一种数据处理方法、装置及计算机集群系统与流程
本技术涉及信息安全,可用于金融领域,特别涉及一种数据处理方法、装置及计算机集群系统。
背景技术:
1、大数据时代,越来越多的银行用户选择将spark任务部署在第三方云服务中执行,spark任务在云服务中的运行属于黑盒操作,用户无法得知诸如数据传输过程中的篡改、恶意操作、监听等安全问题,云服务商在给银行用户提供便捷的服务时,还应该保障数据的机密性和完整性。如果银行用户运行在云服务内的spark任务中的数据遭到了攻击者的窃取,这不仅会泄露用户的敏感数据,还会对第三方云服务商的信誉造成难以挽回的损失。目前已有的方案选择将大数据任务放入可信执行环境执行,并对可信执行环境以外的数据进行加密以保护数据的机密性,但是假如攻击者是第三方云服务的管理人员或者取得了管理人员权限,攻击者就可以结合先验知识,通过观测不同节点间的数据流向以获取用户数据集的部分信息从而完成隐信道攻击破坏spark任务的机密性。此外,攻击者还可以通过丢弃、重发或者构造假数据等方式来破坏spark任务的完整性,使用户无法获取正确的执行结果。
2、为了解决机密性和完整性的问题,现有技术提出了spark任务机密性和完整性保护方案,以是否在shuffle read阶段执行聚合操作为划分依据,将spark任务分为聚合性任务和非聚合性任务,并针对这两种任务所产生的中间数据填充虚拟数据以使得所有数据的长度均相同,从而起到混淆的目的。
3、然而,现有技术中是根据人为设定的数据长度确定需要填充的虚拟数据量的,若人为设定的数据目标长度较短,则依然容易被攻击者破坏机密性或完整性,而若人为设定的数据目标长度较长,则会导致数据计算量较大,使得大数据的处理效率较低。现有技术中通过人工取逐步调整数据目标长度的方式来最优的数据目标长度,并且还需要针对每个云服务用户的业务发展情况变更数据目标长度。这使得研发人员的工作量较大、过程较为繁琐。
技术实现思路
1、本说明书提供一种数据处理方法、装置及计算机集群系统,以解决现有数据处理方法通过人工方式确定数据目标长度的工作量较大、过程较为繁琐的问题。
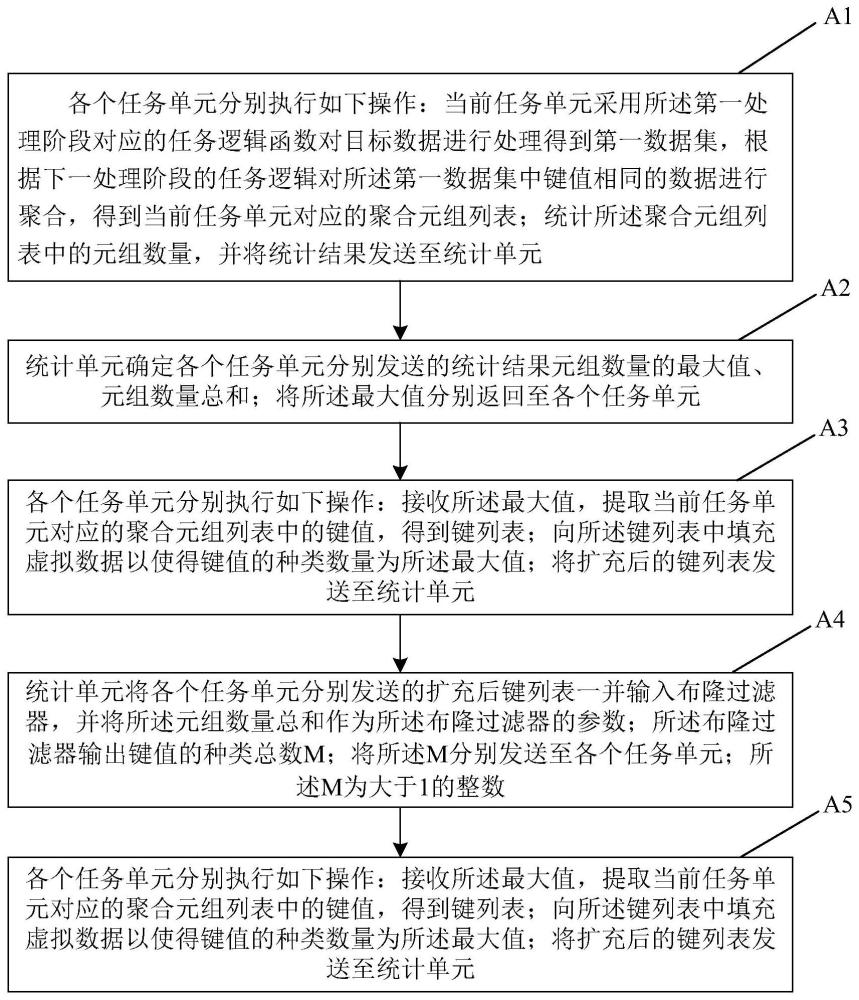
2、本说明书第一方面提供一种数据处理方法,目标数据依次经过多个处理阶段的任务单元处理后得到目标处理结果,每个处理阶段包括多个处理环节、统计环节;其中,所述目标数据的第一处理阶段包括:第一处理环节,用于各个任务单元分别执行如下操作:当前任务单元采用所述第一处理阶段对应的任务逻辑函数对目标数据进行处理得到第一数据集,根据下一处理阶段的任务逻辑对所述第一数据集中键值相同的数据进行聚合,得到当前任务单元对应的聚合元组列表;统计所述聚合元组列表中的元组数量,并将统计结果发送至统计单元;第一统计环节,用于统计单元确定各个任务单元分别发送的统计结果元组数量的最大值、元组数量总和;将所述最大值分别返回至各个任务单元;第二处理环节,用于各个任务单元分别执行如下操作:接收所述最大值,提取当前任务单元对应的聚合元组列表中的键值,得到键列表;向所述键列表中填充虚拟数据以使得键值的种类数量为所述最大值;将扩充后的键列表发送至统计单元;第二统计环节,用于统计单元将各个任务单元分别发送的扩充后键列表一并输入布隆过滤器,并将所述元组数量总和作为所述布隆过滤器的参数;所述布隆过滤器输出键值的种类总数m;将所述m分别发送至各个任务单元;所述m为大于1的整数;第三处理环节,用于各任务单元分别执行如下操作:接收所述m,向当前任务单元对应的聚合元组列表中填充虚拟数据以使聚合元组列表中的键值种类总数为所述m,将扩充后的聚合元组列表发送至下一处理阶段的任务单元进行处理;所述n为大于1的整数。
