一种基于集成学习的数据库内部人员攻击检测方法、系统、设备及介质
本发明涉及数据窃取检测,具体涉及一种基于集成学习的数据库内部人员攻击检测方法、系统、设备及介质。
背景技术:
1、当前数据已成为国家的重要战略资源,是驱动经济社会发展的新型生产要素。由于数据库是数据的存储载体,数据库安全对于组织机构(如公司、政府部门等)保护数据并防范多种外部、内部威胁具有重大意义。常见的外部威胁包括未经授权的访问、黑客入侵、病毒、勒索软件、分布式拒绝服务(ddos)、钓鱼攻击等;对于这类威胁,我们往往可以利用网络防火墙、杀毒软件、用户身份验证等访问控制机制进行有效防护。常见的内部威胁分为伪装者和内部人员:伪装者是指黑客通过盗取用户名、密码等凭证,从而将自己伪装成内部人员访问数据库;根据是否故意攻击数据库,内部人员又可分为恶意的和粗心大意的内部人员等。将伪装者和恶意内部人员攻击数据库以窃取机密数据(如用户信息记录、商业机密、军事机密、知识产权等)等行为称为内部人员攻击。由于内部人员攻击的发起者获得了数据库的访问凭证,传统访问控制机制往往不再起作用。加之内部人员确切地知道敏感数据的存储位置以及系统部署了哪些网络安全措施,内部人员攻击检测极具挑战性。
2、现有内部人员攻击检测方法主要利用贝叶斯网络、聚类、隐马尔科夫模型等机器学习方法来分析用户与数据库之间的互动模式是否存在异常。根据所采用的机器学习模型的输入特征向量,现有内部人员攻击检测方法可以分成3大类:(1)语法检测方法;(2)语义检测方法;(3)以及混合检测方法。其中,语法检测方法的基本思想是利用机器学习模型来分析用户对数据库进行增、删、改、查等一系列操作时所输入的sql语句的语法特征。常用的语法特征为sql命令类型、范围表(即查询所引用的表)、投影列表(包括出现在查询结果集中的属性以及出现在where子句中的属性)。由于语法特征只需要解析sql语句字符串并遍历所生成的语法解析树,因而可以快速提取。由于伪装者通常不了解真实帐户所有者的访问模式,因此不太可能执行与帐户所有者的典型行为一致的操作,这也导致伪装者与正常用户的sql语句的查询结构存在显著差异。因此,基于语法的检测方法常常对于伪装攻击十分有效。语义检测方法的基本思想是利用机器学习方法来对查询结果集中的数据进行分析。常用的语义特征包括结果集的相关统计信息(如行数、列数、结果集中的数据占各原始表数据的百分比)、结果集的数据量大小、以及结果集所对应的原始元组。由于需要执行查询、解析查询结果、将查询结果与受监控数据库中的原始元组进行匹配,因此提取语义特征的成本可能会很高。然而,与语法检测相比,语义检测能够应对更复杂的内部人员攻击。这是因为数据库内部人员攻击常常涉及提取超出正常大小的数据或查看超出内部人员工作职能范围的数据记录。混合检测方法则通常利用现有机器学习模型同时对上述语法特征和语义特征同时进行分析。
3、由此可得,现有方法只考虑了数据库内部人员攻击所产生的“结果”(sql语句的语法及语义),而未考虑职员发起内部人员攻击的“动机”(其根本原因),从而使得检测精度较低、误检率和漏检率较高。
4、公开号为cn115277113a的专利申请文件中,公开了一种基于集成学习的电网网络入侵事件检测识别方法,基于集成学习的电网网络入侵事件检测识别方法,通过利用随机森林和xgboost,基于集成学习的网络入侵事件检测、识别方法,通过多分类器集成学习的模式,不断强化对小样本异常事件的学习。但是由于数据库内部人员攻击的攻击模式复杂,特征众多。从而产生了检测精度较低、误检率和漏检率较高的问题。
