一种综合题目语义和难度的试题推荐神经网络模型
本发明涉及人工智能与智慧教育的交叉领域,具体是一种综合题目语义和难度的试题推荐神经网络模型,可应用于各个学科的在线教育平台、智能教学系统与智能测试系统中。
背景技术:
1、试题推荐是在线教育平台、智能教学系统与智能测试系统的关键组成部分,它可以根据学生做错试题,从试题库中推荐与之在试题标题上相似且试题难度相当的试题,以提高练习与测试的针对性。目前的经典神经网络模型与预训练语言模型只能处理试题标题语义,无法直接处理试题难度信息。因此,要想通过神经网络实现综合题目语义和难度的试题推荐任务,需要在网络结构与模型训练方法上进行改进。针对这些问题,本发明提出了一种综合题目语义和难度的试题推荐神经网络模型,具体包括一个综合处理题目语义与试题难度的神经网络模型及其训练方法。
技术实现思路
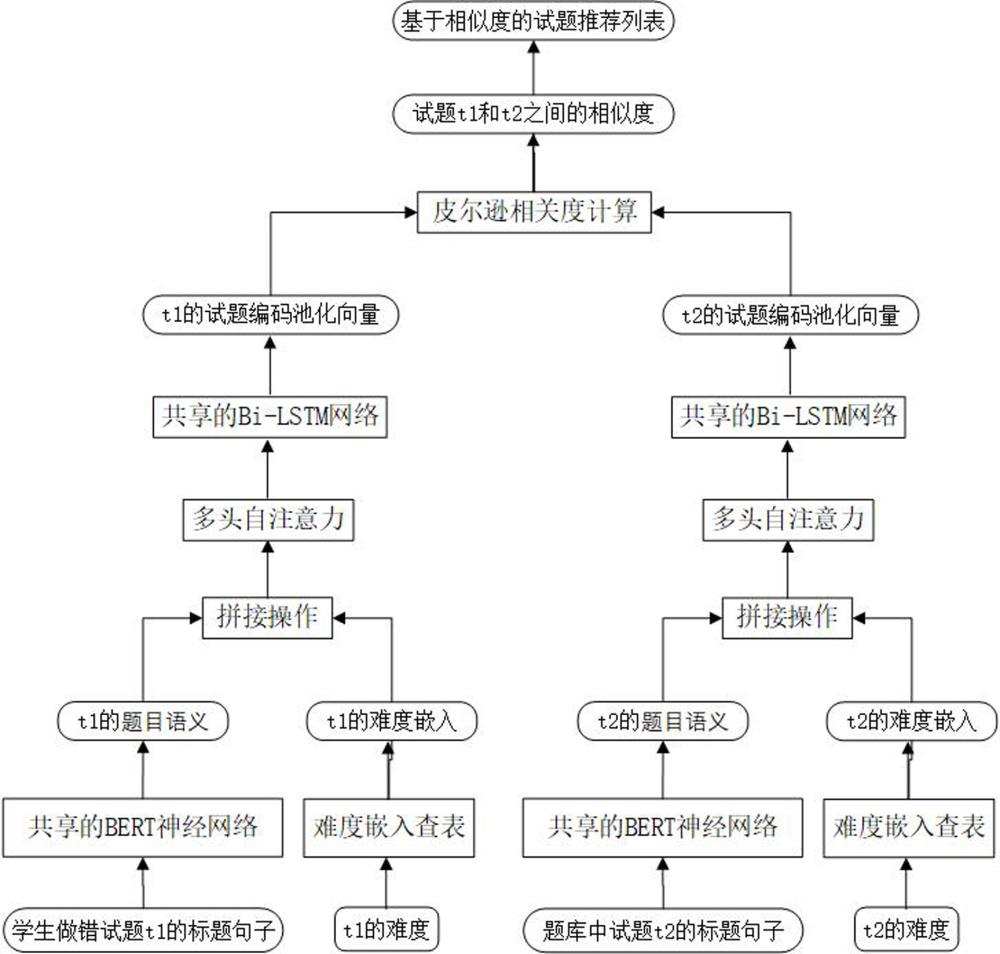
1、本发明公开了一种综合题目语义和难度的试题推荐神经网络模型,其特征在于包括以下步骤:
2、s1.以学生做错试题作为待推荐的目标试题t1,并针对目标试题t1,从试题库中选择一个试题t2,分别将它们的标题句子送入共享参数的bert预训练神经网络模型,得到试题t1的题目语义ht1和试题t2的题目语义ht2;
3、s2.分别将试题t1和t2的难度级别通过查表操作转换为难度嵌入e1和e2,并将e1和e2分别与题目语义ht1与ht2中的隐藏状态逐一连接,得到难度连接的题目语义ht′1和ht′2,然后再将ht′1和ht′2分别送入缩放点积多头自注意力,得到试题t1和t2的难度感知的题目语义和
4、s3.将难度感知的题目语义和分别送入共享参数的双向长短期记忆网络bi-lstm,得到试题t1和t2的试题编码和
5、s4.计算试题编码和之间的皮尔逊相关度,作为试题t1和t2之间的相似度;
6、s5.重复上述步骤s1到s4,直到得到题库中所有试题与目标试题t1之间的相似度,并按相似度的大小排序,得到一个针对目标试题t1的推荐列表;
7、所述bert预训练神经网络模型是指google ai language提出的bidirectionalencoder representations from transformers预训练语言模型;
8、所述难度嵌入是一种低维度、稠密的实数向量,每一级难度都有一个对应的难度嵌入,所有的难度嵌入开始时被随机生成,并在所述神经网络模型的训练过程中被不断更新;
9、所述难度是指试题的难易程度。
10、进一步的,所述步骤s1具体为:
11、将试题t1和试题t2的标题句子分别送入共享参数的bert预训练神经网络模型,得到试题t1的题目语义和试题t2的题目语义其中,n1、n2分别是试题t1和t2的标题句子在bert中切分出的子词个数,db是bert预训练神经网络模型中隐藏单元的数量,r为实数集合,分别是ht1和ht2中的隐藏状态序列。
12、进一步的,所述步骤s2具体包括:
13、s2.1分别将试题t1和t2的难度级别的one-hot独热向量,通过查表操作转换为对应的难度嵌入和所述de为难度嵌入的向量维度;
14、s2.2将试题t1的难度嵌入和t2的难度嵌入分别与ht1和ht2中的隐藏状态逐一连接,得到如下试题t1和t2的难度连接的题目语义ht′1和ht′2:
15、
16、
17、s2.3将ht′1和ht′2分别送入缩放点积多头自注意力,得到如下难度感知的题目语义和
18、
19、
