一种基于对象存储的文件系统的遍历性能优化方法与流程
本发明涉及计算机信息处理,具体为一种基于对象存储的文件系统的遍历性能优化方法。
背景技术:
1、随着物联网、大数据、云计算、5g等技术的不断发展,互联网、政企、医疗各行各业的业务日新月异,带来了海量数据的爆发性增长,对传统存储系统提出了诸多挑战。相比于传统的文件存储,对象存储通过扁平化的kv存储大大简化了元数据管理的复杂度。对象存储正在云计算存储服务领域占据着越来越重要的地位,随着对象存储在海量数据场景下的优势日益显现,用户希望像使用文件系统一样使用对象存储的需求也与日俱增,而开源软件s3fs刚好开源满足这一需求。在单桶海量数据场景下,当客户通过s3fs以文件系统接口使用对象存储的时候,经常遇到打开文件夹时延较高的现象,根本原因在于s3fs调用对象存储的listobjects api时延较高,严重影响了客户业务。以下是检索到的现有技术以及存在的问题:
2、现有技术(公布号:cn 114528260a)中公开了文件访问请求的处理方法、电子设备及计算机程序产品,该专利基于s3fs将对象存储导出为文件系统,通过将部分元数据缓存到本地内存和磁盘来降低与云端的交互,但是并没有提出解决遍历云端元数据时延高的方案;
3、现有技术(公告号:cn 101526948 b)中公开了多线程文件遍历技术,该专利通过多线程充分利用cpu资源来提升文件系统的遍历性能,但提出的方法并没有通过算法优化提升每个计算任务的性能,而且使用场景是传统的文件系统。
4、为此,我们提出一种基于对象存储的文件系统的遍历性能优化方法,用以解决上述技术问题。
技术实现思路
1、(一)解决的技术问题
2、针对现有技术的不足,本发明提供了一种基于对象存储的文件系统的遍历性能优化方法,具备提升遍历效率,降低整体时延的同时也节约了算力和io资源等优点,解决了现有技术调用对象存储的listobjectsapi时延较高,严重影响了客户业务的问题。
3、(二)技术方案
4、为实现上述具备提升遍历效率,降低整体时延的同时也节约了算力和io资源目的,本发明提供如下技术方案:一种基于对象存储的文件系统的遍历性能优化方法,包括以下步骤:
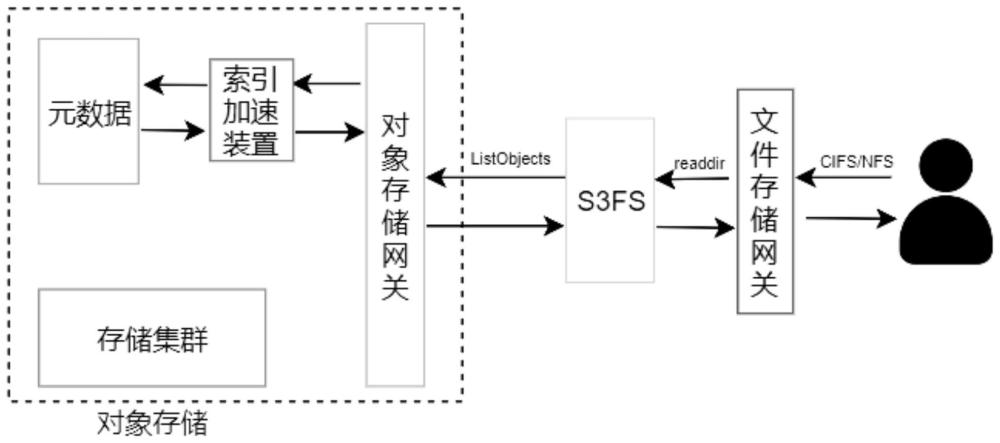
5、步骤一、用户打开一个文件夹并发送打开请求;
6、步骤二、s3fs接口截获步骤一请求并转成对象存储能够处理的listobjects请求;
7、步骤三、将步骤二中的listobjects请求发送到对象存储网关;
8、步骤四、对象存储网关将请求通过索引加速模块进行处理;
9、步骤五、处理后的数据通过解析查询请求并查询元数据库来返回结果。
10、优选的,所述步骤四中索引加速模块包括优化遍历算法,其步骤如下:
11、a1、根据marker、prefix和max-keys参数在数据库中做range查询;
12、a2、逐条处理返回结果,相同公共前缀的结果只返回一条公共前缀,不包含公共前缀的,作为一个文件返回;
13、a3、判断文件数+目录数是否等于max-keys,是,则返回并进行后续程序,否,则进行a4步骤;
14、a4、当文件数+目录数不等于max-keys,判断当前数据集中最后一个元素是否是commonprefix,是,则进行a5步骤,否,则取最后一个key作为下一次查询的marker;
15、a5、当当前数据集中最后一个元素是commonprefix,将最后一个commonprefix的最后一个字符的ascii码加1后作为下一次查询的marker。
