基于特征增强和多粒度匹配的文本引导服装图像检索方法
本发明涉及服装图像检索,具体涉及一种基于特征增强和多粒度匹配的文本引导的服装图像检索方法。
背景技术:
1、图像检索是指从图像库中检索符合用户意图的图像。虽然最近基于深度学习的图像检索取得很多成果,但是语义鸿沟和意图差距仍然是两大挑战。传统的图像检索一般可分为图像-图像检索和图像-文本检索,前者以图搜图,后者进行图文匹配,然而这种以单一模态作为输入的查询对用户意图的表达力有限。图文组合的多模态查询则能提供更多样化的信息,更能体现用户需求。图文组合的多模态查询也被称为文本引导的图像检索,或带有文本反馈的图像检索。文本引导的图像检索系统尤其适合基于对话的交互式检索场景,而这样的场景在电商领域极为常见。例如用户对所见到的服装图像不完全满意,那么用户可以基于这张图像输入想得到的属性的修改描述以获得更准确的检索结果。并且用户可以基于上一次的检索结果继续输入文本条件,完成多轮检索,直到发现完全符合需求的商品。文本引导的服装图像检索在电商领域有巨大的发展潜力,因而具有重要的应用价值和研究意义。
2、这项工作最早出现在tirg(text image residual gating)(nam vo,lu jiang,chen sun,kevin murphy,li-jia li,li fei-fei,and james hays.composing text andimage for image retrieval-an empirical odyssey.in proceedings of the ieee/cvfconference on computer vision and pattern recognition.2019.6439-6448)中。tirg将查询图像的全局表示和文本表示通过残差连接和门控模块进行融合。与之不同的是val(visiolinguistic attention learning)(yanbei chen,shaogang gong,and lorisbazzani.image search with text feedback by visiolinguistic attentionlearning.in conference on computer vision and pattern recognition,2020.)使用注意力机制将图像的局部特征图与文本表示进行融合,并在查询特征和目标特征间使用分级匹配的方式优化目标表示。clvc-net(comprehensive linguistic-visual compositionnetwork)(haokun wen,xuemeng song,xin yang,yibing zhan,and liqiangnie.comprehensive linguistic-visual composition network for imageretrieval.in associationfor computing machinery special interest group oninformation retrieval,sigir,2021.)设计了细粒度局部合成模块和细粒度全局合成模块,并使用相互学习的方法施加约束,使两个模块共享知识,相互促进。还有些方法通过附加约束来提高性能。cosmo(content-style modulation)(s.lee,d.kim,and b.han.cosmo:content-style modulation for image retrieval with text feedback.in conferenceon computer vision and pattern recognition,2021.)提出了内容调制器和风格调制器分别对局部特征和全局特征进行修改。与之相似的sac(semantic attentioncomposition)(surgan jandial,pinkesh badjatiya,pranit chawla,ayush chopra,mausoom sarkar,and balaji krishnamurthy.2022.sac:semantic attentioncomposition for text-conditioned image retrieval.in proceedings of the ieee/cvf winter conference on applications of computer vision.4021-4030.)也是通过两步的文本特征融合来实现查询图像表示的定位和修改。amc(adaptive multi-expertcollaborative)(zhu h,wei y,zhao y,etal.amc:adaptive multi-expertcollaborative network for text-guided image retrieval[j].associationforcomputing machinery transactions on multimedia computing,communications andapplications,2023,19(6):1-22.)网络首次采用动态多专家协作网络来处理该任务,根据不同的图像文本查询组合对处理节点赋予不同的激活值,与之前方法的静态模型相比更加灵活。