20、其中,mhsa(·)表示缩放点积多头自注意力,mhsa(·)的计算过程如下:
21、mhsa(x)=tanh([head1;head2;...;headh]wr) (5)
22、headi=attention(xi,xi,xi)=attention(xwh,xwh,xwh) (6)
23、
24、其中,x∈rn×d为多头自注意力机制mhsa(·)的输入,d为输入x中序列的向量维度,headi表示多头自注意力中的第i个头,i=1,2,…,h,tanh(·)表示双曲正切函数,wr∈rd×d是可学习的参数矩阵,dh=d÷h,h是多头自注意力中注意力头的数量,xi表示第i个多头自注意力中的输入,xit中的上标t表示矩阵的转置操作,softmax(·)表示神经网络中的归一化指数函数。
25、进一步的,所述步骤s3具体为:
26、将难度感知的题目语义和分别送入共享参数的双向长短期记忆网络bi-lstm进行处理,得到试题t1和t2的试题编码和所述dl是bi-lstm中单个长短期记忆网络lstm中隐藏单元的数量,分别是和中的隐藏状态序列。
27、进一步的,所述步骤s4具体包括:
28、s4.1分别将试题编码和进行平均池化,得到的平均池化向量和的平均池化向量
29、s4.2按照如下公式,计算v1和v2之间的皮尔逊相关度,作为试题t1和t2之间的预测相似度:
30、
31、其中,是v1向量中的第i维度的值,是v2向量中的第i维度的值,分别是向量v1和v2中各维度值的平均值。
32、进一步的,所述步骤s5中,得到的针对目标试题t1的推荐列表list具体为:
33、
34、其中,m为题库中的试题集合,p为m中的一个试题,表示首先将题库中所有试题与t1的预测相似度进行降序排列,然后从降序排列中选择排在前k的k个试题作为推荐列表,k为用户指定的推荐列表的大小。
35、更进一步的,所述神经网络模型的训练过程具体包括:
36、(1)选择一个通用语义相似性语料作为所述神经网络模型的训练语料,并对其进行如下改进:首先给通用语义相似性语料中的每个句子随机赋给一个难度,然后按照如下公式重新计算综合难度的句子对s1和s2的标注相似度
37、
38、其中,句子对s1和s2表示构成通用语义相似性语料中一个样本的两个句子,分别是句子s1和s2的难度,表示句子对s1和s2在原始的通用语义相似性语料中的相似度;
39、(2)按照公式(10)重新计算并替换原始的通用语义相似性语料中所有句子对的标注相似度,形成综合难度的语义相似性语料;
40、(3)使用所形成的综合难度的语义相似性语料,对权利要求1所述的神经网络模型进行训练,其中将语义相似性语料中的句子对s1和s2作为所述神经网络模型中试题t1和t2的标题句子,并使用下述公式作为训练过程中的回归损失函数:
41、
42、其中,k为每批次训练样本的大小,yi为采用公式(10)计算的第i个训练样本的标注相似度,为采用公式(8)计算的第i个训练样本的预测相似度;
43、所述通用语义相似性语料是指公开发布的、用于句子间语义相似度测量的训练语料。
44、本发明具有以下优点:
45、(1)为综合处理题目语义与试题难度,提出一种由bert预训练语言模型、多头自注意力和双向长短期记忆网络组成的神经网络模型。
46、(2)提出了一套将通用语义相似性语料改进为所述神经网络模型训练语料的方法。
47、(3)提出了一种基于均方误差的回归损失函数。
48、(4)模型所提供的试题推荐列表,综合考虑了题目语义与试题难度,从而更具有针对性。
- 还没有人留言评论。精彩留言会获得点赞!