基于提示学习的零样本可解释性立场检测方法、装置
本发明涉及互联网,具体的说,涉及可用于互联网言论的一种基于提示学习的零样本可解释性立场检测方法、装置。
背景技术:
1、立场检测(stance detection)是指通过计算机自动的给出陈述者陈述内容对某种主题所表达出的立场,比如反对、支持和中立。随着社交媒体,如微博、推特、微信等社媒体的发展,网络用户经常会对自己所关注的内容发表相关的观点,如持反对观点、支持观点、中立观点等。
2、随着机器学习和深度学习的发展,现在研究人员可以使用计算机自动的对文本做所对应主题的立场观点。但是由于社交媒体发言的多样性和数据标注困难问题,给立场检测的发展带来了阻碍。因此研究者们提出了零样本(zero-shot)立场检测,零样本立场检测是指在测试数据中的主题不在训练数据中出现。目前零样本立场检测大致分为三类:基于元学习的方法、基于外部知识的方法、基于对比学习的方法。
3、对于零样本立场检测任务来说,需要模型具有一定的领域迁移能力,使得模型在面对不同的场景、主题和数据分布下都能取得较好的检测结果。目前随着预训练语言模型的发展,给该问题带来了较好解决方案。预训练语言模型,如bert、gpt等在预训练阶段使用大量的来自不同领域、不同分布的文本数据进行多轮训练,使得预训练语言模型在零样本任务中大放异彩。现阶段的立场检测模型本质上是一个分类任务,以往的研究方案使用预训练模型编码文本和主题,之后使用一个新的前馈神经网络进行多分类。虽然预训练模型拥有一定的领域迁移能力,但是新增的前馈神经网络并不具有较强的领域迁移能力。目前已经有一些工作研究立场目标之间的可转移特征,使得模型能够具有领域迁移能力,但是目前的方法都关注于隐式的可转移特征,没有一个很好的显式可转移特征。
4、此外,现有的方法并不能有效的利用预训练语言模型的能力,无法通过预训练语言模型来给立场检测任务提供明确的立场指导。随着提示学习的发展,一些研究者使用提示语来提高预训练语言模型的领域迁移能力。但是现有的提示语基本上还是服务于分类任务,必须在最后使用前馈神经网络进行建模。
5、另一方面,现有的方法不具备较强的解释性,无法给出是那些词语决定了最后的立场分类,不利用在真实场景下的使用。
6、综上所述,现有零样本立场检测任务时,主要存在新增前馈神经网络缺乏领域迁移能力、无法有效利用提示语、不具备可解释性的问题。对此,本技术提出通过一种基于提示学习的零样本可解释性立场检测方法,以解决上述这些缺陷。
技术实现思路
1、针对现有技术的不足,本发明提出一种基于提示学习的零样本可解释性立场检测方法及装置,该方法提高了零样本立场检测的可解释性与检测精度。
2、为了实现上述目的,本发明一方面提供一种基于提示学习的零样本可解释性立场检测方法,包括:
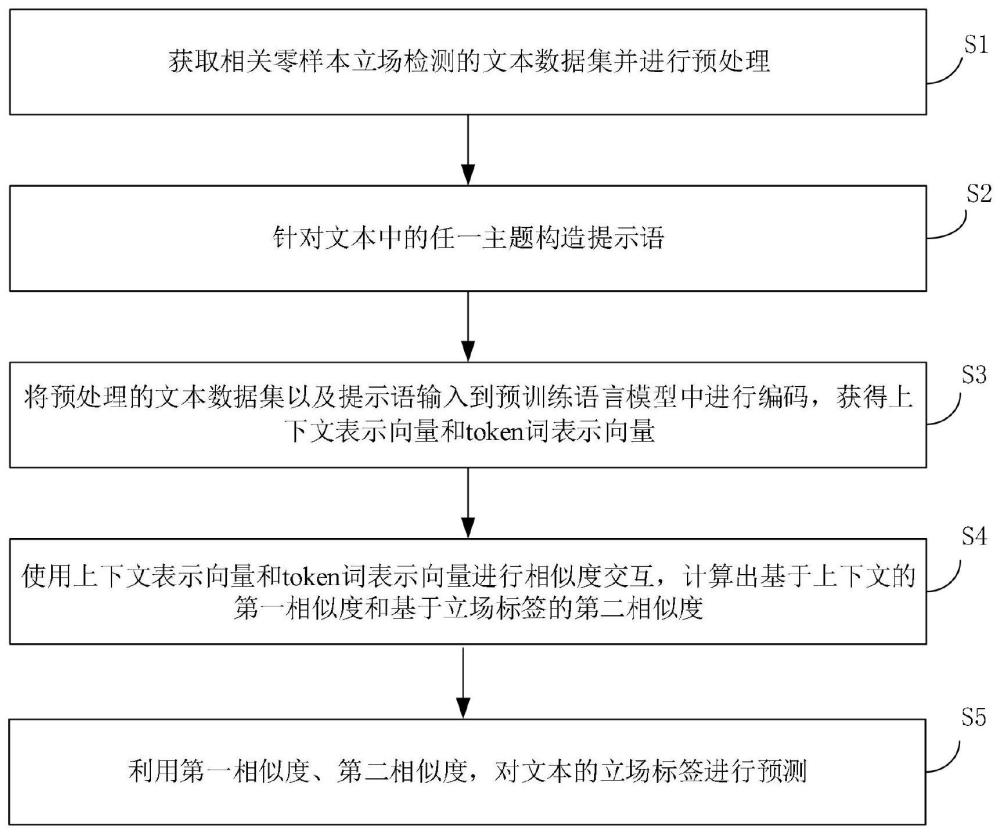
3、获取相关零样本立场检测的文本数据集并进行预处理;
4、针对文本中的任一主题构造提示语,所述提示语中包含一立场标签,所述立场标签包含“支持”、“反对”和“中立”的三个关键词其中之一;
5、将预处理的所述文本数据集以及所述提示语输入到预训练语言模型中进行编码,获得上下文表示向量和token词表示向量;
6、使用所述上下文表示向量和所述token词表示向量进行相似度交互,计算出基于上下文的第一相似度和基于立场标签的第二相似度;
7、利用所述第一相似度、第二相似度,对文本的立场标签进行预测。
8、在一些实施例中,预处理的方法包括:去除停用词、大小写规范化、hashtag处理、噪声数据去除方法中的至少其中之一。
9、在一些实施例中,将预处理后的所述文本数据集输入至所述预训练语言模型bert中进行编码,包含:
10、生成文本的目标表示,包含:
11、在任一文本序列的最前面添加一特殊token[cls]标志,用来获取文本的上下文表示;
12、在文本序列的最后拼接上相对应的主题,并在主题序列的前后位置均添加一特殊token[sep]标志,最终生成文本的目标表示;
13、将文本的目标表示输入至所述预训练语言模型bert中进行编码,获得表示上下文的第一cls向量、和文本的token词向量;
14、所述上下文表示向量包含所述第一cls向量,所述token词表示向量包含文本的token词向量。
15、在一些实施例中,对提示语输入至所述预训练语言模型bert中进行编码,包含:
16、生成提示语的目标表示,包含:
17、一文本对应生成三条提示语,每一提示语中包含一立场标签;
18、在每一提示语最前、后面分别添加一特殊token[cls]标志、token[sep]标志,最终生成提示语的目标表示;
19、将提示语的目标表示输入至所述预训练语言模型bert中进行编码,获得上下文的第二cls向量、和提示语的token词向量;
20、所述上下文表示向量包含所述第二cls向量、所述token词表示向量包含提示语的token词向量。
21、在一些实施例中,将所述第一cls向量与所述第二cls向量进行相似度交互,获得所述第一相似度;
22、将每一提示语的token词向量分别与文本的token词向量中每一个分词的向量表示,进行相似度交互;
23、选出相似度得分最高的一个token分词来代表文本中相对应的立场标签,获得所述第二相似度。
24、在一些实施例中,所述第二相似度表示为:
25、
26、其中,代表第二相似度表示,sim代表点乘的交互方式,文本的token词向量为h={hi}i=1,2..m,hi为其中每一个词的向量表示,文本有m个token分词组成;vk表示每一提示语的token词向量,k∈{s,a,n}分别代表的立场标签为支持、反对和中立。
27、在一些实施例中,将所述第一相似度与第二相似度加权,得到目标相似度;使用所述目标相似度对文本的立场标签进行预测,预测出文本的立场标签。
28、在一些实施例中,所述目标相似度为:
29、
30、其中,λ表示学习的训练参数,表示第一相似度,表示第二相似度;
31、预测出文本的立场标签为:
32、label=argmaxk(sk)
33、其中,label是目标相似度sk中分数最高的那一项所代表的立场标签。
34、在一些实施例中,针对第一相似度,构造第一对比学习损失函数为:
35、
36、其中,代表文本和其标签代表的提示语之间的上下文相似度分数,n代表一个批次的数据数量;
37、针对目标相似度,构造第二对比学习损失函数为:
38、
39、其中,代表文本和其标签代表的提示语之间的最终表示的相似度分数,n代表一个批次的数据数量;
40、将所述第一对比损失函数与第二对比损失函数加权,生成目标损失函数为:
41、
42、其中,表示目标损失函数,λ表示学习的训练参数。
43、本发明另一方面还提供了一种基于提示学习的零样本可解释性立场检测装置,采取上述的基于提示学习的零样本可解释性立场检测方法,至少包含:
44、数据集构建模块,用于获取相关零样本立场检测的文本数据集并进行预处理;
45、提示语构建模块,用于针对文本中的任一主题构造提示语,所述提示语中包含一立场标签,所述立场标签包含“支持”、“反对”和“中立”的三个关键词其中之一;
46、编码模块,用于将预处理的文本数据集以及所述提示语输入到预训练语言模型中进行编码,获得上下文表示向量和token词表示向量;
47、交互模块,用于使用上下文表示向量和token词表示向量进行相似度交互,计算出基于上下文的第一相似度和基于立场标签的第二相似度;
48、标签预测模块,用于利用所述第一相似度、第二相似度,对文本的立场标签进行预测,并对网络进行训练。
49、本发明另一方面还提供一种存储介质,用于存储一种用于执行上述的基于提示学习的零样本可解释性立场检测方法的计算机程序。
50、由以上方案可知,本发明的优点在于:
51、本发明提供的基于提示学习的零样本可解释性立场检测方法,其针对文本中的任一主题构造提示语,提示语中包含一立场标签,通过提示语引入了具有明确倾向的立场标签,为模型提供了明确的立场指导。此外,通过将预处理的文本数据集以及提示语输入到预训练语言模型bert中进行编码,获得上下文表示向量和token词表示向量,将分类任务转化为排序任务,仅使用预训练语言模型bert,未引入任何其他的网络模型,充分利用了预训练模型的迁移能力。此外,本实施例中,使用上下文表示向量和token词表示向量进行相似度交互,计算出基于上下文的第一相似度和基于立场标签的第二相似度;并利用第一相似度、第二相似度,对文本的立场标签进行预测。其通过基于上下文的显式可转移特征和基于立场词的显式可转移特征,通过立场词之间的相似度交互,可以找出文本中表示立场倾向的词语,使得模型具有一定的可解释性。
- 还没有人留言评论。精彩留言会获得点赞!