基于深度聚类和动态路由的TSK模糊系统分类方法及系统
本发明属于模糊系统分类,尤其涉及一种基于深度聚类和动态路由的tsk模糊系统分类方法及系统。
背景技术:
1、模糊系统有两种重要且流行的类型:mamdani模糊系统和tsk模糊系统。由takagi、sugeno和kang提出的tsk模糊系统是其中最常见的模糊模型之一。该模型已经被广泛运用于非线性系统建模与辨识、模式识别、图像处理等多个领域。区别于mamdani模糊系统,tsk模糊系统中每个模糊规则的结果是输入的函数。tsk模糊系统作为一种基于规则的模糊系统,既可以利用误差等数据信息,也可以利用专家的经验知识,这为在预测系统中设计合适的修正子系统提供了灵活性。在解决分类和回归等常见机器学习问题时,tsk模糊系统都能具有较好的非线性逼近能力。
2、然而,随着数据数量和维数的不断增长,tsk模糊系统也面临新的挑战。在面对大规模数据或高维数据时,tsk模糊系统容易产生规则爆炸等问题,导致模型难以优化到令人满意的分类准确率。为此,已有大量研究聚焦于优化tsk模糊系统。通常来说,tsk模糊系统的优化主要集中在规则结构的辨识和规则参数的优化两个方面。对于规则结构的辨识,使用不同聚类算法对输入空间进行划分,可以有效捕捉输入数据的分布特性。规则参数的优化方法主要包括进化算法、梯度下降和最小二乘等。其中,梯度下降方法和进化算法通常需要大量时间来确定候选解或更新模型参数。而最小二乘方法的泛化能力有限,通常无法满足复杂的机器学习任务。此外,现有的传统优化方法无法有效捕捉tsk模糊系统的输入空间和输出空间之间的内在联系,因此模糊系统的分类准确率不是最优的。
3、已经开发了一些新的技术来解决tsk模糊系统在大规模数据或高维数据上的优化问题。伍冬睿等人尝试将深度学习中的优秀技术引入到tsk模糊系统以优化模型在不同任务上的分类准确率表现。作者利用mbgd、dropout、normalization正则化等技术优化tsk模糊系统的前件和后件参数,显著提升了tsk模糊系统泛化能力,缓解了模糊系统存在的规则爆炸、泛化能力不足等问题。冯霜等人在tsk模糊系统的基础上,结合宽度学习系统开发了模糊宽度学习系统,以进一步改善模糊模型的性能。该方法将多个模糊子系统的输出聚合,并通过增强层来提升系统的非线性逼近能力。
4、通过上述分析,现有技术存在的问题及缺陷为:现有的利用深度学习技术优化tsk模糊系统的方案通常依靠梯度下降来同时调整tsk模糊系统的不同参数,因此显著增加了模型的训练时间。另一方面,利用横向扩展和快速可重构技术优化tsk模糊系统的方案使得模型的结构变得冗余,模型的分类准确率受到显著影响。
5、现有技术:传统的tsk模糊系统
6、这种系统通常基于经典的模糊逻辑,利用简单的规则集来处理不确定性和模糊性。它们依赖于专家知识来定义规则和隶属度函数。这些系统的参数调整通常是基于试错方法或者简单的优化算法。
7、技术问题:
8、1.)有限的数据处理能力:传统tsk模糊系统在处理大规模或高维度数据时效率较低。它们无法有效处理复杂的数据模式,尤其是在大数据应用场景下。
9、2.)缺乏自适应和自学习能力:这些系统依赖于预先设定的规则,缺乏深度学习系统的自适应和自学习能力。因此,在数据特性发生变化时,它们的性能下降。
