一种基于机器学习的文本推荐方法
本发明涉及语义提取,具体涉及一种基于机器学习的文本推荐方法。
背景技术:
1、随着大数据时代的到来,各类资料爆炸式增长,从海量的资料中筛选出用户所需内容需要耗费大量的时间。现有为了提高筛选用户所需内容的效率,提供了文本推荐方法。现有文本推荐方法为:对用户输入的文本信息进行分词处理,提取出关键词,根据各个关键词在各个文档资料中出现的频率,从而得到各个文档资料的优先级,进而按优先级进行文本推荐。现有文本推荐方法对于简单的文本信息能达到较精确的推荐,但是对于包含几种语义的复杂文本信息,其无法准确获取其中用户关注的内容,造成文本推荐有误差。
技术实现思路
1、针对现有技术中的上述不足,本发明提供的一种基于机器学习的文本推荐方法解决了现有文本推荐方法对复杂文本信息进行文本推荐,存在推荐精度较低的问题。
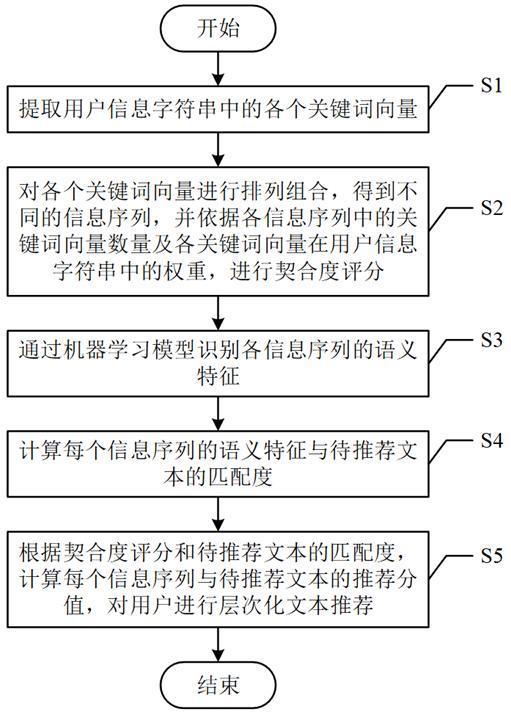
2、为了达到上述发明目的,本发明采用的技术方案为:一种基于机器学习的文本推荐方法,包括以下步骤:
3、s1、提取用户信息字符串中的各个关键词向量;
4、s2、对各个关键词向量进行排列组合,得到不同的信息序列,并依据各信息序列中的关键词向量数量及各关键词向量在用户信息字符串中的权重,进行契合度评分;
5、s3、通过机器学习模型识别各信息序列的语义特征;
6、s4、计算每个信息序列的语义特征与待推荐文本的匹配度;
7、s5、根据契合度评分和待推荐文本的匹配度,计算每个信息序列与待推荐文本的推荐分值,对用户进行层次化文本推荐。
8、本发明的有益效果为:本发明中对用户信息字符串中各个关键词进行了排列组合,从而得到不同的信息序列,相当于是从一个用户信息字符串中获取出各种相关的信息,扩宽推荐范围,本发明根据每个信息序列包含的关键词数量以及包含的关键词的权重,从而衡量出一个信息序列的契合度评分。本发明中还通过机器学习模型识别各信息序列的语义特征,实现对各信息序列进一步的语义提取,计算出每个信息序列的语义特征与待推荐文本的匹配度,再综合信息序列与用户信息字符串的契合度评分,计算出待推荐文本的推荐分值,从而实现层次化的文本推荐,增加了文本推荐的范围,并将所有有关的文本均进行推荐,提高对复杂文本信息进行文本推荐的精度。
9、进一步地,所述s2包括以下分步骤:
10、s21、对各个关键词向量进行排列组合,得到不同的信息序列;
11、s22、统计每个信息序列中关键词向量数量;
12、s23、根据每个信息序列中关键词向量在用户信息字符串的权重,得到信息序列重要度;
13、s24、根据每个信息序列中关键词向量数量和重要度,计算每个信息序列的契合度评分。
14、上述进一步地方案的有益效果为:对各个关键词向量进行排列组合,得到不同的信息序列,从而获取所有与用户信息字符串相关的内容,根据关键词在用户信息字符串的权重,评估出每个信息序列的重要度,从而根据每个信息序列中关键词向量数量和重要度,计算出每个信息序列与用户信息字符串的契合度评分。
15、进一步地,所述s24中计算每个信息序列的契合度评分的公式为:
16、,
17、其中, score k为第 k个信息序列的契合度评分, nu k为第 k个信息序列中关键词向量的数量, in k为第 k个信息序列的重要度, k为信息序列的编号;
18、所述第 k个信息序列的重要度 in k的计算公式为:
19、,
20、其中, l k,l为第 k个信息序列中第 l个关键词向量的长度, k k,l为第 k个信息序列中第 l个关键词向量在用户信息字符串中出现的次数, l u为用户信息字符串的长度, ω k,l为第 k个信息序列中第 l个关键词向量在用户信息字符串的权重, nu k为第 k个信息序列中关键词向量的数量, l为关键词向量的编号。
