复杂车联网中基于区块链的个性化模型和数据共享方法
本发明属于移动通信,涉及一种复杂车联网中基于区块链的个性化模型和数据共享方法。
背景技术:
1、近年来,智能网联汽车(connected and automated vehicle,cav)作为第六代移动通信(sixth generation,6g)的关键垂直应用开始涌入大众视野,其借助车载传感器和通信技术在多个分散地理位置实时产生着前所未有的大量感知数据。传统机器学习通过路侧单元(road side unit,rsu)或基站(base station,bs)自下而上的大规模感知数据收集,能够有效支持行人检测、流量预测、路径规划等智能驾驶模型的分布式训练。然而,集中式机器学习方式存在单点故障问题,且无法满足用户隐私和数据安全的要求。
2、联邦学习(federated learning,fl)作为一种分布式学习范式通过交互模型而非原始数据,成为保护用户隐私的有效方案。此外,区块链技术使rsu或bs共同维护一个可追溯、不可篡改的分布式账本以实现数据安全的同时预防单点故障问题。然而,由于车联网环境的动态复杂变化以及用户驾驶偏好不同,车辆数据和跨车辆数据呈现出明显的非独立同分布(non-independent and identically distributed,non-iid)特点,导致模型训练精度降低。同时,隧道、盘山路、乡村道路等特殊交通场景难以搜集到足够数量的训练数据,且锥形筒路标、罕见大车等少见样本无法充分发挥作用,引发小样本数据学习困难的问题。
3、另外,由于不同交通场景下的用户驾驶偏好和习惯不尽相同,通用的全局模型很难满足所有用户的需求,如何为每个独立用户训练个性化的任务模型以满足其特定需求成为学术界和工业界的研究热点。同时,一致性的同构模型并未考虑车辆可用资源的变化情况,训练不同体量的任务模型以适应可用资源不同的场景更符合复杂车联网环境的实际需求。
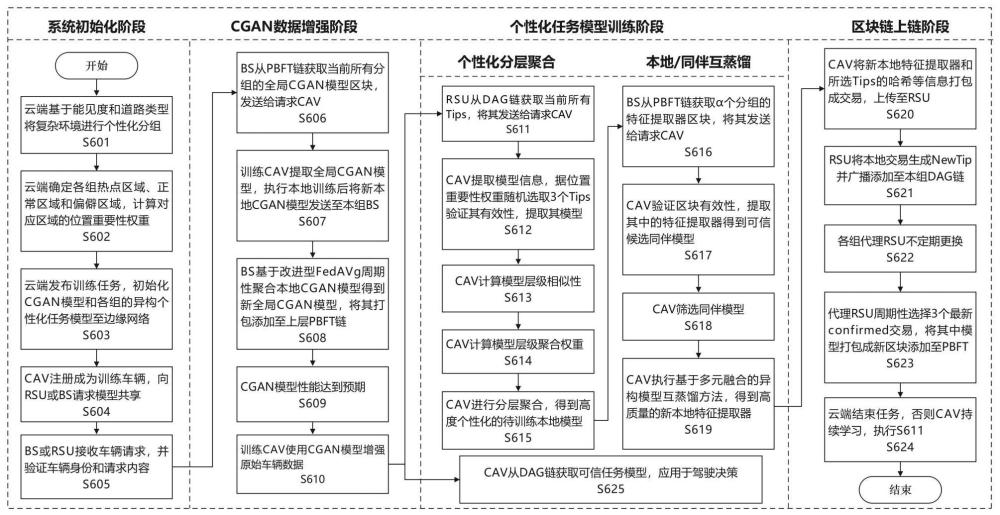
4、基于上述问题,本发明设计了一种复杂交通环境中基于区块链的个性化异构联邦互蒸馏方法。首先根据能见度和道路类型将复杂环境进行个性化分组,并考虑可用资源差异允许不同场景之间的个性化任务模型异构。其次,建立基于双层区块链的云-边-端三层网络架构,实现安全高效的异步联邦学习和跨组模型共享。之后,提供一种基于对抗生成网络(conditional generative adversarial nets,cgan)的数据增强方法以降低数据异质性和小样本学习难度。最后,设计一种基于客户端相似性的个性化分层聚合策略和一种基于多元知识融合的异构模型互蒸馏方案,实现复杂车联网环境中异构联邦互蒸馏的高质量和高度个性化。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种复杂车联网中基于区块链的个性化模型和数据共享方法。
2、为达到上述目的,本发明提供如下技术方案:
3、第一方面,本发明实施例根据车联网场景复杂性以及车辆数据隐私保护要求,利用双层区块链架构实现个性化异构模型互蒸馏,该方法包括以下步骤:
4、s1:基于能见度和道路类型的复杂环境个性化分组;
5、s2:建立基于云-边-端三层架构的双层区块链;
6、s3:基于cgan进行数据增强;
7、s4:进行基于客户端相似性的个性化分层聚合;
8、s5:进行基于多元知识融合的异构模型互蒸馏。
