基于三支多属性决策模型与SAC的兵棋推演智能决策方法
本发明涉及计算机兵棋推演,具体地说,是一种基于三支多属性决策模型与sac的兵棋推演智能决策方法。
背景技术:
1、兵棋推演是基于实战化规则的作战模拟系统,用棋盘描述战场地形地貌,用棋子/算子及其动态变化描述作战实体和战斗事件,基于作战经验和时间对作战双方的对抗过程进行仿真推演。随着计算机和信息技术的不断发展,计算机兵棋推演现已成为现代战争模拟训练的有效手段之一,对研究信息化和智能化战争有重要意义。
2、在计算机兵棋推演研究体系中,研发高效的、可实现自主决策和行动的智能体(agent)一直以来是一项重要课题。近年来,alphago、libratus、openai five、alphastar、alphago zero等代表性棋类和游戏ai的成功研发推动了基于深度强化学习(deepreinforcement learning,drl)的兵棋智能体的研究进展。基于drl的智能体通过与环境进行交互,收集状态、动作和奖励数据进行训练,从而学习到面向特定任务的行动策略,具有很好的探索多样性和环境适应性。
3、现有基于drl的系列兵棋推演决策方法研究显示,基于actor-critic框架的兵棋推演单智能体和多智能体决策方法可提升agent行动策略的高效性和稳定性;基于改进ppo算法可提升多机协同空战场景下的学习效果;基于监督学习和ppo的智能决策算法,并结合额外奖励设置可使agent的收敛速度和胜率得到稳步提升;利用强化学习多智能体深度确定性策略梯度算法实现博弈动态决策;以impala为代表的分布式强化学习算法也常被用于智能兵棋训练。此外,基于drl和先验知识的混合驱动的智能体相关研究也取得进展,这类智能体通过在drl学习模型中引入先验知识实现更快收敛。例如融入先验知识的dqn算法的稳定性和收敛速度优于传统dqn算法,且可击败高级规则驱动的算子;将多属性决策(multiple attribute decision making,madm)方法获得的先验知识融入到ppo算法,使agent的综合博弈效果和胜率相比基于纯ppo和纯规则的agent得到提升。然而,面对要素众多、关系复杂、数据量庞杂的战场环境,模型采样率低、训练收敛困难、即时策略产出慢,以及智能体对抗特定规则时低胜率仍是现有兵棋推演智能决策算法的主要挑战。
4、现有技术1(cn 116036613 a)公开了一种实现兵棋推演智能决策的系统和方法,包括对任务想定模块、资源配置模块、导调控制模块、数据管理模块、推演引擎模块、智能对抗训练接口模块和智能训练与决策模块。该技术侧重兵棋推演智能决策系统中各任务模块的构建和对各模块中任务流程的描述。现有技术2(cn 113222106 a)公开了一种基于分布式强化学习的智能兵棋推演方法。该方法采用常规标签和图像数据表征战场态势和个体属性,基于actor-critic框架对每个算子建立决策神经网络获得决策结果。该技术侧重描述强化学习在智能兵棋推演中的训练过程。现有技术3(cn 114722998a)公开了一种基于cnn-ppo的兵棋推演智能体构建方法。该方法对兵棋推演平台的初始态势数据进行采集并预处理,获得目标态势数据,将该目标态势数据输入所构建的影响力地图模块获得影响力特征;基于卷积神经网络和近端策略优化构建混合神经网络模型,输入拼接后的目标态势数据和影响力特征进行迭代训练。现有技术4(cn 116596343 a)公开了一种基于深度强化学习的智能兵棋推演决策方法。该方法通过智能体状态空间、低优势策略-价值网络架构、作战场景判断模型和智能决策系统构建深度神经网络进行训练,得到基于深度强化学习的智能兵棋推演决策模型。现有技术3和4侧重于基于纯强化学习算法提升作战推演中智能体产生战术决策的效率,加快对抗策略网络训练过程的收敛速度,在算法改进和收敛速度方面还要还有加大提升空间。
技术实现思路
1、本发明的目的是提供一种基于三支多属性决策模型与sac的兵棋推演智能决策方法,旨在提高战术兵棋智能体的训练收敛速度和博弈获胜概率。