21、上述进一步地方案的有益效果为:本发明中每个信息序列的契合度评分与信息序列中关键词向量数量和信息序列的重要度有关,在关键词向量数量越多和信息序列的重要度越大时,信息序列与用户信息字符串的契合度评分越高,在信息序列中关键词向量的长度越长,出现在用户信息字符串中的数量越多,权重越大,则信息序列的重要度越大。
22、进一步地,所述s3中机器学习模型包括:关键词处理单元、特征汇集单元、双通道特征提取单元和全连接层;
23、一个所述关键词处理单元的输入端用于输入信息序列中的关键词向量,关键词处理单元的数量大于等于2;所述特征汇集单元的输入端与各关键词处理单元的输出端连接,其输出端与双通道特征提取单元的输入端连接;所述全连接层的输入端与双通道特征提取单元的输出端连接,其输出端作为机器学习模型的输出端。
24、上述进一步地方案的有益效果为:本发明中采用每个关键词处理单元处理信息序列中每个关键词向量,实现对信息序列中关键词向量并行处理,更好的考虑一段信息中前后语义关系,提高语义提取的准确度,再在特征汇集单元实现各个关键词特征的汇集,并通过双通道特征提取单元进一步的提取特征,实现对语义特征的提取。
25、进一步地,所述关键词处理单元包括:第一relu激活层、第二relu激活层、第一tanh激活层、第二tanh激活层、归一化层、加法器和乘法器;
26、所述第一relu激活层的输入端分别与第二relu激活层的输入端和归一化层的输入端连接;所述第一tanh激活层的输入端与第一relu激活层的输出端连接,其输出端与加法器的第一输入端连接;所述第二tanh激活层的输入端与第二relu激活层的输出端连接,其输出端与加法器的第二输入端连接;所述乘法器的第一输入端与加法器的输出端连接,其第二输入端与归一化层的输出端连接;
27、所述双通道特征提取单元包括:avgpool层、maxpool层和lstm层;
28、所述avgpool层的输入端与maxpool层的输入端连接,并作为双通道特征提取单元的输入端;所述lstm层的输入端分别与avgpool层的输出端和maxpool层的输出端连接,其输出端并作为双通道特征提取单元的输出端。
29、上述进一步地方案的有益效果为:本发明中在关键词处理单元设置了两个relu激活层分别对输入的关键词向量进行处理,提高机器学习模型拟合非线性关系的能力,两个tanh激活层用于将relu激活层输出的量映射到-1和1之间,使得机器学习模型更稳定,同时第一relu激活层、第二relu激活层、第一tanh激活层、第二tanh激活层和归一化层构成了三个输入通道,实现对输入的关键词向量进行三路不同的处理,得到不同的特征,实现特征的充分提取。
30、在双通道特征提取单元中lstm层的输入有两个:avgpool层的输出和maxpool层的输出,在lstm层中综合了显著特征和全局特征。
31、进一步地,所述第一relu激活层的表达式为:
32、,
33、其中, r1 ,t为第一relu激活层第 t时刻的输出,relu为非线性激活函数, x t为第 t时刻输入的关键词向量, w r1为第一relu激活层中第 t时刻输入的关键词向量 x t的权重, r a,t-1为乘法器第 t-1时刻的输出, w rr1为第一relu激活层中乘法器第 t-1时刻的输出 r a,t-1的权重, b r1为第一relu激活层中的偏置, t为时刻的编号;
34、所述第二relu激活层的表达式为:
35、,
36、其中, r2 ,t为第二relu激活层第 t时刻的输出, w r2为第二relu激活层中第 t时刻输入的关键词向量 x t的权重, w rr2为第二relu激活层中乘法器第 t-1时刻的输出 r a,t-1的权重, b r2为第二relu激活层中的偏置。