9、第二方面,本发明实施例在s1中,根据道路能见度和道路类型对复杂交通环境进行个性化分组,以减轻组内数据异质性并增强个性化。考虑到相同道路类型和相似能见度下的用户驾驶偏好相似,能见度被划分为“强、中、弱”三级,再结合城市主干道、高架桥、隧道等7种常见道路类型,复杂交通环境被大致划分为21种场景,即21个分组。所有分组协同并行训练个性化任务模型,且该模型划分为特征提取器和个性化决策器两个组件,特征提取器在组内和组间共享以获取更多样化的公共知识加速模型收敛,个性化决策器保留在cav端以学习本地个性化知识提升本地模型精度。同时,由于不同场景内任务训练强度和训练难度不同,单项任务的可用车辆资源在不同场景之间存在差异,所以个性化任务模型在同一场景内模型同构,在不同场景之间模型异构,车辆资源越紧张的场景训练越轻量的任务模型,进一步增强车辆个性化范围。
10、第三方面,本发明实施例在s2中,建立基于云-边-端网络架构的双层区块链,以在车联网中实现安全高效的异步联邦学习和跨组模型共享,其架构包括云层、边缘层和终端层。云层负责基于能见度和道路类型对复杂交通环境进行个性化分组,统筹各组内和组间的移动cav协作训练cgan模型和个性化任务模型,提供全局解决方案。边缘层被划分为多个分组,每个分组独立维护dag区块链,负责分组内模型数据的高并发异步共享,所有分组共同维护pbft主链,负责任务模型的特征提取器和cgan模型的安全跨组共享,组成双层区块链架构。终端层的cav负责cgan数据增强模型和个性化任务模型的分布式协作训练。
11、第四方面,本发明实施例在s3中,提供一种基于cgan的数据增强方法来缓解数据异构程度大以及小样本学习困难的问题。cgan模型由鉴别器和生成器两个组件构成,鉴别器区分虚拟数据和真实数据以最大化分类的准确率,生成器从随机噪声中学习并生成与真实数据相似的虚拟数据以最小化鉴别器的准确率,两者按照二元极小极大值博弈优化cgan模型,最终可生成指定标签类别且逼近真实数据特征的虚拟样本。在训练个性化任务模型过程中,cav通过pbft链获取当前所有分组的cgan全局模型,再采用基于位置重要性的改进型fedavg方法对cgan模型进行分布式训练,最后使用cgan生成器扩充原始数据,从而平衡训练数据集分布,挖掘少见样本数据特征,提升个性化任务模型训练的准确性。
12、第五方面,本发明实施例在s4中,设计一种基于客户端相似性的个性化分层聚合策略,以帮助cav聚合得到高度个性化的待训练本地任务模型。由于神经网络模型的不同层可能具有不同的效用,模型级整体度量难以准确反映层级差异,故采用分层聚合代替常规模型级聚合以实现更精准的个性化训练。首先,cav从dag链上按照位置重要性权重随机选取3个tips,并采用中心核对齐(centered kernel alignment,cka)方法评估3个tips中特征提取器的层级相似性,再结合客户端数量大小以及客户端样本多样性,将所获特征提取器进行更精准的个性化分层聚合,最终实现待训练本地任务模型的高度个性化。
13、第六方面,本发明实施例在s5中,提出一种基于多元知识融合的异构模型互蒸馏方案,以实现跨组异构模型的高质量互学习。首先,cav通过pbft主链获取其他分组最新的可信特征提取器,作为可信候选同伴模型;之后,采用余弦相似度计算候选同伴与本地模型之间的输出相似性,并选取相似性最高的前n个分组的模型作为同伴模型,以加强相似分组协作;最后通过相似性权重和精度权重鼓励同伴贡献高质量同伴协作知识,通过相似性权重和时间陈旧性权重鼓励本地模型复习高质量历史知识,从而实现基于多元知识融合的抗模型遗忘性和抗数据异构性的跨组异构模型高质量互蒸馏。
14、本发明的有益效果在于:
15、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!