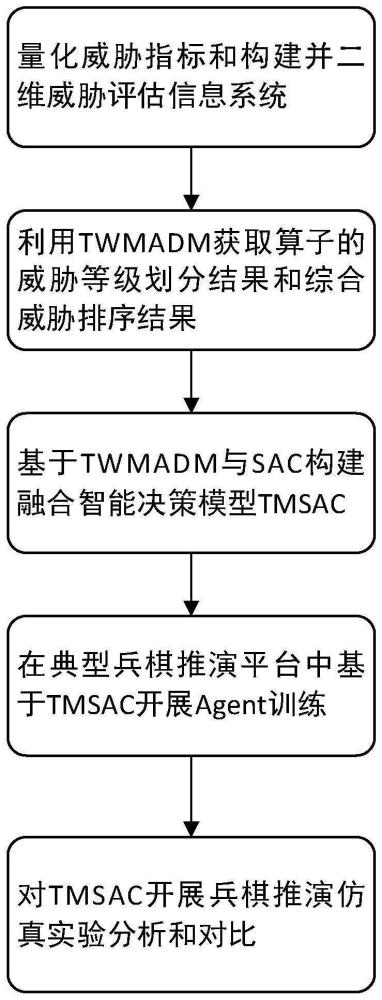
2、实现本发明目的的技术解决方案为:一种基于三支多属性决策模型与sac的兵棋推演智能决策方法,包括以下步骤:
3、步骤1:构建威胁指标量化模型,计算兵棋推演系统中对方算子在各项威胁指标上的威胁隶属度,并表征为二维威胁评估信息系统;
4、步骤2:基于威胁评估信息系统,用三支多属性决策模型tmadm获取对方算子的威胁评估结果,包括算子的威胁等级划分结果和综合威胁排序结果;
5、步骤3:在兵棋推演系统中构建twmadm与软表演者-批评家算法sac的智能融合决策模型tmsac;
6、步骤4:在兵棋推演系统中基于tmsac进行agent训练,训练完成后保存该兵棋推演智能决策模型;
7、进一步的,所述步骤1的具体实施步骤为:
8、步骤1.1:构建兵棋推演系统中对方坦克算子的威胁指标体系及其量化模型;
9、所述威胁指标体系包括距离、速度、角度、攻击能力、防御能力、地形通视、所处环境这7项威胁指标,其中,距离、速度、角度威胁指标的量化模型构建过程如下:
10、1)距离威胁指标量化模型如式(1)所示:
11、
12、其中,tdis代表对方算子的距离威胁指标量化值,和分别代表攻击距离值和夺控距离威胁值,r代表坦克算子的射程,l代表算子之间的距离,d和d′分别代表算子通过普通地形和特殊地形的损耗系数;
13、2)速度威胁指标量化模型如式(2)所示:
14、
15、其中,tvel代表对方算子的速度威胁指标量化值,ve和ve′分别代表对方算子和我方算子的行进速度,ve代表对方算子的准确射击速度阈值;
16、3)角度威胁指标量化模型如式(3)所示:
17、
18、其中,tang代表对方算子的角度威胁指标量化值,l″代表双方算子之间的水平距离,代表对方算子相对我方算子的高程差;
19、4)攻击能力威胁指标量化模型如式(4)所示:
20、tatt=[ln cap1+ln(∑cap2+1)+ln(∑cap3)]ρ1ρ2ρ3ρ4 (4)
21、其中,tatt代表对方算子的攻击能力威胁指标量化值,式(4)的相关参数为:机动能力cap1、武器系统攻击能力cap2、侦察能力cap3、操纵效能系数ρ1、载弹系数ρ2、行程系数ρ3、电子对抗系数ρ4;
22、5)防御能力威胁指标量化:根据装甲类型对坦克算子的防御能力的威胁指标tdef进行量化:复合装甲:tdef=1;重型装甲:tdef=0.7;中型装甲:tdef=0.5;轻型装甲:tdef=0.3;无装甲:tdef=0;
23、6)地形通视威胁指标量化模型如式(5)所示
24、
25、其中,tele代表对方算子的地形通视威胁指标量化值,h和h′分别为对方算子和我方算子的高程,h为双方中间地形的最高高程,t1、t2为通视威胁参数,通常t1,t2∈[0,1],且t1<t2;
26、7)所处环境威胁指标量化模型如式(6)所示
27、
28、其中,tenv代表对方算子所处环境威胁指标量化值,w1、w2、w3是一级公路、二级公路和城镇居民的环境威胁系数,是用于表示算子是否位于一级公路、二级公路或城镇居民区的布尔型变量,若检测到算子处于对应环境,则赋值为1,否则为0;
29、步骤1.2:根据对方算子的实时威胁数据,利用量化模型计算算子的7项威胁指标值,并统一表征为二维威胁评估信息系统s=<u,c,w,v>;论域u={o1,o2,...,om}代表算子集,c={c1,c2,...,cn}代表威胁指标集,w=(w1,w2,...,wn)t代表威胁指标的权重向量,代表威胁指标值集,vik代表第i个算子oi在第k个威胁指标ck上的量化值。
30、进一步的,所述步骤2的具体实施步骤为:
31、步骤2.1:利用消去与选择转换法electre-i获取u中oi的优势集合:[oi]s={oj|oisoj∧oi,oj∈u},s表示优势关系;
