基于有监督对比学习的网格自注意力人脸表情识别方法
本发明涉及一种基于有监督对比学习的网格自注意力人脸表情识别方法,属于计算机视觉,特别是人脸表情识别技术。
背景技术:
1、在表情识别任务中,表情特征提取是关键步骤之一。传统人脸表情识别算法一般都是通过人工方式来选择并提取人脸表情特征,受某些人为因素的干扰,从而使得训练得到的模型无法对表情信息进行良好的诠释,模型泛化能力不强,识别准确率不高。大数据时代,计算资源快速发展与升级,使深度学习取得了突破性的进展,卷积神经网络在人脸表情识别任务上表现出了一定的优越性,但是仍然受高质量样本有限的制约,同时复杂的背景环境和不均匀的光线等也会产生影响,使得模型训练易产生过拟合,难以提取有效表情特征,最终模型的准确率和鲁棒性需要进一步提升,具体为:
2、(1)人脸表情数据类别不均衡和数据不足问题。由于人更容易出现开心或者惊讶等表情而不是其他类别表情,大部分人脸表情数据集中存在表情类别不均衡的问题,即开心或惊讶等常见表情的样本数量会远多于厌恶等其他表情类别。进而导致所训练的模型更加偏向于常见的表情类型,对于罕见的表情无法识别准确。
3、(2)深度dcnn模型过拟合问题。为了保证模型能够模拟复杂的人脸表情特征,网络通常需要具有很深的层次结构。然而,对dcnn模型的网络结构加深或扩展,会导致模型结构复杂,容易引发模型过拟合。数据不足可能进一步导致深度表情识别模型训练过拟合问题。
4、(3)人脸表情特征提取困难问题。基于dcnn的表情识别模型的关键在于从人脸图像中发现和学习到具有判别性作用的关键特征,然后进行类别匹配。在无约束的自然场景中,人脸图像是在背景和光线强度等因素之间的共同影响下产生的,图像中除了人脸可能还包含许多不相关的信息。因此,图像的复杂性很高,可能存在很多噪音,使得学习表达性特征变得非常困难。
5、(4)人脸表情特征权重关注不足。在使用dcnn进行表情识别时,各个特征通道和空间信息权重是固定的,无法自适应地进行调整,从而导致一些重要的通道或者空间特征被忽略,而一些不重要的特征通道对表情识别起到负面作用。为了结合表情图像的全局和局部细节,在cnn直接使用大的卷积核来充分捕捉数据中的关键信息会导致模型需要学习和更新大量的网络参数,导致更长的模型学习时间。
6、现有的人脸表情识别方法主要采用深度学习模型对人脸图像进行特征提取和分类。然而,由于人脸表情具有多样性和变化性,传统的深度学习模型往往难以准确地识别不同的表情。
技术实现思路
1、本发明技术解决问题:克服现有技术的不足,提供一种基于有监督对比学习的网格自注意力人脸表情识别方法,精准地识别人脸的不同表情,提升表情识别的性能。
2、本发明技术解决方案:
3、第一方面,本发明提供一种基于有监督对比学习的网格自注意力人脸表情识别方法,其特点在于:采用一种有监督对比学习的方法建立具有多层级自注意力网络的特征提取模型,具体包括以下步骤:
4、步骤1:创新一个包含多类别的人脸表情图像数据集,数据集包括人脸表情图像及对应的标签类别数据,将所有人脸表情图像作为训练样本进行预处理,裁剪成为大小相同的图像,并剔除非人脸表情图像和错误标签类别数据;将预处理后的人脸表情图像按照比例分为训练集、验证集和测试集,对训练集中的人脸表情图像即数据进行逐一数据增强,从而得到最终训练集;
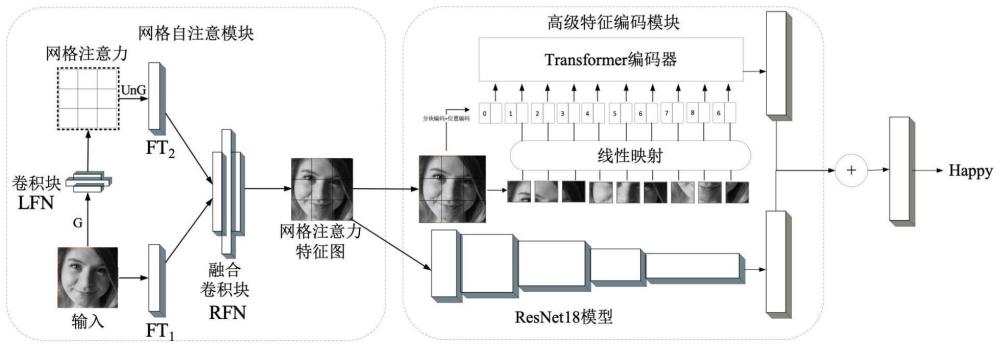
5、步骤2:构建一种具有多层级注意力网络的特征提取模型,所述具有多层级注意力网络的特征提取模型包括:网格自注意力模块和高级特征编码模块;
6、所述网格自注意力模块,按照网格的方式对不同空间位置的人脸表情图像进行注意力计算,得到网格注意力特征图,从而完成人脸表情图像中的低级特征的提取;
7、所述高级特征编码模块根据网格注意力特征图,提取人脸表情图像的高级特征即语义特征,再对语义特征进行分类,从而完成对人脸表情图像的分类;
