高并发大数据的敏感数据甄别系统的制作方法
本发明涉及数据甄别,尤其涉及高并发大数据的敏感数据甄别系统。
背景技术:
1、随着大数据技术的迅猛发展,数据量逐渐增大,而在这些大数据中往往包含了大量敏感信息。例如,个人隐私数据、企业机密或国家安全相关信息。在高并发的数据处理环境中,如何有效、准确地识别出这些敏感信息成为了一个重要但富有挑战性的问题。现有的数据处理和分析系统往往侧重于数据的存储、查询和基础分析,但对于大规模、高并发环境下的敏感数据识别,尤其是在数据流不断变化的情况下,现有技术还存在诸多不足。
2、传统的敏感数据识别技术通常使用预定义的规则和模式进行匹配,但这些方法通常只能进行表面级的数据匹配,难以实现对上下文和深层次特征的分析。此外,由于缺乏动态的权重分配和自适应机制,现有的系统在面对大量并发数据流时,通常表现出较低的准确性和可扩展性。
3、在处理高并发大数据的场景下,需要一种更高效、准确,同时具备自适应能力的敏感数据甄别系统。尤其是在数据特点多变、数据量巨大的环境中,对数据的快速和准确识别,以及灵活的系统自适应能力,显得尤为重要。
技术实现思路
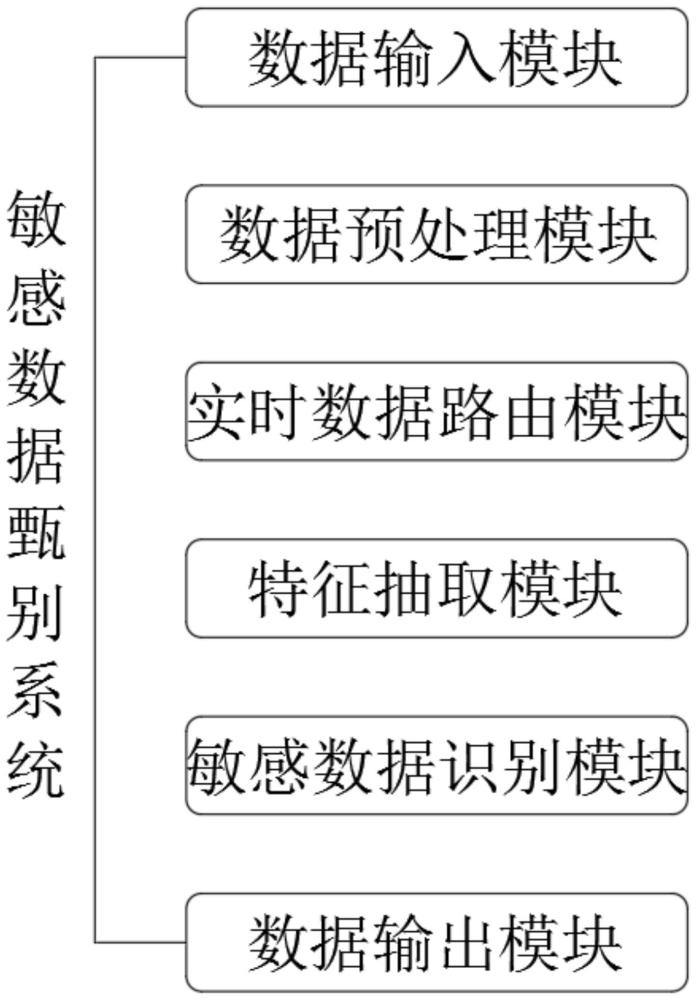
1、基于上述目的,本发明提供了高并发大数据的敏感数据甄别系统。
2、高并发大数据的敏感数据甄别系统,包括:
3、数据输入模块,用于接收原始数据流;
4、数据预处理模块,对接收的原始数据流进行数据清洗和标准化,输出预处理数据流;
5、实时数据路由模块,接收预处理数据流,并基于数据元信息和用户指定的条件进行数据路由,输出至特征抽取模块和敏感数据识别模块;
6、特征抽取模块,接收来自实时数据路由模块的数据流,并执行特征抽取,输出特征数据流;
7、敏感数据识别模块,接收特征数据流和来自实时数据路由模块的数据流,进行敏感数据识别,输出识别标签流;
8、数据输出模块,接收识别标签流和来自实时数据路由模块的数据流,根据识别标签流进行敏感数据的标记或隔离,输出处理后的数据流;
9、其中,实时数据路由模块还包括基于权重的动态分配算法,该动态分配算法根据特征数据流和来自实时数据路由模块的数据流中的特定指标,动态调整数据流向特征抽取模块或敏感数据识别模块的权重。
10、进一步的,所述数据输入模块包括:
11、数据接口子模块,与多种数据源建立连接,接收多种格式的原始数据流;
12、缓冲队列子模块,用于临时存储来自数据接口子模块的原始数据流;
13、数据解析子模块,用于从缓冲队列子模块接收原始数据流,并进行初步的数据类型识别和格式解析,输出到数据预处理模块。
14、进一步的,所述数据接口子模块、缓冲队列子模块和数据解析子模块之间形成紧密的数据流关联,数据接口子模块与外部数据源接口对接,接收原始数据流并将其传送到缓冲队列子模块进行临时存储,缓冲队列子模块则作为中间存储,缓解数据输入与数据预处理之间的速度匹配差,数据解析子模块从缓冲队列子模块接收数据,并进行初步的类型识别和格式解析,为后续的数据预处理模块提供了更为标准化和统一的数据流。
15、进一步的,所述数据预处理模块包括:数据质量检查子模块,数据清洗子模块,以及数据标准化子模块,其中,
16、数据质量检查子模块通过z-score方法对数据集中每个特征进行评分,对z-score值超出预定阈值的数据点进行标记,使用bitmap索引进行缺失值快速检索,对存在缺失值的数据点进行标记,通过哈希函数和bloom filter结构对数据集进行扫描,找出并标记重复的数据点;
17、数据清洗子模块对由异常值检测器标记的数据点进行线性插值或拉格朗日插值来替代异常值,对由缺失值标记器标记的数据点,使用k-最近邻算法来进行缺失值的填充,使用基于排序的方法,对由重复项标识器标记的数据点进行剔除;
18、数据标准化子模块使用min-max scaling或z-score标准化对数值型数据进行规范化,使用one-hot编码或标签编码对类别型数据进行转换;