3、在一些实施例中,第一处理环节还用于统计所述聚合元组列表中的最大元组长度;相应地,所述统计第一统计环节还用于将各个任务单元发送的所述最大元组长度相加,得到最大长度之和,并将所述最大长度之和返回至各个任务单元;所述第三处理环节在向当前任务单元对应的聚合元组列表中填充虚拟数据时,还使聚合元组列表中的每个元组的长度为所述最大长度之和。
4、在一些实施例中,所述目标数据的中间处理阶段包括:第一验证环节,用于对上一处理阶段的各任务单元发送的聚合元组列表进行验证;第四处理环节,用于对验证通过的聚合元组列表,去除虚拟元组,得到真实的聚合元组列表;第五处理环节,用于各个任务单元分别执行如下操作:当前任务单元采用所述中间处理阶段对应的任务逻辑函数对所述真实的聚合元组列表进行处理得到第二数据集,根据下一处理阶段的任务逻辑对所述第二数据集中键值相同的数据进行聚合,得到当前任务单元对应的聚合元组列表;统计所述聚合元组列表中的元组数量,并将统计结果发送至统计单元;第三统计环节,用于统计单元确定各个任务单元分别发送的统计结果元组数量的最大值、元组数量总和;将所述最大值分别返回至各个任务单元;第六处理环节,用于各个任务单元分别执行如下操作:接收所述最大值,提取当前任务单元对应的聚合元组列表中的键值,得到键列表;向所述键列表中填充虚拟数据以使得键值的种类数量为所述最大值;将扩充后的键列表发送至统计单元;第四统计环节,用于统计单元将各个任务单元分别发送的扩充后键列表输入布隆过滤器,并将所述元组数量总和作为所述布隆过滤器的参数;所述布隆过滤器输出键值的种类总数m;将所述m分别发送至各个任务单元;第七处理环节,用于各任务单元分别执行如下操作:接收所述m,向当前任务单元对应的聚合元组列表中填充虚拟数据以使聚合元组列表中的键值种类总数为所述m,将扩充后的聚合元组列表发送至下一处理阶段的任务单元进行处理。
5、在一些实施例中,第五处理环节还用于统计所述聚合元组列表中的最大元组长度;相应地,所述统计第三统计环节还用于将各个任务单元发送的所述最大元组长度相加,得到最大长度之和,并将所述最大长度之和返回至各个任务单元;所述第六处理环节在向当前任务单元对应的聚合元组列表中填充虚拟数据时,还使聚合元组列表中的每个元组的长度为所述最大长度之和。
6、在一些实施例中,所述目标数据的最后处理阶段包括:第二验证环节,用于对上一处理阶段的各任务单元发送的聚合元组列表进行验证;第八处理环节,用于对验证通过的聚合元组列表,去除虚拟元组,得到真实的聚合元组列表;第九处理环节,用于各个任务单元分别执行如下操作:当前任务单元采用所述最后处理阶段对应的任务逻辑函数对所述真实的聚合元组列表进行处理得到所述目标数据的目标处理结果;存储环节,用于将所述目标数据的目标处理结果存储至文件系统。
