一种纵向联邦学习过程中的隐私保护方法与流程
本发明属于涉及隐私保护的机器学习相关领域,具体涉及一种纵向联邦学习过程中的隐私保护方法。
背景技术:
1、机器学习(machinelearning,简称ml)是指用某些算法指导计算机利用已知数据自主构建合理的模型,并利用此模型对新的情境给出判断的过程,在网络搜索、在线广告、商品推荐、机械故障预测、保险定价、金融风险管理等各种应用中发挥着非常重要的作用。传统上,机器学习模型是在一个集中的数据语料库上训练的,这些数据可能是由单个或多个数据提供者收集的。虽然已经开发了并行分布式算法来加速训练过程,但是训练数据本身仍然集中收集和存储在一个数据中心。
2、2018年5月,欧盟通过generaldataprotectionregulation(gdpr)法案把对隐私保护的要求提到了一个新的高度。除此以外,还有很多关于隐私数据的法律法规开始公布。因此,以前平台机构以任意方式进行数据共享受到挑战,也给机器学习的数据收集带来了严重的隐私问题。因为用于机器学习训练的数据通常是敏感的,可能来自具有不同隐私要求的多个所有者。这一严重的隐私问题限制了数据的实际数量。有很多学者提出利用安全多方计算技术直接对数据加密进行训练,显然这样会带来相当大的计算开销。为了应对这一挑战,谷歌引入了联邦学习(fl)系统。一种全面安全的联邦学习框架,包括横向联邦学习(hfl)、纵向联邦学习(vfl)和联邦转移学习(ftl)。
3、联邦学习的定义是各方数据都保留在本地,不泄露隐私也不违反法规;多个参与者联合数据建立虚拟的共有模型,并且共同获益的体系。具体来说吗,可以做到各自数据不出本地,然后通过加密机制下的参数交换方式,在不违反数据隐私法规情况下,建立一个虚拟的共有模型。联邦学习作为一种保障数据安全的建模方法,在销售、金融等行业中拥有巨大的应用前景。在这些行业中,受到知识产权、隐私保护、数据安全等诸多因素影响,数据无法被直接聚合来进行机器学习模型训练。此时,就需要借助联邦学习来训练一个联合模型。
4、鉴于此,目前亟待提出一种纵向联邦学习过程中的隐私保护方法。
技术实现思路
1、为此,本发明所要解决的技术问题是提供一种纵向联邦学习过程中的隐私保护方法。
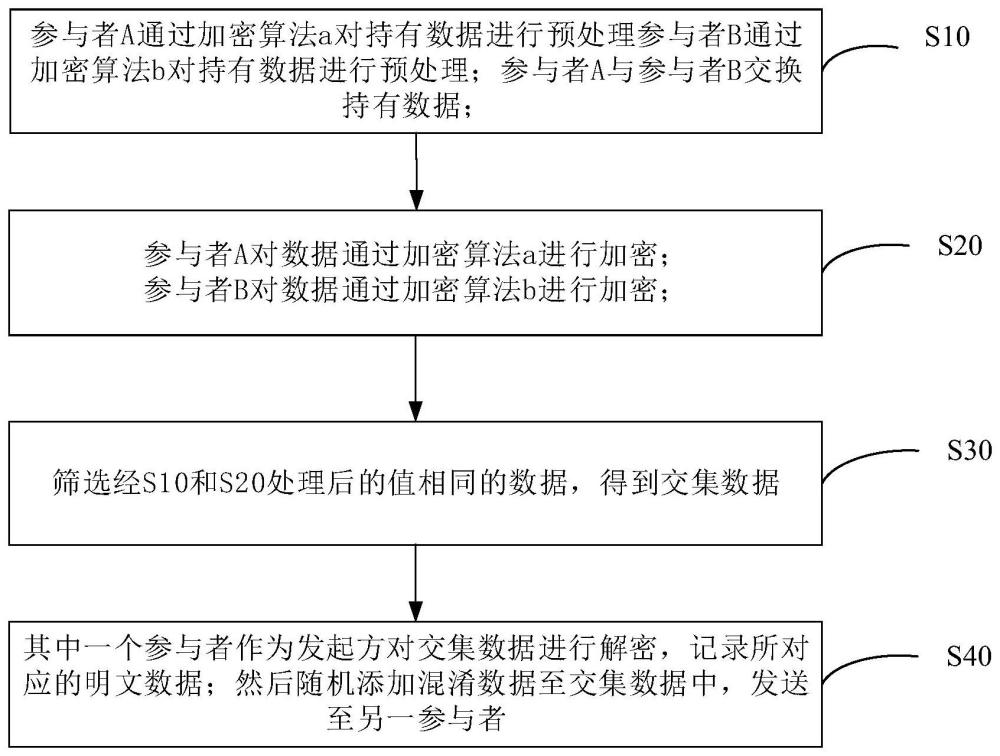
2、本发明的方法,包括:
3、s10,参与者a通过加密算法a对持有数据进行预处理;
4、参与者b通过加密算法b对持有数据进行预处理;
5、参与者a与参与者b交换持有数据;
6、s20,参与者a对数据通过加密算法a进行加密;
7、参与者b对数据通过加密算法b进行加密;
8、s30,筛选经s10和s20处理后的值相同的数据,得到交集数据;
9、s40,其中一个参与者作为发起方对交集数据进行解密,记录所对应的明文数据;然后随机添加混淆数据至交集数据中,发送至另一参与者。
10、优选地,所述持有数据为参与者所持有的客户个人信息。
11、优选地,所述持有数据中包括经预处理的客户id。
12、优选地,所述混淆数据从虚拟数据和/或差集数据中抽取。
13、优选地,所述虚拟数据为虚构的个人身份信息及联系方式。
14、本发明的上述技术方案,相比现有技术具有以下优点:
15、本发明提出了一种纵向联邦学习合作过程中保护弱势方客户隐私的新思路。在纵向联邦学习合作过程中,弱势方为数据使用方,往往缺少数据,需要其他合作方数据的补充;强势方为数据提供方,往往数据充足;弱势方的客户是强势方客户的子集。这样,弱势方可以放心地寻找强势方寻求纵向联邦学习合作,完善精准营销、信贷风控、个性化定价等模型。
16、在纵向联邦学习进行样本求交的过程中,使用了加密算法加混淆样本相结合的方式,强势方无法精确知道双方的交集id,保护了参与联邦学习的弱势方客户隐私。
技术特征:
1.一种纵向联邦学习过程中的隐私保护方法,其特征在于,包括如下步骤:
2.根据权利要求1所述的方法,其特征在于,所述持有数据为参与者所持有的客户个人信息。
3.根据权利要求1所述的方法,其特征在于,所述持有数据中包括经预处理的客户id。
4.根据权利要求1所述的方法,其特征在于,所述混淆数据从虚拟数据和/或差集数据中抽取。
5.根据权利要求1所述的方法,其特征在于,所述虚拟数据为虚构的个人身份信息及联系方式。
技术总结
本发明提供一种纵向联邦学习过程中的隐私保护方法,主要解决纵向联邦学习样本求交过程中的弱势方客户隐私泄露问题。所述方法为,纵向联邦学习过程需要先对数据使用方和数据提供方进行样本求交,对齐样本id,然后才能使用这部分id对应的数据建立机器学习模型。该方法使用加密算法结合混淆样本结合的方式,为纵向联邦学习样本求交提供了更加完善的方式。
技术研发人员:龙桂锋,伍朗,冯智斌
受保护的技术使用者:珠海华发金融科技研究院有限公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!