文本处理方法、装置及存储介质与流程
本技术涉及计算机,尤其涉及一种文本处理方法、装置及存储介质。
背景技术:
1、保持语义的文本风格改写任务,是指在文本内容和意思保持不变的情况下,改变文本的文本风格,例如将文本风格从正式变为随意,或者从消极变为积极等。对于这种任务,目前常用的方式是使用基于有监督微调训练的网络模型对文本进行风格改写。
2、但是,基于有监督微调训练的网络模型的文本改写能力会受到固有训练数据的限制,并且,对一个文本进行风格改写,可能会有多种符合要求的“好答案”,但基于有监督微调训练的网络模型一般都是以单一的样本标签作为“参考答案”来进行训练的,因此训练后的网络模型难以学习到相对好坏的信息,从而可能会表现不够鲁棒。
技术实现思路
1、以下是对本文详细描述的主题的概述。本概述并非是为了限制权利要求的保护范围。
2、本技术实施例提供了一种文本处理方法、装置及存储介质,不仅能够使模型的文本改写能力突破固有训练数据的限制,还能够使模型以更优的目标进行迭代训练以学习相对好坏的消息,从而能够提高模型的文本改写效果以及鲁棒性。
3、一方面,本技术实施例提供了一种文本处理方法,包括以下步骤:
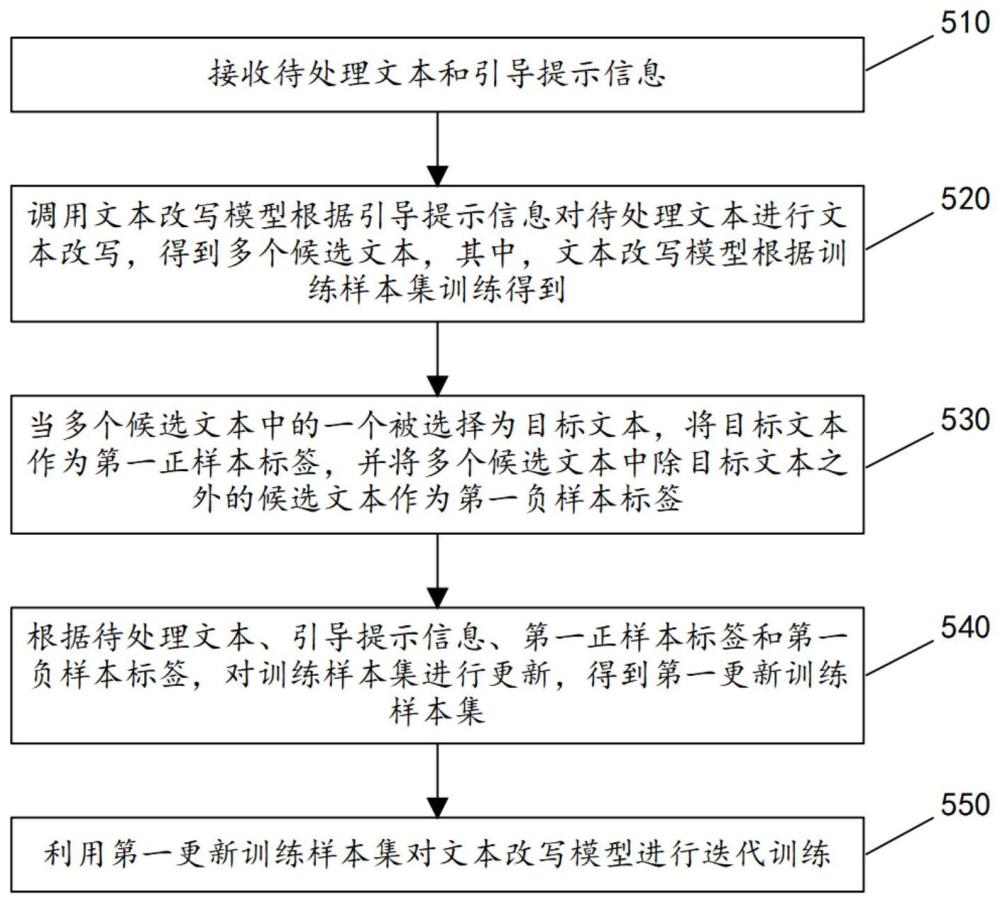
4、接收待处理文本和引导提示信息;
5、调用文本改写模型根据所述引导提示信息对所述待处理文本进行文本改写,得到多个候选文本,其中,所述文本改写模型根据训练样本集训练得到;
6、当多个所述候选文本中的一个被选择为目标文本,将所述目标文本作为第一正样本标签,并将多个所述候选文本中除所述目标文本之外的候选文本作为第一负样本标签;
7、根据所述待处理文本、所述引导提示信息、所述第一正样本标签和所述第一负样本标签,对所述训练样本集进行更新,得到第一更新训练样本集;
8、利用所述第一更新训练样本集对所述文本改写模型进行迭代训练。
9、另一方面,本技术实施例还提供了一种文本处理装置,包括:
10、文本获取单元,用于接收待处理文本和引导提示信息;
11、第一文本改写单元,用于调用文本改写模型根据所述引导提示信息对所述待处理文本进行文本改写,得到多个候选文本,其中,所述文本改写模型根据训练样本集训练得到;
12、第一标签确定单元,用于当多个所述候选文本中的一个被选择为目标文本,将所述目标文本作为第一正样本标签,并将多个所述候选文本中除所述目标文本之外的候选文本作为第一负样本标签;
13、第一样本更新单元,用于根据所述待处理文本、所述引导提示信息、所述第一正样本标签和所述第一负样本标签,对所述训练样本集进行更新,得到第一更新训练样本集;
14、第一模型训练单元,用于利用所述第一更新训练样本集对所述文本改写模型进行迭代训练。
15、可选地,所述文本处理装置还包括:
16、第二标签确定单元,用于当多个所述候选文本中的一个被选择后进行了编辑,将编辑后的文本作为第二正样本标签,并将多个所述候选文本作为第二负样本标签;
17、第二样本更新单元,用于根据所述待处理文本、所述引导提示信息、所述第二正样本标签和所述第二负样本标签,对所述训练样本集进行更新,得到第二更新训练样本集;
18、第二模型训练单元,用于利用所述第二更新训练样本集对所述文本改写模型进行迭代训练。
19、可选地,所述训练样本集包括训练样本、引导提示样本、正训练样本标签和负训练样本标签;所述文本处理装置还包括:
20、第二文本改写单元,用于调用所述文本改写模型根据所述引导提示样本对所述训练样本进行文本改写,得到多个文本改写结果;