8、步骤3:构建一种基于有监督对比学习的混合损失函数,约束步骤2中所构建的特征提取模型学习到更具有判别力的表示,从而提高任务性能;
9、步骤4:将步骤1所得训练集图像数据输入到步骤2所构建的具有多层级注意力网络的特征提取模型中进行训练,根据所输入图像数据的标签类别数据和步骤3所构建基于有监督对比学习的损失函数判断具有多层级注意力网络的特征提取模型的有效性,采用验证集最优准确率评测结果选择训练参数,得到训练好的具有多层级注意力网络的特征提取模型;
10、步骤5:将步骤1测试集中的人脸表情图像输入到训练好的具有多层级注意力网络的特征提取模型中,进行人脸表情的识别,验证所训练模型表情识别结果的准确性。
11、可选地,所述步骤3中,基于有监督对比学习的混合损失函数l包括基于数据增强的多分类交叉熵损失数lcls和有监督对比学习损失数lsup,如下式所示:
12、l=λ*lcls+(1-λ)*lsup
13、所述基于数据增强的多分类交叉熵损失函数lcls为其中λ表示基于数据增强的多分类交叉熵损失函数lcls在基于有监督对比学习的混合损失函数l中的权重,λ(范围0.05-1)根据训练样本进行选择,需要多次试验确定。m表示基本数据增强策略的种类,表示对训练样本标签类别的预测值,表示正则化后的特征输出,n表示从训练集中抽取的训练样本数量。
14、所述有监督对比学习损失函数lsup为:
15、
16、其中,i表示任意训练样本,e表示所有训练样本的集合,p(i)表示训练样本i的正样本集合,p表示与i互为正样本对的任意样本,log表示对数函数,exp表示指数函数,zi,zp和za表示训练样本i,p,a经过多层级注意力网络的特征提取模型的特征输出,τ表示有监督对比学习损失函数lsup的温度系数(范围0.5-20),τ根据训练样本进行选择,需要多次试验确定。;a(i)表示训练样本的负样本集合。
17、可选地,所述步骤1中,对训练集中的图像进行逐一数据增强的方法实现如下:
18、(1)将训练集中的图像裁剪为统一大小,进行灰度化,然后按顺序进行随机裁剪、随机颜色抖动、仿射变换、水平翻转和随机旋转基本数据增强操作;
19、(2)对经过步骤(1)中基本数据增强后的图像进行多倍裁剪,将处理的后的图像进行one-hot(独热)编码并随机添加噪音,得到编码后的图像;
20、(3)对编码后的图像照一定比例(融合比例系数小于0.15)进行随机融合,同时输入图像的标签类别数据对应的向量进行所述一定比例处理,得到最终图像。
21、可选地,所述步骤2中,所述网格自注意力模块中,按照网格的方式对不同空间位置的人脸表情图像进行注意力计算的过程包括三个部分:低级特征提取、网格注意力计算和残差特征融合,具体为:
22、(1)低级特征提取:将输入图像i通过卷积计算进行分割,描述为函数g,得到分割后网格图像:
23、
24、其中i,j表示分割后网格图像的行和列,c表示输入图像的通道数,h表示输入图像i的高度,w表示输入图像i的宽度,h为分割后网格图像的高度,w为分割后网格图像的宽度;
25、对每个分割后网络图像进行低级特征(低级特征包括纹理和边缘)提取,采用卷积计算完成对输入图像i不同空间位置的特征提取:
26、
27、其中为经过低级特征提取后的位于i行j列的网格图像的低级特征,lfn表示低级特征提取函数,通过卷积实现;
28、最终得到所有分割后网格图像的低级特征集合即作为网格注意力计算的输入;
29、(2)网格注意力计算:基于提取的所有网格图像的低级特征,采用点积相似度函数计算不同网格图像特征之间的相似性,得到基于自注意力的加权网格特征图集合
30、其注意力计算方式为:
31、
32、即:
33、
34、其中网格注意力计算中查询query和键key值均为得到的网格图像的低级特征集合键的维度为
35、再进一步将加权特征图集合进行去网格化,得到和输入图像大小相同的具有自注意力的加权特征图
36、
