全局融合交叉自注意力网络的混合架构图像重建方法与流程
本发明涉及计算机视觉,特别是涉及一种全局融合交叉自注意力网络的混合架构图像重建方法。
背景技术:
1、随着人工智能的不断发展,超分辨率重建技术在视频图像压缩传输、医学成像、遥感成像、视频感知与监控等领域得到了广泛的应用与研究。图像超分辨率重建将低分辨率图像转换为高分辨率图像,以获得尽可能接近真实图像的图像。基于神经网络的图像超分辨率重建算法层出不穷,并取得了显著成果。这些算法包括基于cnn的算法和基于视觉transformer的超分辨率算法。基于cnn的方法具有预测细节的强大局部建模能力,探索小邻域中像素之间的关系。然而只关注局部信息的提取,会忽略了像素之间的全局信息,必然影响全局结构的恢复,导致生成的图像出现模糊效果。基于视觉transformer的方法在图像处理中具有自注意机制的优势,能够更好地捕捉全局信息。然而它缺乏对分层特征的有效捕捉和对局部信息的获取能力,导致transformer在处理细节和纹理时出现模糊或失真。
2、在过去的十年中,随着深度学习的快速发展,深度学习已广泛应用于视觉图像的各个方面。基于深度学习的图像超分辨率重建发展迅速。大多数基于深度学习的算法主要改善网络结构和损失函数。另外,为了探索特征图之间的依赖性,许多算法引入了注意力机制以增强层次信息融合的准确性。
3、我们总结了一些超分辨率重建算法,发现研究人员主要从三个方面进行了改进:网络结构,层次信息融合和损失函数。在网络结构方面,研究人员最初考虑基于残差网络或密集块来扩展和深化网络结构,并从“挤压-激发”模块中获得灵感。最近,随着transformer模型被引入到计算机视觉任务中,网络结构逐渐向基于transformer的网络发展。对于损失函数,越来越多的网络开始基于三元组损失进行改进,它使网络能够在特征空间而不是像素空间中将sr(超分辨率图像)和hr(高分辨率图像)之间的差距最小化,从而可以提高生成图片的质量。
4、但是,真实图像和伪图像之间仍然有很大的差距。基于cnn的方法会忽略了像素之间的全局信息,基于视觉transformer的方法缺乏对分层特征的有效捕捉和对局部信息的获取能力。总是倾向于提取深层特征,而忽略了低层特征,这意味着仅高阶特征是近似的,并且在低层特征中,sr和hr之间仍然有很大差距。
技术实现思路
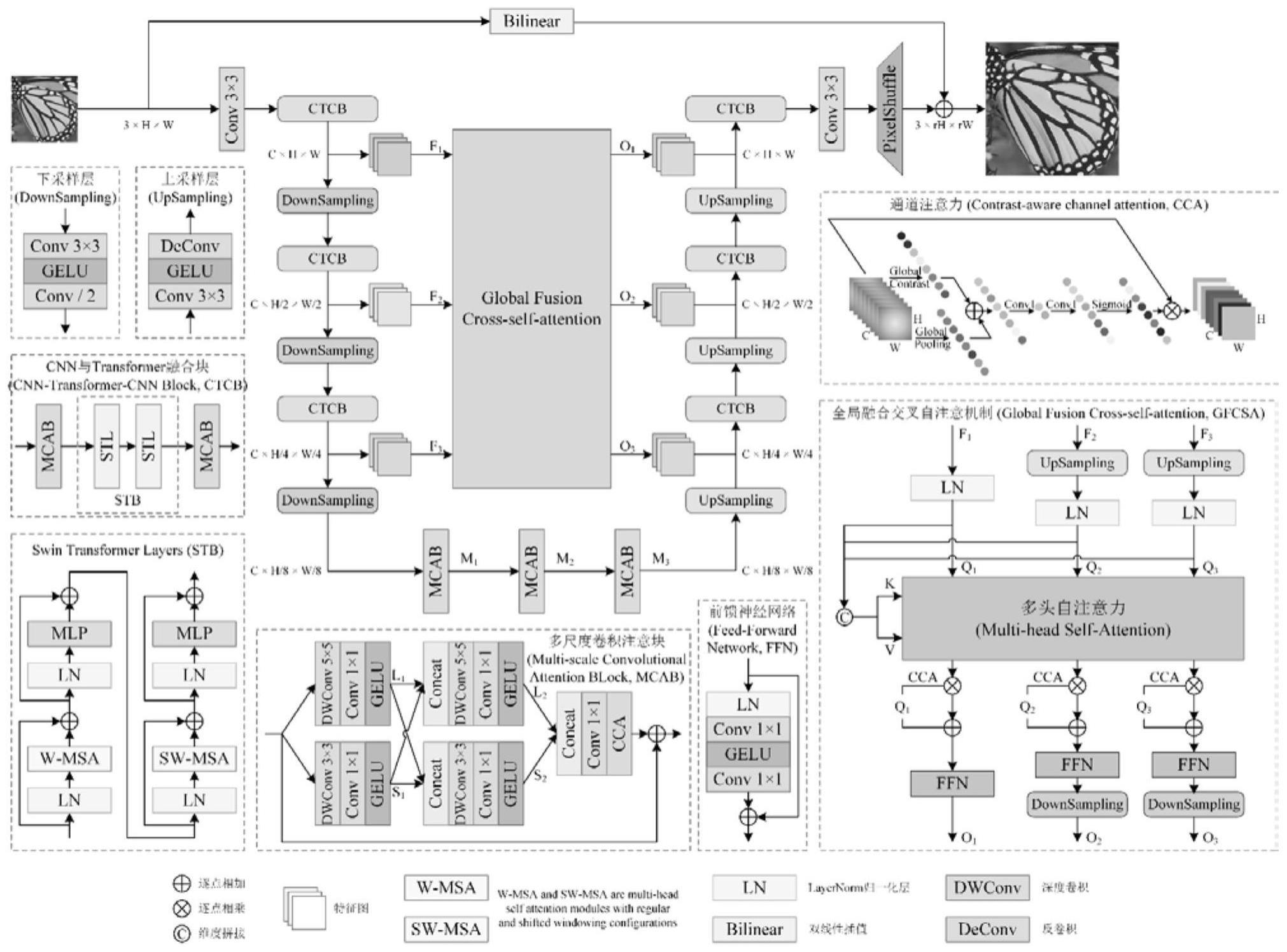
1、为了解决上述现有技术中的不足,本发明将cnn与transformer结构融合,提出一种混合架构的全局融合交叉自注意力网络的低分辨率图像重建方法,以便整个网络不仅可以在高层特征中近似原始图像,而且可以在低层特征中近似原始图像。
2、本发明解决其技术问题所采用的技术方案为:
3、提供了一种全局融合交叉自注意力网络的混合架构图像重建方法,包括以下步骤:
4、s1:低分辨率图像经过第一个卷积层后获得浅层特征f0;
5、s2:浅层特征f0通过由cnn与transformer融合块组成的三组平编码器,这些编码器依次使用下采样层减小空间大小,并将特征转换成不同分辨率的多尺度特征,之后通过网络所构建的全局融合交叉自注意机制来适应融合并弥合不同尺度特征之间的差距,生成输出特征oi;