21、模型参数更新单元,用于根据所述正训练样本标签、所述负训练样本标签和多个所述文本改写结果,对所述文本改写模型的模型参数进行更新;
22、第三样本更新单元,用于根据多个所述文本改写结果对所述训练样本集进行更新,得到第三更新训练样本集;
23、第三模型训练单元,用于利用所述第三更新训练样本集对所述模型参数更新后的所述文本改写模型进行迭代训练。
24、可选地,所述第三样本更新单元还用于:
25、在多个所述文本改写结果中确定目标改写文本;
26、根据所述目标改写文本对所述正训练样本标签进行更新,并将多个所述文本改写结果中除所述目标改写文本之外的文本改写结果添加到所述负训练样本标签中,得到第三更新训练样本集。
27、可选地,所述第三样本更新单元还用于:
28、将所述训练样本和每个所述文本改写结果分别构建待评分文本组;
29、调用改写质量评分模型对每个所述待评分文本组分别进行改写质量评分,得到每个所述文本改写结果的第一改写质量分数;
30、将所述第一改写质量分数最高的所述文本改写结果确定为目标改写文本。
31、可选地,所述第三样本更新单元还用于:
32、根据预设规则对每个所述文本改写结果分别进行改写质量评分,得到每个所述文本改写结果的第二改写质量分数;
33、将所述第二改写质量分数最高的所述文本改写结果确定为目标改写文本。
34、可选地,所述第三样本更新单元还用于:
35、将所述训练样本和每个所述文本改写结果分别构建待评分文本组;
36、调用改写质量评分模型对每个所述待评分文本组分别进行改写质量评分,得到每个所述文本改写结果的第一改写质量分数;
37、根据预设规则对每个所述文本改写结果分别进行改写质量评分,得到每个所述文本改写结果的第二改写质量分数;
38、根据所述第一改写质量分数和所述第二改写质量分数,在多个所述文本改写结果中确定目标改写文本。
39、可选地,所述第三样本更新单元还用于:
40、将每个所述文本改写结果的所述第一改写质量分数和所述第二改写质量分数进行累加或者加权累加,得到每个所述文本改写结果的第一改写质量综合分数;
41、将所述第一改写质量综合分数最高的所述文本改写结果确定为目标改写文本。
42、可选地,所述第三样本更新单元还用于:
43、将所述训练样本和每个所述文本改写结果分别构建待评分文本组;
44、在多个所述待评分文本组中进行多次随机抽样,得到多组抽样结果,其中,每组所述抽样结果均包括多个所述待评分文本组;
45、调用改写质量评分模型对每组所述抽样结果中的每个所述待评分文本组分别进行改写质量评分,得到每组所述抽样结果中的每个所述文本改写结果的第三改写质量分数;
46、对于每个所述文本改写结果,将在不同组的所述抽样结果中的所述第三改写质量分数进行加权平均,得到每个所述文本改写结果的第二改写质量综合分数;
47、将所述第二改写质量综合分数最高的所述文本改写结果确定为目标改写文本。
48、可选地,所述文本处理装置还包括:
49、第一样本获取单元,用于获取多个金标样本组,其中,所述金标样本组包括训练样本、引导提示样本和正训练样本标签,所述正训练样本标签根据所述引导提示样本对所述训练样本进行文本改写得到;
50、第一样本确定单元,用于遍历选择每个所述金标样本组,对于当前选择的所述金标样本组,在其他的所述金标样本组中确定所述训练样本相同的候选金标样本组;
51、第一样本处理单元,用于将所述候选金标样本组中的所述正训练样本标签作为负训练样本标签,添加到当前选择的所述金标样本组中,得到当前选择的所述金标样本组所对应的训练样本组;