37、(3)特征融合:采用残差网络技术,将输入图像i与所述加权特征图之间的特征通过骨干融合网络进行融合;所述骨干融合网络包括两个特征转换网络ft1和ft2及一个特征融合网络rfn;所述两个特征转换网络ft1,ft2共享结构但参数不同,将输入图像i和加权特征图各自输入到特征变换网络ft1和ft2中,再将两个输出通过特征融合网络rfn完成残差特征融合,得到最终的网格注意力特征图
38、
39、可选地,所述高级特征编码模块根据网格注意力特征图,提取人脸表情图像的高级特征即语义特征,再对语义特征进行分类,从而完成对图像的分类的过程如下:
40、将网格自注意力模块的网格注意力特征图分别输入至经过预训练和微调的resnet18模型和预训练的视觉transformer模型中;所述resnet18模型首先采用步骤1中所述训练集进行全连接层微调;所述预训练的视觉transformer模型包括transformer编码网络和一个全连接层网络;网格注意力特征图经过所述resnet18模型后得到基于卷积的语义特征,同时经过所述视觉transformer模型得到基于自注意力的语义特征,对所述resnet18模型和所述视觉transformer模型所输出的高级语义特征进行加权,并在决策层对所述两个模型的输出结果进行分类预测,最终得到图像的预测输出类别,完成分类。所述高级特征编码模块同时融合高级空间和序列信息,能够兼顾全局和局部特征的建模。
41、第二方面,本发明提供一种电子设备,包括处理器、存储器,其中:
42、存储器,用于存放计算机程序;
43、处理器,用于执行存储器上所存放的计算机程序,执行时实现前述基于有监督对比学习的网格自注意力人脸表情识别方法。
44、第三方面,本发明提供一种计算机可读存储介质,其上存储有计算机程序,所述计算机程序执行时实现前述基于有监督对比学习的网格自注意力人脸表情识别方法。
45、本发明与现有技术相比的优点在于:
46、(1)本发明提出的技术方案能够克服卷积神经网络在人脸表情识别任务上受高质量样本有限、杂的背景环境、模型训练易产生过拟合及难以提取有效表情特征等困难,结合有监督对比学习和基于网格的自注意力网络,通过使用数据增强生成正负样本对,最大限度地利用有限的标签类别数据进行特征学习,同时在特征学习过程中关注不同层次的表情特征,自我注意力机制引入让网络更多的关注图像空间中重要的特征,从而减少特征冗余和提高模型的准确性。这种改进的技术方案使得模型能够同时融合低级和高级空间信息以及序列信息,更全面地建模表情特征。通过这种方式,模型在处理表情图像时能够更好地理解不同位置上的特征,并更精准地识别不同表情,提升表情识别的性能。
47、(2)本发明构建一种基于有监督对比学习的混合损失函数,将多分类交叉熵损失函数和有监督的对比学习结合起来,关注分类的同时进行不同图像的对比学习,能够缓解数据不均衡问题,提高模型的泛化能力和鲁棒性,采用本发明构建的损失函数约束所构建的特征提取模型可以使模型学习到更具有判别力的特征表示,从而提高任务性能;
48、(3)本发明所采用多种基本数据增强方法结合多倍裁剪和融合图像的方式对训练图像进行数据增强,一是增加了数据集的多样性,二是有助于提高模型对于各种噪声和干扰的鲁棒性。通过训练模型来区分相似和不相似的图像,它可以更好地应对输入数据的变化。
49、(4)本发明采用基于网格的自注意力机制来提高对不同位置的表情信息的建模能力,可以帮助模型更好地理解图像中的局部特征,提高对不同位置表情信息的建模能力,从而提高了模型的鲁棒性和可解释性。
50、(5)本发明将基于自注意力机制的时序相关高级表情特征和基于cnn的空间相关高级表情特征进行有效融合,采用决策层特征加权融合方法,将transformer模型和resnet18模型在决策层的输出进行合并,从而使得模型能够兼顾全局和局部空间特征的建模能力,更好地捕捉表情图像中的细节和上下文信息。
- 还没有人留言评论。精彩留言会获得点赞!