5、公开号为cn113014529b的专利申请文件中,公开了网络攻击的识别方法、装置、介质及设备,通过获取预设时段内的日志数据,确定易受攻击目标,所述易受攻击目标包括指定的路径和/或url类型;基于所述易受攻击目标,构造用户行为特征并建立数据集合;基于所述数据集合训练机器学习模型并提取决策逻辑,构造算法规则并验证;将验证通过的算法规则用于网络攻击的识别,但是由于考虑的特征较为单一,并未考虑职员发起内部人员攻击的“动机”,从而产生了检测精度较低、误检率和漏检率较高的问题。
技术实现思路
1、为了克服上述现有技术的不足,本发明的目的在于提供一种基于集成学习的数据库内部人员攻击检测方法、系统、设备及介质,不仅充分考虑内部人员与数据库进行交互时的各种语法特征和语义特征,同时也考虑内部人员自身画像信息,并利用随机森林分别对上述三方面因素进行分析,从而充分挖掘内部人员攻击的结果和动机,使得该方案具有较高的检测精度;采用集成学习的方法,将各随机森林的检测结果进行综合考量,从而使得数据库内部人员攻击的检测准确率较高,而误检率和漏检率较低;同时,利用集成学习的思想也可以有效提高检测模型的泛化能力;此外,通过枚举调优策略来确定每个子模型(即随机森林)中决策树的棵树,即每个子模型的规模,使每个子模型的规模达到最优,较大程度的避免了每个子模型陷入局部最优;根据二项分布模型计算子模型融合阈值,在误检率满足一定的条件下(即不超过某个事先指定的值),使得漏检率尽可能低。
2、为了实现上述目的,本发明采取的技术方案是:
3、一种基于集成学习的数据库内部人员攻击检测方法,包括以下步骤:
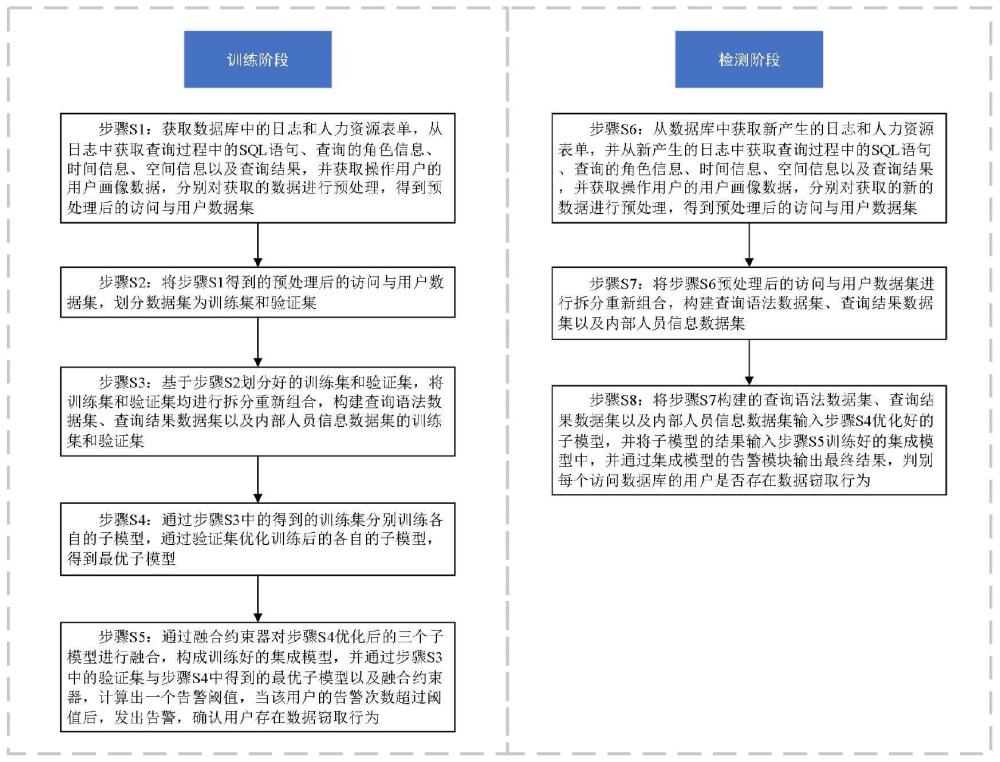
4、步骤s1:获取数据库中的日志和人力资源表单,从日志中获取查询过程中的sql语句、查询的角色信息、时间信息、空间信息以及查询结果,并获取操作用户的用户画像数据,分别对获取的数据进行预处理,得到预处理后的访问与用户数据集;
5、步骤s2:将步骤s1得到的预处理后的访问与用户数据集,划分为训练集和验证集;
6、步骤s3:基于步骤s2划分好的训练集和验证集,将训练集和验证集均进行拆分重新组合,构建查询语法数据集、查询结果数据集以及内部人员信息数据集的训练集和验证集;
7、步骤s4:使用步骤s3中得到的训练集分别训练各自的子模型,通过验证集优化训练后的各自的子模型,得到最优子模型;
8、步骤s5:通过融合约束器对步骤s4优化后的三个子模型进行融合,构成训练好的集成模型,并通过步骤s3中的验证集和步骤s4中得到的最优子模型以及融合约束器,计算出一个告警阈值,当该用户的告警次数超过阈值后,发出告警,确认用户存在数据窃取行为;
9、步骤s6:从数据库中获取新产生的日志和人力资源表单,并从新产生的日志中获取查询过程中的sql语句、查询的角色信息、时间信息、空间信息以及查询结果,并获取操作用户的用户画像数据,分别对获取的新的数据进行预处理,得到预处理后的访问与用户数据集;
10、步骤s7:将步骤s6预处理后的访问与用户数据集进行拆分重新组合,构建查询语法数据集、查询结果数据集以及内部人员信息数据集;
11、步骤s8:将步骤s7构建的查询语法数据集、查询结果数据集以及内部人员信息数据集输入步骤s4优化好的最优子模型,并将子模型的结果输入步骤s5训练好的集成模型中,并通过集成模型的告警模块输出最终结果,判别每个访问数据库的用户是否存在数据窃取行为。
