基于字迹检测的古籍文本图像排序召回方法,系统及装置
本发明属于图像识别的,尤其涉及基于字迹检测的古籍文本图像排序召回方法,系统及装置。
背景技术:
1、敦煌遗书是20世纪初发现于敦煌莫高窟17号洞窟中的一批书籍的总称,指敦煌所出4至11世纪的古写本及印本。藏有汉文、藏文、回鹘文、粟特文、梵文、于阗文、吐火罗文等各种文字的古代遗书数万件,还有佛画幡幢等各种文物。具有极高的人文价值。但由于保护不周,敦煌遗书目前散落世界各地,且部分残损,对相关人文工作者造成了物质条件上的阻碍。然而,通过专家人工的进行残片缀合工作对人力成本要求极高且耗时较长。因此,迫切需要一种计算机辅助设计来帮助完成缀合工作。本发明基于同一片文书上作者为同一人的条件下对指定目标人物的字迹进行图像召回排序任务。
2、传统的图像召回排序方法在该场景下直接应用于该任务存在以下不适配性:
3、1)冗余特征复杂:该场景下的图像特征涉及到较多的冗余特征,即源自同一片文书上的残片可能由于不同的保护方法和拍摄方法导致有不同的背景纹理特征和明暗特点,可能对结果产生较大程度的扰动。
4、2)目标样本不同:传统图像召回排序仅基于一个目标样本提取特征在数据库中进行排序计算。但该场景下通常目标样本存在多张图像,且每张图像上存在多个字迹实例。
5、3)类别数量不同:传统图像召回通常应用于较复杂的自然场景下的图像召回排序,涉及较多特征类别,但该任务下图像分类根据字迹所属人物进行分类,类别数量较少。
6、专利文献cn116823650a公开了一种拍照文档图像增强方法、系统、装置及介质,其中方法包括:获取第一文档图像,以及获取所述第一文档图像对应的阴影图;根据所述第一文档图像和获得的阴影图进行光照矫正处理,得到第二文档图像;将所述第一文档图像和所述第二文档图像在通道维度进行拼接后,输入预设的第二深度卷积神经网络进行增强处理,输出第三文档图像,作为最终的增强结果。
7、专利文献cn115761781a公开了一种用于工程电子档案笔记图像数据识别系统,其原理框架包括笔记采集模块、笔记图像处理模块、图像类型检测模块、笔记分类储存模块和文本生成模块,所述笔记采集模块用于通过安装在书写笔上的拍摄模块对书写区进行拍照,同时通过定位模块对书写路径数据进行感应,通过设置的文本识别子模块中包括图像识别概率单元和书写路径识别概率单元,分别对每个字体单元与标准字体的图像相关度、笔尖笔画特征和笔画数据特征的笔画相似度进行计算,计算结果代入文本识别度降序排列,得到最大的文本识别度,最大的文本识别度对应的字体单元即为对应的文本。
技术实现思路
1、本发明的目的在于提供一种基于古籍文本图像的古籍文本字迹检测方法,系统及装置,该方法能高效召回目标字迹的数据,以实现古籍文本字迹检测的工作。
2、为了实现本发明的第一个目的,提供了一种基于古籍文本图像的古籍文本字迹检测方法,包括以下步骤:
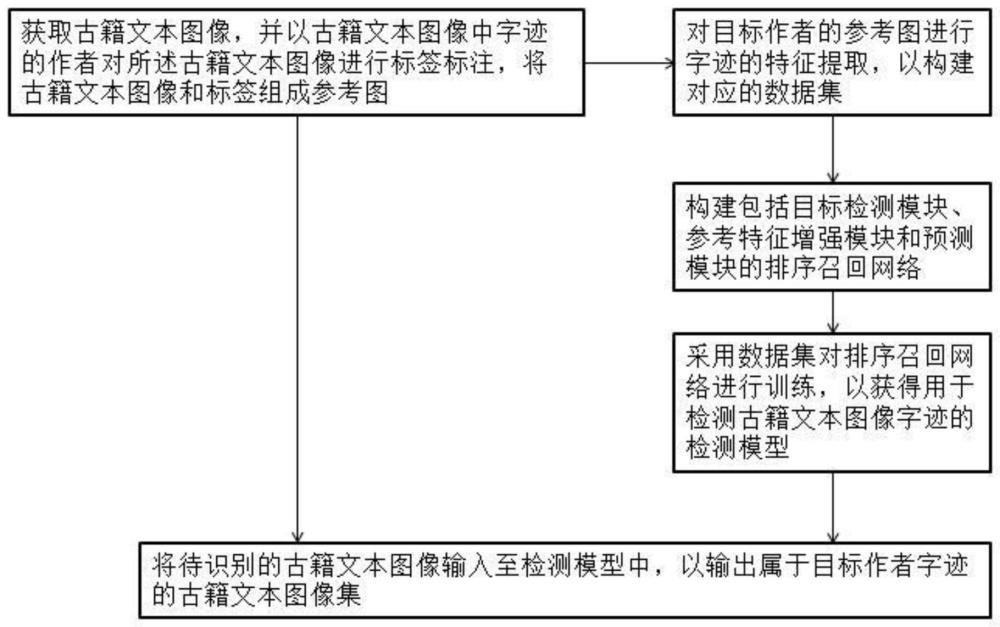
3、获取古籍文本图像,并以古籍文本图像中字迹的作者对所述古籍文本图像进行标签标注,将古籍文本图像和标签组成参考图;
4、对目标作者的参考图进行字迹的特征提取,以构建对应的数据集;
5、构建包括目标检测模块、参考特征增强模块和预测模块的排序召回网络,所述目标检测模块用于检测输入古籍文本图像中的文字,以生成包含字迹特征和检测框信息的排序特征数据,同时根据目标作者的参考图生成对应的参考特征数据,所述参考特征增强模块根据参考特征数据进行随机组合以获得增强参考特征数据,所述预测模块根据输入的排序特征数据和增强参考特征数据进行相似度分析,输出按照相似度从大到小排序的古籍文本图像;