52、第一样本构建单元,用于根据遍历选择所有所述金标样本组之后得到的所有所述训练样本组,构建得到所述训练样本集。
53、可选地,所述文本处理装置还包括:
54、第二样本获取单元,用于获取多个金标样本组,其中,所述金标样本组包括训练样本、引导提示样本和正训练样本标签,所述正训练样本标签根据所述引导提示样本对所述训练样本进行文本改写得到;
55、第二样本处理单元,用于对于每个所述金标样本组,根据与所述引导提示样本不同的引导提示信息对所述训练样本进行文本改写,得到改写后文本,将所述改写后文本作为负训练样本标签添加到所述金标样本组中,得到每个所述金标样本组对应的训练样本组;
56、第二样本构建单元,用于根据所有所述金标样本组对应的所述训练样本组,构建得到所述训练样本集。
57、另一方面,本技术实施例还提供了一种电子设备,包括:
58、至少一个处理器;
59、至少一个存储器,用于存储至少一个程序;
60、当至少一个所述程序被至少一个所述处理器执行时实现如前面所述的文本处理方法。
61、另一方面,本技术实施例还提供了一种计算机可读存储介质,其中存储有处理器可执行的计算机程序,所述处理器可执行的计算机程序被处理器执行时用于实现如前面所述的文本处理方法。
62、另一方面,本技术实施例还提供了一种计算机程序产品,包括计算机程序或计算机指令,所述计算机程序或所述计算机指令存储在计算机可读存储介质中,电子设备的处理器从所述计算机可读存储介质读取所述计算机程序或所述计算机指令,所述处理器执行所述计算机程序或所述计算机指令,使得所述电子设备执行如前面所述的文本处理方法。
63、本技术实施例至少包括以下有益效果:在获取到待处理文本和引导提示信息之后,调用文本改写模型根据引导提示信息对待处理文本进行文本改写,得到多个候选文本,当多个候选文本中的一个被选择为目标文本,将目标文本作为第一正样本标签,并将多个候选文本中除目标文本之外的候选文本作为第一负样本标签,然后根据待处理文本、引导提示信息、第一正样本标签和第一负样本标签,对训练样本集进行更新,得到第一更新训练样本集,接着利用第一更新训练样本集对文本改写模型进行迭代训练。由于在文本改写模型输出多个候选文本之后,能够将被选择的候选文本作为第一正样本标签,并将剩余的候选文本作为第一负样本标签,对训练样本集进行更新并利用更新后的训练样本集对文本改写模型进行迭代训练,因此可以在使用文本改写模型进行文本改写的过程中,不断丰富训练样本集的内容并将内容丰富后的训练样本集继续对文本改写模型进行迭代训练,从而可以进一步增强文本改写模型的文本改写能力,使得文本改写模型的文本改写能力能够突破固有训练数据的限制,实现优化闭环;另外,由于会在文本改写模型所输出的多个候选文本中选择一个作为第一正样本标签,因此在文本改写模型每次输出多个候选文本时,都可以选择得到不同的第一正样本标签,使得文本改写模型不再以单一的样本标签作为“参考答案”来进行训练,因此可以使得文本改写模型能够以更优的目标进行迭代训练以学习相对好坏的消息,从而能够提高文本改写模型的文本改写效果以及鲁棒性。
64、本技术的其它特征和优点将在随后的说明书中阐述,并且,部分地从说明书中变得显而易见,或者通过实施本技术而了解。本技术的目的和其他优点可通过在说明书以及附图中所特别指出的结构来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!