6、s3:生成第一个解码器的输入mi,通过三个紧密相连的多尺度卷积注意块,加强对局部信息的获取能力;
7、s4:全局融合交叉自注意机制的最低分辨率输出特征作为最后一级解码器ctcb的输入,将解码器输出特征和相同分辨率全局融合交叉自注意机制输出特征之和作为输出,逐步恢复和丰富原始尺度表示,用上采样层放大图像大小;
8、s5:对提取的深层解码器特征进行重构,并通过3×3卷积层和pixelshuffle层进行上采样,再加上bilinear插值的结构得到最终的sr结果。
9、进一步的,步骤s1中,f0计算公式如下:
10、
11、其中,表示第一个卷积层,ilr表示低分辨率图片,f0表示浅层特征。
12、进一步的,步骤s2中,多尺度特征计算公式如下:
13、
14、其中,ctcbi表示第i个编码器,downsampling表示下采样层,fi表示中间特征;
15、ctcb由两个mcab结构和一组stl组成,给定输入x,输出为y,可以表示成:
16、y=mcab2(stb(mcab1(x)))
17、其中,stb为一组stl层,mcab1和mcab2是多尺度卷积注意块;
18、在计算出f3后,根据[f1,f2,f3]输出融合尺度特征,计算公式如下:
19、[o1,o2,o3]=gfcsa(f1,f2,f3)
20、其中,gfcsa表示全局融合交叉自注意,fi表示编码器中间特征,oi表示通过gfcsa生成的输出特征。
21、进一步的,步骤s2中,全局融合交叉自注意机制构建方法包括以下步骤:
22、s1:对输入特征[f1,f2,f3]进行处理,让其大小保持一致,upsampling表示上采样层,计算公式如下:
23、
24、s2:构建多头自注意力的键值对q、k、v,其计算公式如下:
25、q1=f1,q2=f2,q3=f3
26、k=w1(concat(f1f2,f3))+b1
27、v=w2(concat(f1,f2,f3))+b2
28、其中,wi、bi表示针对k、v的可学习的权重偏置矩阵,concat表示通道拼接;
29、s3:分别对q1,q2,q3分别进行多头自注意力,得到输出结果,多头自注意力可以表示为:
30、multihead(q,k,v)=concat(head1,...,headh)wo
31、其中,q、k、v分别表示查询向量、键向量和值向量,h表示头的数量,headi表示第i个头的输出,wo是输出变换矩阵,concat表示通道拼接,每个头的输出headi可以表示为:
32、headi=attention(qwiq,kwk,vwiv)
33、其中,wiq、wik、wiv分别是第i个头的查询、键、值变换矩阵,attention是注意力计算函数;
34、attention计算公式如下:
35、
36、其中,dk是键向量的维度,softmax相似度进行归一化,将每个键向量的权重计算出来,然后将权重乘以值向量,最后进行加权求和得到注意力输出。
37、进一步的,在分别进行完多头自注意力后,得到中间输出a1、a2、a3,该过程计算公式如下:
38、ai=multihead(qi,k,v),i=1,2,3
39、之后将多头自注意力得到的输出与通道注意力进行结合,该过程计算公式如下:
40、ai=cca(qi)×ai+qi,i=1,2,3