37、上述进一步地方案的有益效果为:在第一relu激活层和第二relu激活层中,考虑了上一时刻乘法器的输出情况,结合了历史语义信息,能更好预测信息序列的语义特征。
38、进一步地,所述特征汇集单元的表达式为:
39、,
40、其中, v t为特征汇集单元第 t时刻的输出, r a,t,1为第1个关键词处理单元第 t时刻的输出, r a,t,j为第 j个关键词处理单元第 t时刻的输出, r a,t,m为第 m个关键词处理单元第 t时刻的输出, m为关键词处理单元的数量, j为关键词处理单元的编号, w r,1为特征汇集单元中 r a,t,1的权重, w r,j为特征汇集单元中 r a,t,j的权重, w r,m为特征汇集单元中 r a,t,m的权重,为哈达玛积, t为时刻的编号。
41、进一步地,所述s4包括以下分步骤:
42、s41、将待推荐文本按标点符号进行分句处理,得到多个短句文本;
43、s42、根据每个信息序列的语义特征与每个短句文本的余弦相似度,得到信息序列的语义特征与待推荐文本相似度;
44、s43、将每个信息序列的语义特征进行分词处理,得到每个词向量;
45、s44、统计每个词向量在待推荐文本中出现的次数;
46、s45、根据词向量在待推荐文本中出现的次数,以及信息序列的语义特征与待推荐文本相似度,得到信息序列的语义特征与待推荐文本的匹配度。
47、上述进一步地方案的有益效果为:本发明中将待推荐文本按标点符号进行分句处理,从而得到多个短句文本,便于计算与每个信息序列的语义特征的余弦相似度,综合各个短句文本的余弦相似度,得到信息序列的语义特征与待推荐文本相似度,将每个信息序列的语义特征进行分词处理,统计每个词向量在待推荐文本中出现的次数,根据词向量在待推荐文本中出现的次数,以及信息序列的语义特征与待推荐文本相似度,得到信息序列的语义特征与待推荐文本的匹配度,本发明中通过信息序列的语义特征与待推荐文本相似度,评估出该信息序列的语义特征与待推荐文本的行文排布是否相似,通过词向量的出现次数评估待推荐文本中存在相关内容的量的大小。
48、进一步地,所述s42中信息序列的语义特征与待推荐文本相似度的计算公式为:
49、,
50、其中, s k为第 k个信息序列的语义特征与待推荐文本相似度, s k,c为第 k个信息序列的语义特征与第 c个短句文本的余弦相似度, x为短句文本的数量;
51、所述s45中信息序列的语义特征与待推荐文本的匹配度的计算公式为:
52、,
53、其中, p k为第 k个信息序列的语义特征与待推荐文本的匹配度, o k,m为第 k个信息序列的语义特征的第 m个词向量在待推荐文本中出现的次数, w k,m为第 k个信息序列的语义特征中第 m个词向量的权重, t为一个信息序列对应的语义特征中词向量数量, m为词向量的编号, k为信息序列的编号。
54、上述进一步地方案的有益效果为:本发明综合信息序列的语义特征中词向量在待推荐文本中出现的次数,词向量的权重,以及语义特征与待推荐文本相似度,评判出信息序列的语义特征与待推荐文本的匹配度。
55、进一步地,所述s5中计算信息序列与待推荐文本的推荐分值的公式为:
56、,
57、其中, y k为第 k个信息序列与待推荐文本的推荐分值, p k为第 k个信息序列的语义特征与待推荐文本的匹配度, score k为第 k个信息序列的契合度评分, ln为对数函数, e为自然常数。
58、上述进一步地方案的有益效果为:本发明中在推荐分值越高时,该待推荐文本与信息序列的语义特征匹配度越高,信息序列与用户信息字符串的契合度越高,实现从信息序列本身是否还原用户信息字符串的语义,以及推荐文本中存在语义特征内容的多少的两个角度出发,推荐更精确的文本。
- 还没有人留言评论。精彩留言会获得点赞!