12、进一步的,所述步骤s1包括:
13、步骤s11:获取有n个表的数据库的日志和人力资源表单,从有n个表的数据库的日志中提取sql语句,将sql语句中的操作符标记为oc,访问的表的特征标记为at,访问表的属性特征标记为aa,标记fi表示表i是否被访问,标记mi表示表i中被访问的属性总数,则at={f1,f2,…,fn},aa={m1,m2,…,mn};
14、步骤s12:从步骤s11获取的有n个表的数据库的日志中,提取用户角色标记为ur,访问时间标记为ta,访问地理位置标记为sa,并将ur和sa采用标签编码的方式进行处理,将ta采用只取整点时间的方式进行处理;
15、步骤s13:从步骤s11获取的有n个表的数据库的日志中提取查询结果,将查询结果的条数标记为rn,查询结果包含的属性数标记为ra,查询结果的大小标记为rs,查询结果的分布特征rt,rt代表查询结果从每个表中获取数据占该表的比例,标记pi表示查询结果中从表i中获取的条数占该表总条数的比值;则rt={p1,p2,…,pn};
16、步骤s14:从步骤s11获取的人力资源表单中提取每条访问对应的内部人员的月工资标记为sm,内部人员的工作绩效标记为pw,内部人员的工作年限标记为yw,内部人员的月工作时长标记为hw,内部人员在五年内是否晋升标记为p5,并将sm和hw采用w分之一位数,w分之二位数,…,w分之w-1位数,划分为w个等级进行其数据处理。
17、进一步地,所述步骤s3包括:
18、步骤s31:将步骤s2划分好的训练集和验证集按特征拆分;
19、步骤s32:将步骤s31拆分后的数据集重组,构建查询语法数据集,查询语法数据集是通过将ur、oc、at和aa组合在一起构成的数据集d1,数据集d1包括训练集和验证集;
20、步骤s33:将步骤s31拆分后的数据集重组,构建查询结果数据集,查询结果数据集是通过将ur、oc、at、rn、ra、rs和rt组合在一起构成的数据集d2,数据集d2包括训练集和验证集;
21、步骤s34:将步骤s31拆分后的数据集重组,构建内部人员信息数据集,内部人员信息数据集是通过将ur、oc、at、ta、sa、sm、pw、yw、hw和p5组合在一起构成的数据集d3,数据集d3包括训练集和验证集。
22、进一步地,所述步骤s4包括:
23、步骤s41:分别构建3个随机森林子模型hi(x),每个hi(x)中的决策树选取k=log2|di|个属性进行训练,其中,di包括数据集d1、数据集d2和数据集d3,|di|代表di中的属性总数,采用基于基尼系数最小化准则选择最好的特征进行树的分裂;
24、步骤s42:分别使用步骤s32中的数据集d1、步骤s33中的数据集d2和步骤s34中的数据集d3中的训练集对hi(x)进行训练,每个hi(x)以对应的fnr值作为目标函数值,通过di中验证集对于每个hi(x)中的决策树的棵树进行优化,找出fnr最小的情况下的每个hi(x)中的决策树的棵树,其中h1(x)中决策树的棵树的初始范围为5-100,h2(x)中决策树的棵树的初始范围为5-400,h3(x)中决策树的棵树的初始范围为5-100,得到最优子模型其中包括
25、进一步的,所述步骤s5包括:
26、步骤s51:设置融合约束器其中t0为约束值,令t0=1,分别用步骤s32中的数据集d1、步骤s33中的数据集d2和步骤s34中的数据集d3的验证集与步骤s42得到的最优子模型以及融合约束器h(x),计算出集成模型的tpr值,其中tpr表示真阳率(true positive rate),也叫敏感度,表示检测出来的异常样本数占所有异常样本的百分比;
27、步骤s52:通过步骤s51中的tpr值,根据二项分布模型计算t值,得出告警阈值t,即当该用户的告警次数累计超过阈值t后,才会发出告警,确认用户存在数据窃取行为。
28、进一步的,所述步骤s6包括:
29、步骤s61:从数据库中获取新产生的日志和人力资源表单,并从数据库中新产生的日志中提取sql语句,将sql语句中的操作符标记为oc,访问的表的特征标记为at,访问表的属性特征标记为aa,标记fi表示表i是否被访问,标记mi表示表i中被访问的属性总数;则at={f1,f2,…,fn},aa={m1,m2,…,mn};
30、步骤s62:从步骤s61数据库中获取的新产生的日志中,提取用户角色标记为ur,访问时间标记为ta,访问地理位置标记为sa,并将ur和sa采用标签编码的方式进行处理,将ta采用只取整点时间的方式进行处理;
31、步骤s63:从步骤s61数据库中获取的新产生的日志中提取查询结果,将查询结果的条数标记为rn,查询结果包含的属性数标记为ra,查询结果的大小标记为rs,查询结果的分布特征rt,rt代表查询结果从每个表中获取数据占该表的比例,标记pi表示查询结果中从表i中获取的条数占该表总条数的比值,则rt={p1,p2,…,pn};
32、步骤s64:从步骤s61获取的人力资源表单中提取每条访问对应的内部人员的月工资标记为sm,内部人员的工作绩效标记为pw,内部人员的工作年限标记为yw,内部人员的月工作时长标记为hw,内部人员在五年内是否晋升标记为p5,并将sm和hw采用w分之一位数,w分之二位数,…,w分之w-1位数,划分为w个等级进行其数据处理。
33、进一步地,所述步骤s7包括:
34、步骤s71:将步骤s6预处理后的访问与用户数据集拆分;
35、步骤s72:将步骤s71拆分后的访问与用户数据集构建查询语法数据集,查询语法数据集是通过将ur,oc,at和aa组合在一起构成的数据集d1′;
36、步骤s73:将步骤s71拆分后的访问与用户数据集构建查询结果数据集,查询结果数据集是通过将ur,oc,at,rn,ra,rs,和rt组合在一起构成的数据集d′2;
37、步骤s74:将步骤s71拆分后的访问与用户数据集构建内部人员信息数据集,内部人员信息数据集是通过将ur,oc,at,ta,sa,sm,pw,yw,hw和p5组合在一起构成的数据集d′3;
38、进一步地,所述步骤s8包括:
39、步骤s81:分别使用步骤s72中的数据集d1′、步骤s73中的数据集d′2和步骤s74中的数据集d′3放入步骤s42优化好的最优子模型中进行检测,分别得到各个子模型的检测结果;
40、步骤s82:将步骤s81得到的各个子模型检测结果输入步骤s51设置的融合约束器h(x)得到最终的检测结果;
41、步骤s83:如果步骤s82得到的检测结果为“异常”,则检测该条访问的内部人员的告警次数是否超过步骤s52中计算出来的t值,如果超过,则模型发出告警,判定该用户存在数据窃取行为。
42、本发明还提供了一种基于集成学习的数据库内部人员攻击检测系统,包括:
43、数据预处理模块:用于获取数据库中的日志和人力资源表单,从日志中获取查询过程中的sql语句、查询的角色信息、时间信息、空间信息以及查询结果,并获取操作用户的用户画像数据,分别对获取的数据进行预处理,得到预处理后的访问与用户数据集;
