特征的与余弦相似度,得到每个vip的加速度引导特征与行人速度的耦合关系矩阵,同时由于物理空间位置的不同也会对该作用结果会有影响,将该耦合关系矩阵与s3中得到的行人-vip分类矩阵对应位置相乘得到。
47、当行人的速度和朝向目标(vip)的引导加速度方向相同时,且速度较快或加速度逐渐增加时,表明行人渴望接近vip。当行人的速度和朝向vip的引导加速度方向相反时,表明行人的目标是远离vip。这种趋势可以通过余弦相似度计算加强。当行人的速度和vip的引导特征几乎垂直时,当行人围绕物体移动时,vip对他们运动的吸引和斥力倾向往往会平衡;使用以下方程计算方向和概率掩码(dpm),即vip提案特征i和行人轨迹特征j之间的余弦相似度,再与s301得到的pvc做内积,得到最终的每个行人的行人-vip概率掩码(dpm):
48、dpmi,j=cos<ugi,vfj>,
49、dpm=dpm⊙pvc,
50、其中,ug∈ug,vf∈hme_vel,dpm∈rn*p;dpm表示行人受场景中所有vip影响的概率;
51、s304、利用行人-vip概率掩码矩阵与目标候选区域特征对应位置相乘,得到整个场景中的vip对需要预测行人的加速度作用量,将其命名为行人-vip加速度引导(sfgf):
52、sfgfi,j=dpmi,··ug·,j·。
53、优选地,s4中,所述利用行人-vip加速度引导的高维特征,经过一个多层感知机获取最终获得行人未来受到群体的加速度,并与真实值计算损失,同时s1中获取的位置编码特征以及lstm的门控制状态矩阵用于初始化轨迹生成模块中的lstm,利用预测的加速度结果作为偏差步进式引导下一步轨迹的生成,并行的lstm是为了生成在没有群体影响下的轨迹预测结果,保持了单人的随机性;将这两阶段的轨迹生成结果进行合并通过一个多层感知机,用于合并具有群体引导性和在具有单人随机性的情况下最终的轨迹预测结果,作为最终的轨迹预测输出结果,包括以下步骤:
54、s401、有/无受到群体影响的轨迹预测:
55、首先,本发明将目标生成模块后的多层感知机预测的加速度向量eg和lstm嵌入hme传递给mlp,这个mlp是为了使得eg和hme维度相等,以初始化lstm的隐藏状态
56、然后,本发明递归地对未来的每个时间间隔进行预测,这里的时间间隔为0.5s,为此,lstm获取三个输入:先前步骤预测vip之间的差值和当前标量时间步t,使用传统的轨迹预测模型生成每个行人的轨迹结果,其中包括单个行人的随机性和他们邻居的运动特征;
57、s402、回归融合:
58、使用mlp对有目标引导的预测结果和没有目标引导的轨迹预测结果进行回归,由于每个观测间隔相等,本发明直接获取轨迹预测结果的x维度和y维度,并添加时间维度形成两组回归参数,分别由和表示,将最终回归结果输出为最终轨迹预测结果
59、s403、计算总损失损失:
60、总损失函数可分为两部分:轨迹预测部分的损失和加速度部分的损失,轨迹预测部分的损失定义为:
61、
62、其中,t是预测长度,和yi,t分别表示时间点t处行人i的预测轨迹和真值,目标生成部分的损失定义为:
63、
64、使用lgg来引导vip-net的目标生成模块,用于度量生成的目标向量与从真实轨迹生成的真值加速度向量之间的差异,最终的总损失函数定义为:
65、l=(1-λ)lpred+λlgg
66、其中,λ是一个超参数,用于调整损失的两个部分之间的权重。λ被设置为0.47。
67、本发明的有益效果:
68、(1)本发明提供了一种基于大场景的群体轨迹预测方法,具体定义了vips并设计了vip-graph来捕捉不同人群内部之间的复杂目标引导特征,建模了全场景人群流动情况,基于历史经验设计了全场景行人轨迹引导结构图;
69、(2)本发明提供了一种基于大场景的群体轨迹预测方法,具体提出了一种基于物理状态的行人目标选择方法,在目标引导模块中,在群体引导的条件下,获取每个行人受目标影响的社交力约束程度计算方法。
70、(3)本发明提供了一种基于大场景的群体轨迹预测方法,具体提出了一个新的行人轨迹预测框架,以群体和场景目标的引导为基础,包括环境编码器、运动编码器、vip-graph目标生成和轨迹模块,vip-net在公开数据集上展示出最先进的性能。
- 还没有人留言评论。精彩留言会获得点赞!