10、3.)参数调整效率低:传统方法在参数调整上依赖较为原始的方法,如手动调整或简单的算法,这限制了其在复杂环境下的应用,尤其是需要实时调整参数的情况。
11、4.)泛化能力有限:由于缺乏复杂数据处理能力和自适应学习机制,传统tsk模糊系统的泛化能力有限,难以适应多变的工业环境。
技术实现思路
1、针对现有技术存在的问题,本发明提供了一种基于深度聚类和动态路由的tsk模糊系统分类方法及系统。
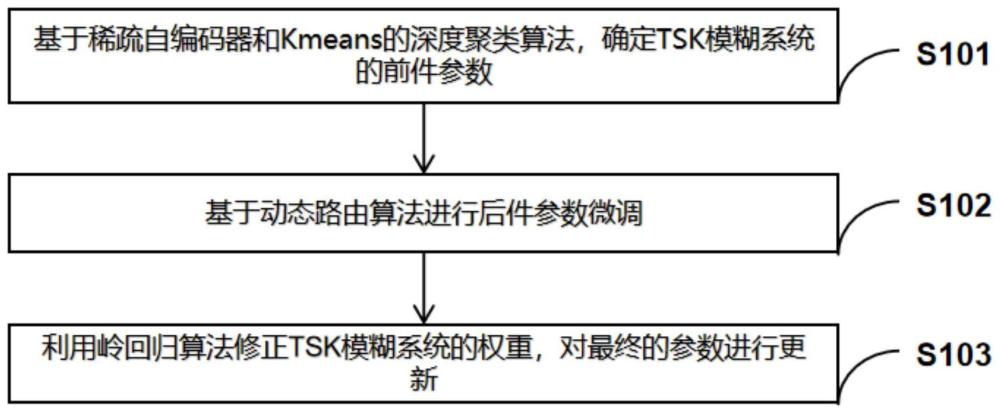
2、本发明是这样实现的,一种基于深度聚类和动态路由的tsk模糊系统分类方法,包括以下步骤:
3、步骤一,基于稀疏自编码器和kmeans的深度聚类算法,确定tsk模糊系统的前件参数;
4、步骤二,基于动态路由算法进行后件参数微调;
5、步骤三,利用岭回归算法修正tsk模糊系统的权重,对最终的参数进行更新。
6、进一步,假设tsk模糊分类器有r个规则,表示为:
7、if x1 is xr,1 and…and xd is xr,d,
8、
9、式中xr,d(r=1,...,r;d=1,...,d)是第r个规则中第d个前件的隶属度函数,和是第c类对应的后件参数;
10、tsk模糊分类器的高斯隶属度函数表示为:
11、
12、式中mr,d和σr,d分别是高斯隶属度函数的中心和标准偏差;
13、第c类对应的tsk模糊分类器的输出表示为:
14、
15、式中是规则r的激活水平;
16、分类器输出进一步为:
17、
18、式中是规则r的归一化激活水平。
19、进一步,给定训练样本为其中xn=[xn,1,...,xn,d]t∈rd×1是一个d维的特征向量,yn∈{1,2,...,c}对应分类问题中的类别标签。
20、进一步,步骤一中将原始样本输入稀疏自编码器,提取低维特征;将新的特征表示用于kmeans聚类,获取前件参数的聚类中心。
21、进一步,稀疏自编码器的优化目标表示为:
22、
23、式中,是稀疏自编码器中需要求解的权重矩阵,z=xw表示输入样本x的期望输出;
24、使用admm算法进行求解,经过求解的低维特征通过下式表示:
25、
26、稀疏自编码器的输出被输入到kmeans算法中进行聚类;聚类目标函数表示为:
27、
28、进一步,步骤二中将模糊规则中的改写为:
29、
30、使用稀疏自编码器调整输入的维数,同时提取有效信息;将经过特征提取的标量重塑为胶囊,并以胶囊为基本单位进行参数微调。
31、进一步,经过特征提取的动态路由输入表示为b=[b1,b2,...,be];将b表示为p个输入胶囊ui(i=1,...,p),每个胶囊的维数为h;输出胶囊vj的数量为q(j=1,...,q),维数为l(l=1,...,l);随机生成权重矩阵wij,对输入胶囊进行变换;执行动态路由算法,协调输入胶囊和输出胶囊之间的关系;经过协议路由的多次迭代,最终确定输出胶囊vj。
32、进一步,第r个模糊规则对应的表示为新的后件参数与输出胶囊的组合:
33、
34、对于r个模糊规则的第c类输出表示为:
35、
36、进一步,步骤三中使用岭回归算法对最终的参数进行更新;将整个tsk分类器的c类输出表示为如下形式:
37、
38、式中,δrc表示tsk分类器的输出参数;
39、对于n个输入样本,输出f表示为:
40、
41、式中,并且
42、