3、但是这些方法无论采取何种复杂结构实现多模态的融合,它们在训练时倾向于采用严格的细粒度匹配。与之不同的是本发明方法的模型通过添加噪声的方式增强目标特征,并将粗粒度匹配与细粒度匹配相统一,减少模型对潜在目标图像的排斥。
技术实现思路
1、本发明的目的在于提供一种基于特征增强和多粒度匹配的文本引导的服装图像检索方法,解决了现有方法在面对模糊文本条件时生成的检索结果精度低且特征相对单调的问题。
2、本发明所采用的技术方案是,基于特征增强和多粒度匹配的文本引导的服装图像检索方法,具体步骤如下:
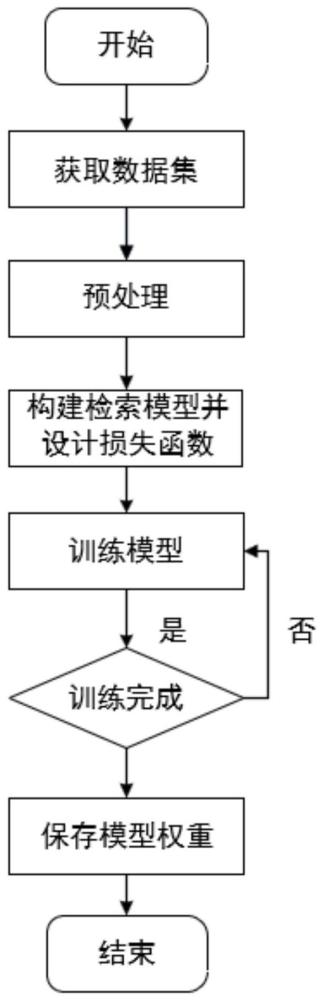
3、步骤一、先获取公开的服装数据集,对服装数据集中的图像做预处理;
4、步骤二、构建基于特征增强和多粒度匹配的文本引导的服装图像检索模型,并设计多粒度匹配的损失函数;
5、步骤三、构建完基于特征增强和多粒度匹配的文本引导的服装图像检索模型后,使用多粒度匹配的损失函数ltotal训练检索模型,训练完成后,保存最终得到的权重;
6、步骤四、先构建检索所需图像库,对图像库进行预处理,使用步骤三训练得到的训练完的服装图像检索模型,实现文本引导的服装图像检索功能。
7、本发明的特征还在于,
8、步骤一中,对服装数据集中的图像做预处理具体如下:服装数据集以<查询图像,文本条件,目标图像>的三元组形式组织;对<查询图像,文本条件,目标图像>三元组中的查询图像和目标图像依次使用如下python库函数做预处理:resize([256,256]、centercrop(224)、totensor()、normalize([0.485,0.456,0.406],[0.229,0.224,0.225]);预处理后的用于训练模型的服装数据集中的三元组表示为其中is表示预处理后的查询图像,ts表示文本条件,it表示预处理后的目标图像,n表示三元组的数量。
9、步骤二中,所述基于特征增强和多粒度匹配的文本引导的服装图像检索模型由图像编码器、文本编码器、图像文本合成模块、噪声增强模块组成;
10、其中,图像编码器采用在imagenet上进行预训练的resnet50,但删除了最后的分类层以保留原始特征;
11、将预处理后的查询图像is输入到图像编码器中,将预处理后的目标图像it输入到与查询图像is相同且共享权重的图像编码器中,再经过平均池化降维,对查询图像is和目标图像it的处理用公式表示为:
12、
13、式(1)中,fimg(is)为图像编码器对查询图像is的处理,fimg(it)为图像编码器对目标图像it的处理,为输出的查询图像特征,poolavg(fimg(it))表示对fimg(it)进行平均池化,为输出的目标特征;其中,文本编码器由一个嵌入层和lstm网络组成,该嵌入层由glove word embedding进行初始化;
14、将文本条件ts依次经过嵌入层和lstm网络得到文本特征文本特征用公式表示为:
15、
16、式(2)中,ftext(ts)表示对文本条件ts的变换,为变换后得到的文本特征。
17、步骤二中,所述图像文本合成模块包括两个动态交互层;每个动态交互层由一个路由节点和三个专家节点组成,第一个动态交互层的输入来自图像编码器和文本编码器的输出,第二个动态交互层的输入来自第一个动态交互层和文本编码器的输出;每个动态交互层中的三个专家节点并行运作,这三个专家节点对输入到动态交互层中的中间特征x和文本特征fst做处理,若为第一个动态交互层,则中间特征x为图像编码器输出的查询图像特征fsi,若为第二个动态交互层,则x为第一个动态交互层的输出,文本特征fst来自文本编码器;在得到三个专家节点的输出后,使用路由节点生成路径激活值,将三个专家节点的输出加权聚合作为动态交互层的输出;
18、第一个专家节点是nin,即归一化身份节点,使用该节点保留和归一化上一层的输出;第一个专家节点用公式表示为:
19、f1(x)=n(x) (3)
20、式(3)中,f1(x)表示第一个专家节点nin执行的函数,n(x)表示对输入当前节点的中间特征x进行层归一化;
21、第二个专家节点是gtn,即全局转换节点,该节点的具体作用:根据文本编码器输出的文本特征生成移动向量β和缩放向量γ,公式表示为:
22、
23、式(4)中,为可学习的参数矩阵,bγ,bβ为偏置参数,通过线性层来实现,然后使用移动向量β和缩放向量γ对输入当前节点的中间特征x应用仿射变换,第二个专家节点gtn用公式表示为:
24、
25、式(5)中,f2(x)表示第二个节点gtn对中间特征x执行的函数,⊙表示矩阵按元素相乘;
26、第三个专家节点是crn,即跨模态推理节点,该节点的具体作用:先将文本编码器输出的文本特征fst与输入当前节点的中间特征x拼接,将拼接后的特征再输入到一个线性层中,对中间特征x和文本特征的处理用公式表示为:
27、
28、式(6)中,[;]表示矩阵在特征维度进行拼接,表示该线性层执行的操作,然后将拼接后的特征xc映射到q,k,v这三个不同的空间中,生成q,k,v空间的公式表示为:
29、
30、式(7)中,是可学习的参数矩阵,通过线性层来实现,然后构建多头自注意力,第i个分头用公式表示为:
31、
32、式(8)中,headi表示第i个分头,dk代表矩阵k的维度,将所有分头拼接得到多头自注意力函数,多头自注意力函数用公式表示为:
33、mutihead(x)=[head1;...;headh] (9)
34、式(9)中,x为输入当前节点的中间特征,h为总头数;则第三个节点crn执行的函数表示为:
35、f3(x)=n(ffn(mutihead(x))+mutihead(x)) (10)
36、式(10)中,f3(x)表示第三个节点crn对中间特征x执行的函数,ffn为一个两层的带relu激活函数的多层感知机,mutihead(x)为对中间特征x应用多头自注意力函数;
37、路由节点的作用是根据中间特征x和文本特征对当前层的三个专家节点生成相应的路径激活值,将三个专家节点的输出作加权聚合,聚合后的结果作为动态交互层的输出;
38、其中,每个动态交互层的路径激活值表示为:
39、
40、式(11)中,表示第l个动态交互层的路由函数,xl-1为第(l-1)个动态交互层输出的中间特征表示,为文本特征,αl为第l个动态交互层输出的激活值;第l个动态交互层的输出xl可以表示为:
41、
42、式(12)中,分别表示第l个动态交互层的第i个专家节点的激活值和输出特征;每个动态层的路由函数的实现具体为:首先将第l个动态交互层的输出xl与文本特征拼接,表示为:
43、
44、式(13)中,r为拼接后的特征,将r在维度k上的所有分量ri累加,再经过线性层和层归一化,对r的所有分量ri的处理用公式表示为:
45、
46、式(14)中,为参数矩阵,表示线性层执行的操作,ψ为得到的特征,则第l个动态交互层的路由函数可以表示为:
47、
48、式(15)中,xl-1为第(l-1)个动态交互层输出的中间特征表示,为文本特征,σ为sigmoid函数,ξ为relu函数,为参数矩阵,由线性层实现。
49、步骤二中,噪声增强模块的作用是对目标特征添加噪声,目的是让模型在输入查询文本不够精确的条件下,能够识别更多潜在的目标图像,或者说使模型减少对目标特征的过拟合,具体为:使用噪声增强模块对图像编码器输出的目标特征ft进行噪声增强后得到表示为:
50、
51、式(16)中,是对目标特征ft应用一维实例归一化后获得,α~n(d,σt),β~n(μ,σt)分别为噪声参数,它们服从正态分布,与目标特征形状相同,其中d为超参数,μ,σt分别为目标特征的均值、标准差。
52、步骤二中,基于特征增强和多粒度匹配的文本引导的服装图像检索模型的损失函数包括细粒度的linfo损失和粗粒度的lu损失;linfo损失也被称为infonce损失,表示为:
53、
54、式(17)中,fs为经过两个动态交互层之后得到的图像文本组合特征,ft为目标特征,b为批大小,分别为一批三元组中的第i个图文组合特征和目标特征,κ为相似核;
55、对infonce损失做调整以进行统一,调整后得到的粗粒度损失lu为:
56、
57、式(18)中,fs为经过两个动态交互层之后得到的图像文本组合特征,为噪声增强后的特征,σ为目标特征的标准差;然后将lu,linfo进行统一:
58、
59、γ表示为:
60、
61、式(20)中,p1表示当前训练的轮数,p2代表训练的总轮数,γ0,c为固定参数,γ∈[0,1]。
62、步骤三中,训练时,使用adam优化器,权重衰减因子为1e-6,训练周期为60轮;学习率为1e-4,每40轮衰减10倍;批大小b为32,编码维度为1024;超参数γ0=2,=1,d=1。
63、步骤四具体为:先构建检索所需图像库,然后将用户输入的查询图像经步骤一中的库函数处理得到预处理结果,将预处理后的查询图像与用户输入的文本条件输入到已训练完的服装图像检索模型中,得到查询图像与文本条件的组合特征fs,将图像库中的服装图像利用检索模型得到特征表示,然后一一计算组合特征fs与图像库中服装图像的特征表示的相似度,将得到的相似度从大到小进行排序,根据排序结果依次返回图像库中对应的服装图像,由此实现文本引导的服装图像检索功能。
64、本发明的有益效果是:
65、本发明方法提出了一种新的用于文本引导的服装图像检索模型,能够得到召回率高且更具多样性的检索结果。具体的说,本发明方法通过噪声增强目标特征并优化学习策略,使用动态权重统一粗粒度匹配与细粒度匹配,使得本发明可以生成的检索结果更能符合用户意图且更具有多样性,本发明方法解决了现有方法在面对模糊文本条件时生成的检索结果精度低且特征相对单调的问题。通过在两个公开服装数据集fashioniq和shoes上进行的广泛实验中进行评估,证明了本发明的有效性。
- 还没有人留言评论。精彩留言会获得点赞!