19、数据质量检查子模块的输出连接至数据清洗子模块,数据清洗子模块的输出再连接至数据标准化子模块,数据标准化子模块的输出形成预处理数据流,该预处理数据流作为实时数据路由模块的输入。
20、进一步的,所述实时数据路由模块包括:数据标签子模块、数据分流器和动态负载均衡子模块,其中
21、数据标签子模块:接收来自数据预处理模块的预处理数据流,并利用预定义规则引擎对每个数据项生成元数据标签;
22、数据分流器:接收带有元数据标签的数据流,并根据标签内容对数据进行路由;
23、动态负载均衡子模块:实时监控各目标模块的处理能力和延迟,使用权重分配算法动态调整数据流的分配比例,以确保高效的数据处理。
24、进一步的,所述预定义规则引擎具体包括:
25、条件识别器:使用决策树算法来评估接入的每个数据项的多维特性,输出一个条件标识符;
26、标签生成器:接收条件识别器输出的条件标识符,并根据预先建立的标签库,为每个数据项生成相应的元数据标签;
27、更新器:基于自适应机制,实时收集系统内外的反馈,并根据动态更新决策树算法和标签库以适应不断变化的数据特性和需求,进而存储最近生成的元数据标签和对应的条件标识符,以优化系统的响应速度。
28、进一步的,所述特征抽取模块包括特征选择子模块、特征转换子模块和特征输出子模块,其中,
29、特征选择子模块:使用信息增益算法对接收到的预处理数据流进行特征选择,对每个特征f,其信息增益ig(f)计算如下:
30、
31、其中,h(d)是整个数据集d的熵,dv是特征f取值为v的数据子集,h(dv)是dv的熵,特征选择子模块选择具有最高信息增益的特征进行下一步的处理;
32、特征转换子模块:使用主成分分析对选定的特征进行降维和转换,给定一个数据矩阵x,首先计算其协方差矩阵σ,求解σ的特征值和特征向量,选取前k个最大的特征值对应的特征向量组成一个k维特征空间,用该特征空间将高维数据投影到k维空间;
33、特征输出子模块:接收特征转换子模块的输出,并以json序列化格式生成特征数据流作为输出。
34、进一步的,所述敏感数据识别模块包括模式匹配子模块、上下文分析子模块和识别标签输出子模块,其中,
35、模式匹配子模块:使用正则表达式和自然语言处理算法对来自特征抽取模块的特征数据流进行初步的模式匹配;
36、上下文分析子模块:接收模式匹配子模块的输出,并通过分析数据项的上下文信息,对识别的结果进行确认或排除;
37、识别标签输出子模块:根据模式匹配子模块和上下文分析子模块的输出结果,生成对应的识别标签。
38、进一步的,所述权重的动态分配算法具体如下:
39、wi(t)=α·pi(t)+β·ai(t)+γ·ri(t)
40、其中:
41、wi(t)是第i个子模块在时间t的影响权重;
42、pi(t)是第i个子模块在时间t的性能指标;
43、ai(t)是第i个子模块在时间t的可用性指标;
44、ri(t)是第i个子模块在时间t的准确性指标;
45、α,β,γ是预设的权重系数,用于平衡性能、可用性和准确性二个因素的影响。
46、本发明的有益效果:
47、本发明,通过引入模块化的设计和紧密集成的子模块,实现了在高并发和大数据环境下敏感数据的高效和准确识别。特别地,通过特征抽取模块的信息增益算法和主成分分析,有效地筛选和转换了输入数据流中的关键特征,显著提高了数据处理能力和识别准确性。
48、本发明,通过敏感数据识别模块的模式匹配和上下文分析技术,对选定的特征进行深入的敏感数据识别。这一多层次的技术手段不仅大幅度减少了误报和漏报的风险,而且提高了系统的可靠性和准确性。识别后的标签流可用于后续的数据处理和存储模块,使整个系统具有高度的可扩展性和适用性。
49、本发明,通过引入权重动态分配算法,该系统能够根据实时数据和各个子模块的性能、可用性和准确性,动态调整数据处理的权重和优先级。这种自适应性和优化显著提高了系统在复杂、多变的高并发大数据环境下的整体性能和稳定性。
- 还没有人留言评论。精彩留言会获得点赞!