一种面向DNN模型的Crossbar级异构ReRAM加速器配置方法及系统
本发明涉及计算机科学人工智能领域,尤其涉及一种面向dnn模型的crossbar级异构reram加速器配置方法及系统。
背景技术:
1、人工智能技术已经在众多领域发挥作用,并受到了业界和学术界的极大关注。深度神经网络(dnn)作为人工智能神经网络的进化形式,其应用覆盖了各个领域,如图像处理、语音识别、自然语言处理、推荐系统等。然而,为了提高神经网络在训练和推理过程中的表现,网络的层数不断加深,参数量不断增大,这带来了对计算资源的巨大需求。传统的计算硬件,如中央处理器(cpu)和图形处理器(gpu),在处理复杂的dnn模型时往往面临计算能力瓶颈,这限制了模型的规模和性能。其次,dnn的计算流程通常需要大量的数据传输和存储。传统的存储解决方案,如动态随机存储器(dram),在处理海量数据时可能成为性能瓶颈。再者,高性能计算硬件通常需要大量的电能供应,这导致了高昂的能源成本,并对环境产生不利影响。此外,对于移动设备和嵌入式系统,高功耗也限制了电池寿命和设备的便携性。随着dnn模型的不断发展,它们的规模和复杂性也在迅速增加。这需要更多的存储和更高的计算能力,因此需要新的硬件技术来应对挑战。
2、应用可重写型阻变存储器(reram)来解决深度神经网络(dnn)面临的挑战是一个备受关注的领域。reram是一种存内计算(pim)设备,能够以原位计算的方式执行矩阵向量乘法(mvm)来节省数据传输开销。如图1所示,在基于reram的加速器中,交叉横杆(crossbar)是由基于reram的单元(cell)组成的交叉计算阵列,通过将dnn的参数权重存储为电导,将输入数据转换为电压,依据欧姆定律二者相乘所得的电流就是神经网络中一次点积的结果。将输入按行方向的字线并联、输出沿列方向的位线叠加,就相当于完成了一次mvm运算。它具有以下特点:
3、1)低功耗:reram具有较低的功耗特性,因为它在状态保持期间不需要额外的电能供应。这使得它在推理过程中能够显著降低功耗,适用于移动设备和能源受限的环境。
4、2)高密度和快速访问:reram可以实现高密度的数据存储,并具有较快的访问速度。这使其能够有效地管理dnn中的大规模模型和大规模数据集。
5、3)可编程性:reram可以通过改变电阻状态来存储数据,这使其可以用于实现神经元之间的权重和连接。这种可编程性使得reram成为加速dnn推理的潜在硬件加速器。
6、4)非易失性:reram是一种非易失性存储器(nvm),它可以保存数据而不需要持续的电源供应。这对于dnn模型的可靠性和数据持久性非常重要。
7、尽管潜力巨大,但基于reram的dnn加速器研究仍处于早期阶段,有许多挑战尚待克服。一般来说,提高crossbar的利用率以及降低计算过程整体的延迟和能耗是设计时重点考虑的目标。在以前的工作中,通常采用同构化的硬件设计,即所有crossbar阵列的纵横大小都是相同的。然而在dnn中,不同深度的层之间的配置可能会有所不同,以二维的卷积核为例,它们的高和宽可能变化,同时各层的通道数也不尽相同。二者的不匹配会在权重映射的结果中引入crossbar内的碎片。另外,在目前普遍的多级计算单元架构,即处理引擎(pe)—区块(tile)—crossbar下,对于某一层而言,映射策略会独占选中的tile,即使当前层的权重都映射完成而tile中还有空闲的crossbar时,也不会将其分配给其他的层。以上的情况都表明利用率方面还有改进的空间。