43、使用岭回归算法对权重矩阵θ进行求解,可以使用下式表示:
44、
45、式中
46、
47、本发明的另一目的在于提供一种基于深度聚类和动态路由的tsk模糊系统分类方法的基于深度聚类和动态路由的tsk模糊系统分类系统,该系统包括:
48、数据处理单元:配置有稀疏自编码器用于从输入数据中提取低维度特征;配置有kmeans聚类算法模块,用于对稀疏自编码器输出的特征进行聚类处理;
49、设有参数确定模块,用于根据聚类结果确定tsk模糊系统的前件参数;
50、参数调整模块:配置有动态路由算法模块,用于对tsk模糊系统的后件参数进行微调;该模块通过迭代优化过程调整模糊规则的后果部分参数;
51、权重修正与更新单元:配置有岭回归算法模块,用于对tsk模糊系统的权重进行修正;通过岭回归算法的正则化处理,优化模型的泛化能力,并进行最终的模型参数更新。
52、作为本发明的优化方案,基于深度聚类和动态路由的tsk模糊系统分类方法旨在通过结合高级数据处理和优化算法来提高分类准确性和效率。
53、步骤一:确定tsk模糊系统的前件参数
54、原方案:使用稀疏自编码器和kmeans聚类算法。
55、替代方案1:使用主成分分析(pca)和dbscan聚类算法。pca用于降低数据维度并突出主要特征,而dbscan能够处理不同密度的数据集,对噪声和异常值更为鲁棒。
56、技术进步:提高了对复杂数据集的处理能力,特别是在存在噪声和不规则分布时。
57、替代方案2:使用自动编码器和光谱聚类算法。自动编码器能够学习更复杂的非线性特征表示,而光谱聚类可以更好地处理具有复杂几何结构的数据。
58、技术进步:能够提取更丰富的特征并处理具有复杂内部结构的数据集。
59、步骤二:进行后件参数微调
60、原方案:基于动态路由算法。
61、替代方案1:使用遗传算法。这种算法通过模拟自然选择和遗传学原理来搜索最优解。
62、技术进步:提供了一种全局搜索策略,有助于避免局部最优解,提高整体系统的性能。
63、替代方案2:采用粒子群优化算法。粒子群优化是一种基于群体协作的优化技术,适合于连续空间的搜索。
64、技术进步:提高了参数搜索的效率,特别是在连续参数空间中。
65、步骤三:利用岭回归算法修正权重
66、原方案:应用岭回归算法。
67、替代方案1:使用lasso(least absolute shrinkage and selection operator)回归。lasso能够进行变量选择并提供稀疏解。
68、技术进步:提高模型的解释性,通过消除不重要的特征来减少模型的复杂度。
69、替代方案2:应用弹性网回归,结合了岭回归和lasso回归的特点。
70、技术进步:在保持模型复杂性和稀疏性平衡的同时,提高模型的稳定性和准确性。
71、本发明提供的替代方案不仅提供了不同的视角和方法来处理分类问题,而且它们还能带来特定的技术进步,如改善对噪声和异常值的处理、提高全局搜索能力、提升参数优化的效率,以及增强模型的解释性和稳定性。
72、结合上述的技术方案和解决的技术问题,本发明所要保护的技术方案所具备的优点及积极效果为:
73、第一,本发明聚焦于利用深度学习技术对tsk模糊系统的规则结构和规则参数进行分步优化,以兼顾模型在大规模高维数据分类任务中的分类准确性和高效性。