32、步骤2.2:给定状态集计算oi关于x的条件概率wk代表指标ck的权重,v′jk代表vjk的归一化值;
33、步骤2.3:计算基于指标值vik的决策损失函数其中,{λpp,λbp,λnp}、{λpn,λbn,λnn}分别表示当oi属于x、不属于x时,将oi划分到x的正域pos、边界域bnd和负域neg的决策损失;
34、步骤2.4:计算将oi划分到x的正域、负域和边界域所产生的贝叶斯期望决策损失
35、步骤2.5:根据贝叶斯期望决策损失最小化目标对算子进行威胁等级划分,获得威胁等级划分结果threat level:若划分到正域的贝叶斯期望决策损失最小,则划分oi到正域pos,即威胁类;若划分到边界域的贝叶斯期望决策损失最小,则划分oi到边界域bnd,即潜在威胁类;若划分到负域的贝叶斯期望决策损失最小,则划分oi到负域neg,即无威胁类;
36、步骤2.6:根据全局和局部排序规则对算子进行综合威胁排序,获得综合威胁排序结果threat rank:在全局排序规则中,对不同域中的算子,将正域中的算子排在边界域中的算子排在最前面,将负域中的算子排在最后面,即,若oi∈pos(x)∨(oi∈bnd(x)∧oj∈neg(x)),则oi>oj;在局部排序规则中,对于同一个域中的算子,将关联损失更低的算子排在前面,即,若则oi>oj,其中,计算方式如式(4)所示:
37、
38、进一步的,所述步骤3主要利用tmadm获得的威胁度评估结果引入到sac策略学习框架中,构建twmadm与sac的融合智能决策模型tmsac,该模型包含三个要点:
39、1)预先设置奖励更新规则,包括对agent在获胜之前每多探索一个回合都设置负向奖励,以防止agent在探索过程中陷入局部最优,同时设置射击综合威胁排序越靠前的算子可得到更高奖励,使sac学习到射击动作优先射击综合威胁排序最高的算子;
40、2)在每个step中,将步骤2中twmadm获得的威胁等级划分结果threat level和综合威胁排序结果threat rank这些威胁评估结果存储到经验缓存池中作为先验知识,sac根据缓存池中的先验知识和奖励更新规则进行策略学习,输出agent的行动策略,agent执行完动作后引发态势变化,此时再根据态势变化和奖励规则更新当前动作生成的奖励,该奖励指引sac在下一个step的策略生成;
41、3)根据正域pos中的算子的数量num,设置agent在num个step中直接按照缓存池中twmadm获得的局部威胁排序结果依次射击正域中的算子,直至正域中的算子都被射击完毕再重新运行局部模块twmadm,减少twmadm的运行频次。
42、进一步的,所述步骤4的具体实施步骤为:
43、步骤4.1:在兵棋推演系统中基于tmsac进行n局的agent训练,直至收敛并稳定到最高奖励状态,训练结束后保存该兵棋推演智能决策模型tmsac,具体为,将tmsac驱动的ai作为训练方,通过sac网络框架选择动作,将规则驱动的ai作为培训方,通过随机数和预先设定的动作概率选择动作,其中,动作概率需通过调参合理设定,使基于该概率的规则ai相对tmsac驱动的ai的平均胜率维持在30%,以便于模型训练;
44、步骤4.2:基于tmsac智能决策方法,通过twmadm模型获得的威胁评估结果和当前双方态势信息,并根据agent的状态空间和动作空间,由sac输出当前态势下我方算子的行动策略。
45、本发明与现有技术相比,其显著优点在于:
46、(1)本发明首次将三支多属性决策模型twmadm与经典的强化学习软表演者-批评家算法sac相结合提出一种混合驱动的兵棋推演智能决策技术tmsac,该技术可有效提高算法采样率和收敛速度,相比现有技术能更快产出战术决策;
47、(2)本发明将twmadm获得的威胁评估结果以先验知识的形式引入到sac的策略学习框架中引导奖励动态更新,并指导我方算子进行高效且准确的动作选择,优先打击掉敌方威胁值最高的算子,从而提升博弈对抗的获胜概率。
- 还没有人留言评论。精彩留言会获得点赞!