44、数据集划分模块:用于将预处理后的访问与用户数据集,划分为训练集和验证集;
45、数据集重构模块:用于实现基于划分好的训练集和验证集,将每个数据集都进行拆分重新组合,构建查询语法数据集、查询结果数据集以及内部人员信息数据集的训练集和验证集;
46、子模型优化模块:用于使用训练集分别训练各自的子模型,通过验证集优化训练后的各自的子模型,得到最优子模型;
47、告警阈值计算及告警模块:用于通过融合约束器对优化后的三个子模型进行融合,构成训练好的集成模型,并通过验证集和最优子模型,计算出一个告警阈值,当该用户的告警次数超过阈值后,发出告警,确认用户存在数据窃取行为;
48、新数据预处理模块:用于从数据库中获取新产生的日志和人力资源表单,并从新产生的日志中获取查询过程中的sql语句、查询的角色信息、时间信息、空间信息以及查询结果,并获取操作用户的用户画像数据,分别对获取的新的数据进行预处理,得到预处理后的访问与用户数据集;
49、新数据集划分模块:用于将预处理后的访问与用户数据集进行拆分重新组合,构建查询语法数据集、查询结果数据集以及内部人员信息数据集;
50、检测与告警模块:用于将构建的查询语法数据集、查询结果数据集以及内部人员信息数据集输入优化好的最优子模型,并将子模型的结果输入训练好的集成模型中,并通过集成模型的告警模块输出最终结果,判别每个访问数据库的用户是否存在数据窃取行为。
51、本发明还提供了一种基于集成学习的数据库内部人员攻击检测设备,包括:
52、存储器:存储上述一种基于集成学习的数据库内部人员攻击检测方法的计算机程序,为计算机可读取的设备;
53、处理器:用于执行所述计算机程序时实现所述的一种基于集成学习的数据库内部人员攻击检测方法。
54、本发明还提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时能够实现所述的一种基于集成学习的数据库内部人员攻击检测方法。
55、与现有技术相比,本发明的有益效果是:
56、1、本发明通过提取人力资源表单中的操作用户的用户画像信息,弥补语法信息和语义信息对数据窃取行为和动机上的构建缺失的问题,极大程度的提高了对于数据库内部人员攻击的检测能力。
57、2、本发明通过按特征对数据进行拆分重组,能够提高模型的性能,更精准的分析数据特征的模式。
58、3、本发明通过预设调优范围,枚举子模型规模大小并以fnr值作为目标值进行调优,更精准确定最优模型,较大程度地避免了模型陷入局部最优。
59、4、本发明通过构建融合约束器,能够提高模型的泛化能力并降低模型的漏检率。
60、5、本发明通过建立告警模块与计算告警阈值,能够降低模型的误检率。
61、综上所述,本发明通过对用户自身信息的提取,弥补语法信息和语义信息对数据窃取行为和动机上的构建缺失的问题,极大程度的提高了对于数据库内部人员攻击的检测能力;并且通过对不同的特征进行拆分重组,分别训练和通过预设调优范围,枚举子模型规模大小并以fnr值作为目标值进行调优,更精准确定最优模型,较大程度地避免了模型陷入局部最优;然后通过融合约束器将模型融合,提高了模型的泛化能力,并通过告警模块利用设置告警阈值的方法,进一步优化模型,据此得到的检测结果,降低了误检率和漏检率,提高了检测精度,有效的改善了模型的综合性能。
- 还没有人留言评论。精彩留言会获得点赞!