8、在系统性能方面,过去的研究表明crossbar的大小会影响系统的能耗。这主要是由能耗占比大的外部电路(pc)引起的,如模数转换器(adc)等。将一个同样大小的参数矩阵映射到大crossbar上可以降低能耗,因为小crossbar会更多地分割参数矩阵从而引入更多的adc。然而大crossbar更容易产生内部碎片,使整体利用率减少,降低计算效率。二者围绕crossbar大小构成了一组权衡,为了更好发挥reram加速器的性能,值得考虑为网络中不同的层分别选择合适的crossbar大小。然而随着dnn层数的加深以及层间数据依赖关系的存在,搜索空间变得巨大且难以手动指定;另外分层异构的架构设计如何实现也是一个挑战。
技术实现思路
1、本发明的目的是:针对dnn中不同层权值量差异大、采用同构crossbar映射硬件利用率低的问题,提出一种面向dnn模型的crossbar级异构reram加速器配置方法及系统。
2、本发明采用的技术方案是:
3、一种面向dnn模型的crossbar级异构reram加速器配置方法,其特征在于,具体为:
4、获取dnn模型的每一网络层的结构信息作为状态信息;
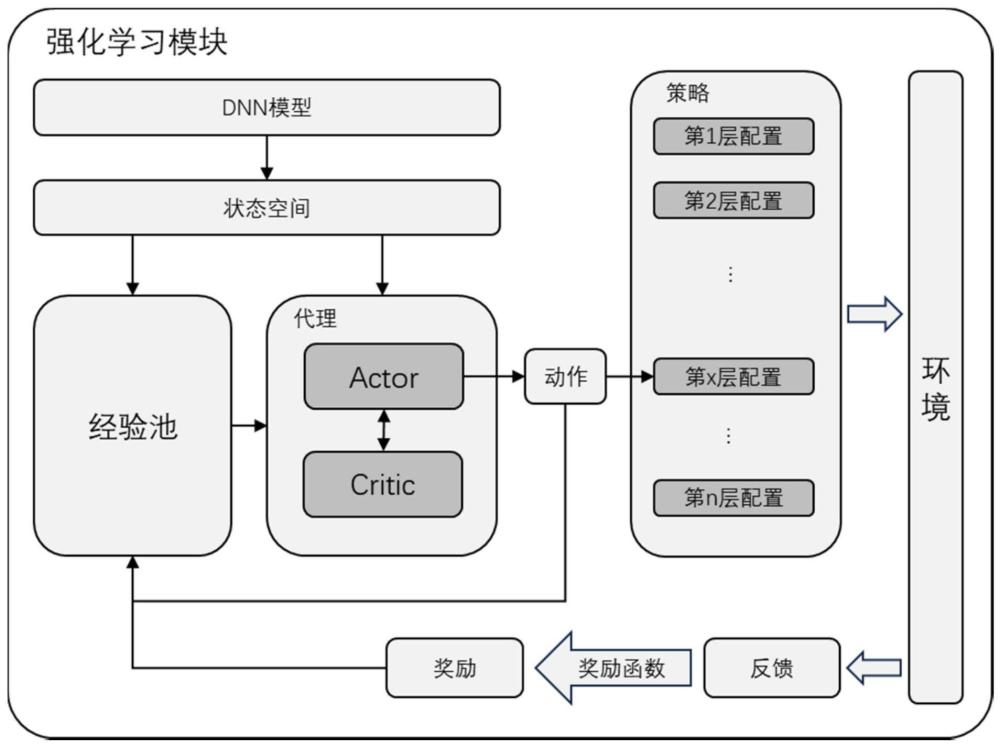
5、分别选择成对的两个神经网络模型作为现实表演者-目标表演者、以及现实评论者-目标评论者,以最优的层级异构crossbar配置作为学习目标,基于强化学习进行若干批次迭代配置:
6、在每个批次中,每次迭代以当前网络层的结构信息作为输入,通过现实表演者、目标表演者从环境中学习有价值的信息并在每一步输出动作影响环境;所述动作为dnn模型的一网络层对应的crossbar大小;全部迭代完毕后输出动作策略;全部迭代完毕后环境会根据动作策略的表现给予奖励;现实评论者、目标评论者分别输出对现实表演者、目标表演者输出的每一动作的评价;其中,现实评论者通过最小化现实评论者、目标评论者的损失值作为损失函数进行优化训练网络参数;现实表演者通过最小化现实评论者的输出的负数得到用于参数更新的策略梯度进行优化训练网络参数;目标评论者、目标表演者采用软更新;奖励函数为由归一化的crossbar利用率u和系统能量e组成的多项式;最后一个批次输出的动作策略即为最终的crossbar级异构reram加速器配置结果。
7、进一步地,每一网络层的结构信息包括:网络层编号、网络层类型、输入通道数、输出通道数、网络层卷积核的大小、卷积步长、网络层权重参数量、输入特征图的大小中的一种或多种。
8、进一步地,在每次迭代中,还包括将状态、动作、奖励的组合记作一次经验样本并存储至经验池中。