41、再依次经过前馈神经网络,缩放回指定大小,得到最终的输出结果[o1,o2,o3],其计算公式包括如下:
42、
43、其中,前馈神经网络模块由一个标准化层,两个卷积和一个激活函数组成,给定输入x,输出为y,可以表示成:
44、y=conv2(gelu(conv1(layernorm(x))))+x
45、其中,n为layernorm层,gelu表示激活函数,conv1和conv2为普通的1x1卷积,加法代表逐元素相加。
46、进一步的,步骤s3中,使用f3生成第一个解码器的输入m3,其计算公式如下:
47、
48、其中,mcabi表示第i个多尺度卷积注意块,mi表示紧密相连的mcab块所生成的中间特征;
49、或者,给定输入x,输出为y,多尺度卷积注意块获取信息过程如下:
50、
51、
52、
53、
54、
55、其中,bi表示每一组卷积的权重和偏置,b3表示最后用来进行通道降维的1x1卷积,cca表示通道注意力,加法代表逐元素相加。
56、进一步的,通道注意力由两个1x1卷积、全局标准差、全局平均池化和激活函数构成,给定输入x,输出为f,计算公式如下:
57、
58、
59、
60、其中,conv1和conv2为1×1卷积层,hgc为全局标准差,hgp为全局平均池化,表示逐元素乘法;
61、令x=[x1,…,xn]作为输入,其中有n个空间大小为h×w的特征映射。全局标准差和全局平均池化表示为:
62、
63、
64、步骤s4中,用上采样层放大图像大小的计算公式如下:
65、
66、其中,ctcbi表示第i个解码器,upsampling表示上采样层,oi表示通过gfcsa生成的输出特征,pi表示中间特征。
67、步骤s5中,sr计算公式如下:
68、
69、所述下采样层由两个卷积加一个激活函数组成,给定输入x,输出为y,计算公式如下:
70、y=conv2(gelu(conv1(x)))
71、其中,conv1为普通的3x3卷积,gelu表示激活函数,conv2表示步长为2的3x3卷积;
72、或者,所述上采样模块由两个卷积加一个激活函数组成,给定输入x,输出为y,计算公式如下:
73、y=deconv(gelu(conv(x)))
74、其中,conv为普通的3x3卷积,gelu表示激活函数,deconv表示反卷积用于放大图像。
75、与现有技术相比,本发明的有益效果在于:
76、1、本发明将cnn与transformer结构融合,提出一种混合架构的全局融合交叉自注意力网络的低分辨率图像重建方法,以便整个网络不仅可以在高层特征中近似原始图像,而且可以在低层特征中近似原始图像;
77、2、本发明设计全局融合交叉自注意力模块,以使图像的高层和低层特征的都得到充分的交互,并使最终的sr图像更接近原始图像,包括通道注意力和多头自注意力,通道注意力可以自适应地调整高阶统计特征中的通道相互依赖性;多头自注意力机制可以增加模型的表达能力和泛化能力,让网络关注更值得被关注的内容,通过两个注意力机制的约束,可以将几何特征更准确地应用于全局图像结构;
78、3、本发明引入具有无参数的双线性插值方法,它可以有效地传递大量的信息,从而引导网络的注意力到细致的细节还原上,以获得最终特征。
- 还没有人留言评论。精彩留言会获得点赞!