74、本发明通过多种高效的深度学习特征提取技术来充分捕捉数据的有效特征,在提升模糊分类器分类精度的同时显著降低训练时间。
75、本发明提出一种基于稀疏自编码器和kmeans算法的深度聚类方法,用于确定tsk模糊系统的前件参数。其中稀疏自编码器用于获取原始大规模高维数据的有效特征表示,kmeans算法用于对新的特征表示进行聚类和空间划分。
76、本发明提出一种基于动态路由算法的后件参数微调方法。通过动态路由算法捕捉输入空间和输出空间之间的关系,以提升模型的性能。
77、本发明应用岭回归算法更新tsk模糊系统的权重,以进一步提升tsk模糊分类器的泛化能力和训练时间。
78、本发明所提出的ddtsk模糊分类器可以有效捕捉输入数据的特征表示,同时可以建立输入空间和输出空间的关联,还可以通过正则化参数更新方法来以进一步提升发明的分类性能。本发明的方法结构清晰,易于理解和部署,计算简便,可以有效解决分类模型的性能不足和效率低的问题。
79、第二,相比现有技术,本发明提供的基于深度聚类和动态路由的tsk模糊系统通过集成先进的深度学习技术和优化算法,能够更有效地处理高维度数据,提高模型的自适应和自学习能力,优化参数调整过程,并增强模型的泛化能力。这些改进使得该系统更适合应对复杂多变的工业应用场景。
80、在国内外已有的基于tsk模糊系统的分类技术方案中,较少有利用深度学习技术来优化tsk模糊系统的技术方案。此外,已有的极少部分深度学习与tsk模糊系统结合的技术方案的效果和效率不足,难以满足真实分类问题的需求。本发明提供的技术方案利用深度学习技术来优化tsk模糊系统,并有效运用于分类问题,是一种将深度学习与tsk模糊系统结合应用的成功案例。
81、第三,本发明提供的基于深度聚类和动态路由的tsk模糊系统分类方法,以下是取得的显著的技术进步:
82、1.)增强的数据处理能力:
83、本发明利用稀疏自编码器和kmeans聚类算法处理数据。替代方案通过采用pca与dbscan或自动编码器与光谱聚类,提供了对数据更深层次、更复杂结构的处理能力。特别是在噪声较多或数据分布不均匀的情况下,这种增强的数据处理能力能够提高前件参数确定的准确性和鲁棒性。
84、2.)优化的参数调整机制:
85、本发明动态路由算法用于后件参数微调。替代方案中,遗传算法和粒子群优化算法引入了全局搜索机制,这有助于避免陷入局部最优解,从而在整个参数空间中找到更优的解决方案。这种全局优化方法对于复杂的模糊系统特别重要,因为它们通常有多个参数和高度非线性的性质。
86、3.)改进的权重调整方法:
87、本发明采用岭回归算法对tsk模糊系统的权重进行修正是一种有效的正则化技术。替代方案中的lasso回归和弹性网回归算法不仅提供了正则化的优势,还通过引入变量选择机制,提高了模型的解释性和稀疏性。这种改进有助于构建更简洁、更易于理解和维护的模型,同时保持或提升预测性能。
88、4.)提高了模型的适应性和灵活性:
89、本发明根据不同的应用场景和数据特性灵活选择最适合的方法。这种灵活性对于应对实际应用中的多样性和复杂性至关重要,可以显著提升模型在不同条件下的性能和可靠性。
90、本发明提供的技术进步显著提升了分类模型在数据处理能力、参数优化效率、模型简洁性和适应性方面的性能,使其更加适合于处理复杂且多变的实际数据。
- 还没有人留言评论。精彩留言会获得点赞!