9、进一步地,在每个批次迭代配置中,全部迭代完毕后,会从经验池中采样出一批样本数据,对表演者和评论者进行训练优化。
10、进一步地,所述基于强化学习进行迭代配置过程中,前若干个批次为热身阶段,动作随机产生。
11、进一步地,奖励函数表示为:
12、reward=hu*u+he*(1-e)
13、其中hu和he是实现利用率和能耗之间权衡的超参数。
14、进一步地,所述现实评论者对应的损失函数表示如下:
15、
16、式中,si,ai分别表示dnn模型第i层网络层对应的结构信息和现实表演者输出的动作,si+1,ai+1分别表示dnn模型第i+1层网络层对应的结构信息和目标表演者输出的动作,qw(*)表示现实评论者输出的对当前状态-动作的评价,qw′(*)表示目标评论者输出的对下一层状态-动作的评价;n表示dnn模型网络层的数量。
17、进一步地,还包括基于最佳适配原则,对最终的crossbar级异构reram加速器配置结果进行组合合并区块。
18、进一步地,所述环境通过模拟器实现,所述模拟器接收表演者输出的动作策略,执行dnn模型到reram crossbar的映射和推理过程,收集利用率、能耗性能数据进行反馈。
19、一种面向dnn模型的crossbar级异构reram加速器配置系统,用于实现所述面向dnn模型的crossbar级异构reram加速器配置方法,包括:
20、数据获取模块,用于获取dnn模型的每一网络层的结构信息作为状态信息;
21、强化学习模块,分别选择成对的两个神经网络模型作为现实表演者-目标表演者、以及现实评论者-目标评论者,以最优的层级异构crossbar配置作为学习目标,基于强化学习进行若干批次迭代配置:
22、在每个批次中,每次迭代以当前网络层的结构信息作为输入,通过现实表演者、目标表演者从环境中学习有价值的信息并在每一步输出动作影响环境;所述动作为dnn模型的一网络层对应的crossbar大小;全部迭代完毕后输出动作策略;全部迭代完毕后环境会根据动作策略的表现给予奖励;现实评论者、目标评论者分别输出对现实表演者、目标表演者输出的每一动作的评价;其中,现实评论者通过最小化现实评论者、目标评论者的损失值作为损失函数进行优化训练网络参数;现实表演者通过最小化现实评论者的输出的负数得到用于参数更新的策略梯度进行优化训练网络参数;目标评论者、目标表演者采用软更新;奖励函数为由归一化的crossbar利用率u和系统能量e组成的多项式;最后一个批次输出的动作策略即为最终的crossbar级异构reram加速器配置结果;
23、模拟器,负责接收强化学习模块传递的动作策略,执行dnn模型到reram crossbar的映射和推理过程,收集利用率、能耗性能数据进行反馈。
24、本发明的有益效果是:本发明面向基于reram的存内计算架构,分析模型层中权重参数与crossbar大小在性能表现中的关系,提出分层异构的思想;具体来说,采用了强化学习代理与reram加速器进行交互,实现自动化搜索并进行模型异构配置,在不损失模型精度的情况下,能够有效提升crossbar利用率,降低系统计算延迟和能耗。
- 还没有人留言评论。精彩留言会获得点赞!