7、本说明书第二方面提供一种数据处理装置,其特征在于,包括:第一处理单元,用于各个任务单元分别执行如下操作:当前任务单元采用所述第一处理阶段对应的任务逻辑函数对目标数据进行处理得到第一数据集,根据下一处理阶段的任务逻辑对所述第一数据集中键值相同的数据进行聚合,得到当前任务单元对应的聚合元组列表;统计所述聚合元组列表中的元组数量,并将统计结果发送至统计单元;第一统计单元,用于统计单元确定各个任务单元分别发送的统计结果元组数量的最大值、元组数量总和;将所述最大值分别返回至各个任务单元;第二处理单元,用于各个任务单元分别执行如下操作:接收所述最大值,提取当前任务单元对应的聚合元组列表中的键值,得到键列表;向所述键列表中填充虚拟数据以使得键值的种类数量为所述最大值;将扩充后的键列表发送至统计单元;第二统计单元,用于统计单元将各个任务单元分别发送的扩充后键列表一并输入布隆过滤器,并将所述元组数量总和作为所述布隆过滤器的参数;所述布隆过滤器输出键值的种类总数m;将所述m分别发送至各个任务单元;所述m为大于1的整数;第三处理单元,用于各任务单元分别执行如下操作:接收所述m,向当前任务单元对应的聚合元组列表中填充虚拟数据以使聚合元组列表中的键值种类总数为所述m,将扩充后的聚合元组列表发送至下一处理阶段的任务单元进行处理;所述n为大于1的整数。
8、在一些实施例中,第一处理单元还用于统计所述聚合元组列表中的最大元组长度;相应地,所述统计第一统计单元还用于将各个任务单元发送的所述最大元组长度相加,得到最大长度之和,并将所述最大长度之和返回至各个任务单元;所述第三处理单元在向当前任务单元对应的聚合元组列表中填充虚拟数据时,还使聚合元组列表中的每个元组的长度为所述最大长度之和。
9、在一些实施例中,所述目标数据的中间处理阶段包括:第一验证单元,用于对上一处理阶段的各任务单元发送的聚合元组列表进行验证;第四处理单元,用于对验证通过的聚合元组列表,去除虚拟元组,得到真实的聚合元组列表;第五处理单元,用于各个任务单元分别执行如下操作:当前任务单元采用所述中间处理阶段对应的任务逻辑函数对所述真实的聚合元组列表进行处理得到第二数据集,根据下一处理阶段的任务逻辑对所述第二数据集中键值相同的数据进行聚合,得到当前任务单元对应的聚合元组列表;统计所述聚合元组列表中的元组数量,并将统计结果发送至统计单元;第三统计单元,用于统计单元确定各个任务单元分别发送的统计结果元组数量的最大值、元组数量总和;将所述最大值分别返回至各个任务单元;第六处理单元,用于各个任务单元分别执行如下操作:接收所述最大值,提取当前任务单元对应的聚合元组列表中的键值,得到键列表;向所述键列表中填充虚拟数据以使得键值的种类数量为所述最大值;将扩充后的键列表发送至统计单元;第四统计单元,用于统计单元将各个任务单元分别发送的扩充后键列表输入布隆过滤器,并将所述元组数量总和作为所述布隆过滤器的参数;所述布隆过滤器输出键值的种类总数m;将所述m分别发送至各个任务单元;第七处理单元,用于各任务单元分别执行如下操作:接收所述m,向当前任务单元对应的聚合元组列表中填充虚拟数据以使聚合元组列表中的键值种类总数为所述m,将扩充后的聚合元组列表发送至下一处理阶段的任务单元进行处理。
10、在一些实施例中,第五处理单元还用于统计所述聚合元组列表中的最大元组长度;相应地,所述统计第三统计单元还用于将各个任务单元发送的所述最大元组长度相加,得到最大长度之和,并将所述最大长度之和返回至各个任务单元;所述第六处理单元在向当前任务单元对应的聚合元组列表中填充虚拟数据时,还使聚合元组列表中的每个元组的长度为所述最大长度之和。