16、优选的,所述步骤四中索引加速模块还包括索引缓存方案,所述索引缓存方案包括元数据库遍历模块、索引缓存遍历模块、目录树深度统计模块、对象存储网关、元数据请求调度模块和索引缓存重建。
17、优选的,所述元数据库遍历模块和索引缓存遍历模块实现方式相同,且均用于解析listobjects请求、生成sql执行任务并下发到数据库,然后将返回结果封装后返回给调用方。
18、优选的,所述目录树深度统计模块用于定期统计目录树的深度,形成深度分布直方图,所述对象存储网关用于将涉及元数据的请求转发到元数据请求调度模块,包括对元数据库和索引缓存的增删操作以及遍历请求的转发。
19、优选的,所述元数据请求调度模块用于针对对象存储网关转发过来的请求进行调度,包括文件上传对应的元数据操作、文件删除对应的元数据操作和遍历请求的转发。
20、优选的,所述文件上传对应的元数据操作其步骤如下:
21、b1、文件上传;
22、b2、以文件名作为key通过覆盖写的方式在元数据库中插入一条记录;
23、b3、判断文件的目录深度是否大于indexcachedepth,是,则提取文件目录深度为indexcachedepth的部分,称之为filecachepath,通过覆盖写的方式将filecachepath插入到索引缓存,否,则进行b4步骤;
24、b4、当文件的目录深度小于indexcachedepth,则以文件名作为key通过覆盖写的方式在索引缓存中插入一条记录。
25、优选的,所述文件删除对应的元数据操作其步骤如下:
26、c1、文件删除;
27、c2、在元数据库中删除该文件对应的记录;
28、c3、判断文件的目录深度是否大于indexcachedepth,是,则进行c4步骤,否,则在索引缓存中删除该文件对应的记录;
29、c4、当文件的目录深度大于indexcachedepth,则提取文件目录深度为indexcachedepth的部分,称之为filecachepath;
30、c5、判断元数据库中是否存在前缀为filecachepath的对象,是,则返回上一步,否,则进行c6步骤;
31、c6、当元数据库中不存在前缀为filecachepath的对象,则在索引缓存中删除filecachepath对应的记录。
32、优选的,所述遍历请求的转发其步骤如下:
33、d1、遍历请求转发;
34、d2、判断prefix是否大于indexcachedepth,是,则查询查询元数据库,否,则查询索引缓存。
35、优选的,所述索引缓存重建用于用户的数据分布发生变化时,进行索引缓存的重建,根据新的indexcachedepth对元数据库中的对象名进行截断以覆盖写的方式插入索引缓存。
36、与现有技术相比,本发明提供了一种基于对象存储的文件系统的遍历性能优化方法,具备以下有益效果:
37、1、本发明针对单桶海量数据场景下,基于对象存储的文件系统遍历性能差的问题,通过索引缓存方案和遍历算法优化,显著提升了遍历效率,解决了对象存储在文件系统大规模应用面临的痛点,通过子查询偏移量marker最后一个ascii码加一的方式跳过了无效的数据,降低了子查询的调用次数,同时降低整体时延、节约了算力和io资源。
38、2、本发明通过分析文件系统的语义,提出了遍历(listobjects)性能优化算法,通过子查询偏移量marker最后一个ascii码加一的方式跳过了无效的数据,显著降低了子查询的调用次数,降低整体时延的同时也节约了算力和io资源。
39、3、本发明设计了索引缓存方案,提出了索引缓存的构建、维护策略,设计了元数据请求调度装置的调度逻辑,设计了目录树深度统计模块,作为维护索引缓存以及元数据请求调度的依据。
- 还没有人留言评论。精彩留言会获得点赞!