6、采用数据集对排序召回网络进行训练,以获得用于检测古籍文本图像字迹的检测模型;
7、将待识别的古籍文本图像输入至检测模型中,以输出属于目标作者字迹的古籍文本图像集。
8、本发明基于detr的目标检测方法通过迁移学习的方式得到强鲁棒性的检测模型,根据detr检测模型的每个输出隐向量对应一个检测框的逻辑将所有隐向量进行聚合作为整张图的特征参与图像排序算法。同时,由于目标样本的参考图像可能存在多张且风格不同,在训练排序模型时通过在所有目标样本的参考图像提取出的输出隐向量中随机抽取固定数量的隐向量进行聚合,以此作为特征增强。
9、具体的,所述数据集的构建过程如下:
10、通过detr-based的目标检测算法对同一作者的所有古籍文本图像进行图像检测,以输出古籍文本图像中每个字体的排序特征数据,所述排序特征数据包括字迹特征及检测框信息;
11、以目标作者为单位将所属古籍文本图像的字迹特征进行随机组合,输出对应的重组排序特征数据,将排序特征数据和重组排序特征数据组成数据集,一方面能够避免不同文本图像间冗余特征带来的影响,另一方面也能通过不同的随机抽取进行数据扩充。
12、具体的,所述排序召回网络采用transformer的端到端目标检测算法进行构建。
13、具体的,在训练过程中,采用迁移学习将detr-based的目标检测框架引入预构建的排序召回网络中,并采用损失函数对排序召回网络进行参数的更新。
14、具体的,所述损失函数的表达式如下:
15、
16、其中,y为真实标签,为n项预测结果集合,为用于补齐y至n项的固定值,ci为目标类别标签,为预测类别为ci的概率,bi∈[0,1]4为真实目标检测框的中心相对坐标和长宽的向量,为和y之间元素的特定匹配排列。
17、具体的,所述相似度匹配单元采用余弦相似度计算公式分析排序特征数据和增强参考特征数据之间的相似度。
18、为了实现本发明的第二目的,提供了一种古籍文本图像排序召回系统,通过上述的基于字迹检测的古籍文本图像排序方法实现,包括:
19、图像获取模块,用于获取图像数据,其包括待识别古籍文本图像和目标作者的参考图;
20、图像增强模块,用于根据将待识别古籍文本图像和参考图进行数据处理,以输出对应的排序特征数据和参考特征数据;
21、图像排序模块,用于根据生成的排序特征数据和参考特征数据进行相似度匹配,并以输出的相似度匹配结果对待识别古籍文本图像进行排序,以相似度靠前的待识别古籍文本图像组成属于目标作者字迹的古籍文本图像集合。
22、为了实现本发明的第三个目的,提供了一种古籍文本图像排序召回装置,包括:
23、至少一个处理器;
24、至少一个存储器,用于存储至少一个程序;当所述至少一个程序被所述至少一个处理器执行,使得所述至少一个处理器实现基于字迹检测的古籍文本图像排序召回方法。
25、与现有技术相比,本发明的有益效果:
26、通过训练目标检测模型来约束提取出的隐向量有充分的检测框信息,使得提取出的隐向量与字迹检测区域强关联。并利用detr目标检测的每一个输出隐向量对应一个检测框的特殊形式来设计有效的特征增强,以此来减少参考图像之间非字迹轮廓的冗余特征的影响。
- 还没有人留言评论。精彩留言会获得点赞!