11、在一些实施例中,所述目标数据的最后处理阶段包括:第二验证单元,用于对上一处理阶段的各任务单元发送的聚合元组列表进行验证;第八处理单元,用于对验证通过的聚合元组列表,去除虚拟元组,得到真实的聚合元组列表;第九处理单元,用于各个任务单元分别执行如下操作:当前任务单元采用所述最后处理阶段对应的任务逻辑函数对所述真实的聚合元组列表进行处理得到所述目标数据的目标处理结果;存储单元,用于将所述目标数据的目标处理结果存储至文件系统。
12、本说明书第三方面提供一种计算机集群系统,包括多个计算机节点,所述多个计算机节点相互配合以实现第一方面任一项所述方法的步骤。
13、在一些实施例中,所述计算机集群系统采用spark任务处理机制。
14、本说明书第四方面提供一种电子设备,包括:存储器和处理器,所述处理器和所述存储器之间互相通信连接,所述存储器中存储有计算机指令,所述处理器通过执行所述计算机指令,从而实现第一方面任一项所述方法的步骤。
15、本说明书第五方面提供一种计算机存储介质,所述计算机存储介质存储有计算机程序指令,所述计算机程序指令被执行时实现第一方面任一项所述方法的步骤。
16、本说明书第六方面提供一种计算机程序产品,包含有计算机程序,所述计算机程序被处理器执行时实现第一方面任一项所述方法的步骤。
17、上述数据处理方法、装置及计算机集群系统,各任务单元在对目标数据进行任务逻辑处理完毕后,先对处理结果进行聚合得到聚合元组列表,统计聚合元组列表中的元组数量,并将统计结果发送至统计单元;统计单元统计各任务单元发送的元组数量中的最大值和总和,将最大值返回至各个任务单元;各任务单元提取聚合元组列表中的键值得到键列表,向键列表中填充虚拟数据以使得键值的种类数量为该最大值;将扩充后的键列表发送至统计单元;统计单元将各个任务单元发送的扩充后的键列表输入布隆过滤器统计键值的种类总数m,将m发送至各个任务单元;各任务单元向聚合元组列表中填充数据以使得聚合元组列表中的键值种类总数为m,将扩充后的聚合元组列表发送至下一处理阶段的任务单元进行处理。
18、本方案中由各任务单元自身统计聚合元组列表中的元组数量,将元组数量发送至统计单元,而并不是将聚合元组列表本身发送至统计单元,能够防止聚合元组列表被窃取或丢失导致统计结果不准确。
19、本方案中由各任务单元提取键聚合列表,并向键聚合列表中填充虚拟数据后再发送至统计单元进行统计,隐藏了真实键聚合列表中的键的数量,提高了数据的机密性;将键聚合列表扩充填充虚拟数据扩充至各聚合列表中元组数据的最大值,既能够隐藏真实元组列表中键的数量,又可以减少数据处理量,提高云服务平台的大数据处理效率。
20、本方案中由布隆过滤器对spark任务整体所产生的键的数量进行统计,由于布隆过滤器不会存储数据,统计操作较为安全,且高效;将先前统计得到的元组数量总和作为布隆过滤器的参数既能够满足该极端情况,又能够使得布隆过滤器所占用的空间最小。
21、通过上述分析可知,本说明书提供的数据处理方法,一方面无需人工确定扩充数据的目标数据长度,另一方面还可以在提高数据机密性的前提下,最少化数据处理量、最小化程序占用空间。
- 还没有人留言评论。精彩留言会获得点赞!