基于Flink的知识图谱持续动态构建方法、装置及存储介质与流程
本技术涉及大数据,尤其涉及基于flink的知识图谱持续动态构建方法、装置及存储介质。
背景技术:
1、随着企业知识管理的不断深化和信息技术的飞速发展,知识图谱已经成为企业智能化管理和创新的核心工具。作为一种高度结构化的知识表示模型,知识图谱能够有效整合和关联企业内部的大量信息,为决策提供支持、促进团队协作、并推动创新发展。
2、然而,传统的知识图谱构建方法却存在一系列挑战。这些方法通常依赖于批量处理结构化和非结构化数据,导致在数据更新或新增时需要重新构建整个知识图谱,进而引发了重复的劳动和构建过程的延迟。这不仅浪费了大量时间和资源,还难以满足企业对知识图谱实时性的迫切需求。
3、在传统方法中,构建周期长、劳动繁琐,难以应对知识持续演进的业务需求。企业知识并非静止不变,而是不断发展和演化的,因此需要一种更灵活、高效、实时的构建方法来满足知识图谱持续演进的需求。这些问题共同限制了知识图谱在实际业务中的广泛应用,使得企业难以充分挖掘和利用自身的知识资产。
4、针对这些挑战和问题,本技术提出了一种基于flink的知识图谱持续构建方法。通过充分利用数据处理引擎的实时处理能力,以及提供各类连接器和函数,使得知识图谱的构建过程更加灵活、高效、并能够实现实时构建。这种创新性的解决方案不仅克服了传统方法中的种种不足,而且为企业知识图谱的应用效果提供了全新的可能性。通过持续演进的知识图谱,企业将更好地适应变化的业务环境,从而提升竞争力和推动创新发展。
技术实现思路
1、为了解决上述技术问题,本技术提供了基于flink的知识图谱持续动态构建方法、装置及存储介质,下面对本技术中的技术方案进行描述:
2、本技术第一方面提供了一种基于flink的知识图谱持续动态构建方法,所述方法包括:
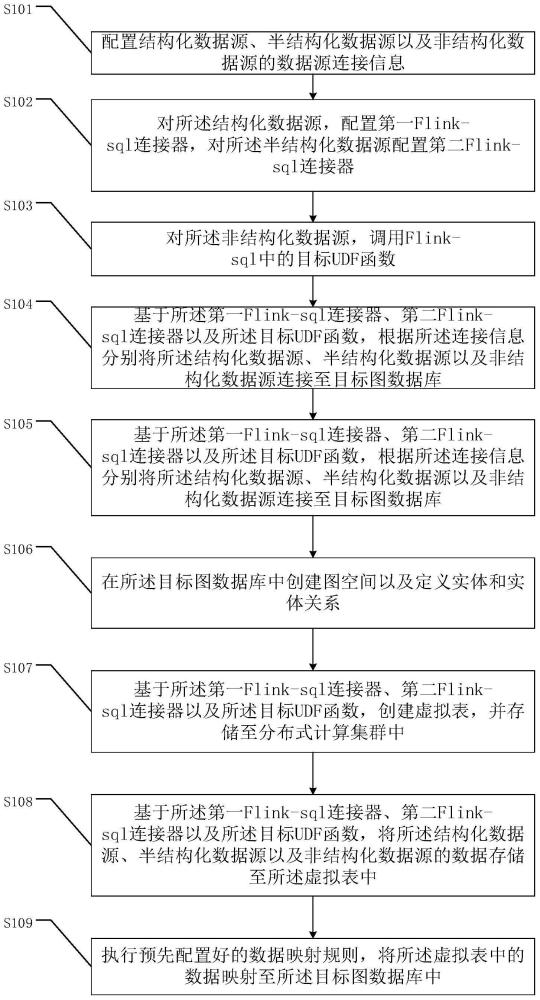
3、配置结构化数据源、半结构化数据源以及非结构化数据源的数据源连接信息;
4、对所述结构化数据源,配置第一flink-sql连接器,对所述半结构化数据源配置第二flink-sql连接器;
5、对所述非结构化数据源,调用flink-sql中的目标udf函数;
6、基于所述第一flink-sql连接器、第二flink-sql连接器以及所述目标udf函数,根据所述连接信息分别将所述结构化数据源、半结构化数据源以及非结构化数据源连接至目标图数据库;
7、在所述目标图数据库中创建图空间以及定义实体和实体关系;
8、基于所述第一flink-sql连接器、第二flink-sql连接器以及所述目标udf函数,创建虚拟表,并存储至分布式计算集群中;
9、基于所述第一flink-sql连接器、第二flink-sql连接器以及所述目标udf函数,将所述结构化数据源、半结构化数据源以及非结构化数据源的数据存储至所述虚拟表中;
10、执行预先配置好的数据映射规则,将所述虚拟表中的数据映射至所述目标图数据库中。
11、可选的,所述基于所述第一flink-sql连接器、第二flink-sql连接器以及所述目标udf函数,根据所述连接信息分别将所述结构化数据源、半结构化数据源以及非结构化数据源连接至目标图数据库包括:
12、在各个连接器中配置目标图数据库的图数据库连接信息;
13、根据所述目标图数据库连接信息,各个连接器通过flink的流处理引擎与图数据库建立连接;
14、通过flink的流处理引擎,将结构化数据源、半结构化数据源和非结构化数据源的数据流整合。
15、可选的,所述对所述非结构化数据源,调用flink-sql中的目标udf函数包括:
16、生成自定义udf函数;
17、在所述flink-sql注册所述自定义udf函数;
18、通过datastream api调用所述自定义udf函数。
19、可选的,所述基于所述第一flink-sql连接器、第二flink-sql连接器以及所述目标udf函数,创建虚拟表,并存储至分布式计算集群中包括:
20、对于结构化数据源,使用所述第一flink-sql连接器创建第一数据源表格;
21、对于半结构化数据源,使用所述第二flink-sql连接器创建第二数据源表格;
22、对于非结构化数据,基于所述目标udf函数注册第三数据源表格;
23、注册目标表格,所述目标表格用于存储目标图数据库的信息以及配置参数;
24、基于所述第一数据源表格、第二数据源表格以及第三数据源表格,使用createview语句注册虚拟表,并将所述虚拟表分区存储至分布式计算集群的各个目标节点中。
25、本技术第二方面提供了一种基于flink的知识图谱持续动态构建装置,包括:
26、数据源配置单元,用于配置结构化数据源、半结构化数据源以及非结构化数据源的数据源连接信息;
27、连接器配置单元,用于对所述结构化数据源,配置第一flink-sql连接器,对所述半结构化数据源配置第二flink-sql连接器;
28、函数配置单元,用于对所述非结构化数据源,调用flink-sql中的目标udf函数;
29、连接单元,用于基于所述第一flink-sql连接器、第二flink-sql连接器以及所述目标udf函数,根据所述连接信息分别将所述结构化数据源、半结构化数据源以及非结构化数据源连接至目标图数据库;
30、图空间定义单元,用于在所述目标图数据库中创建图空间以及定义实体和实体关系;
31、虚拟表创建单元,用于基于所述第一flink-sql连接器、第二flink-sql连接器以及所述目标udf函数,创建虚拟表,并存储至分布式计算集群中;
32、数据存储单元,用于基于所述第一flink-sql连接器、第二flink-sql连接器以及所述目标udf函数,将所述结构化数据源、半结构化数据源以及非结构化数据源的数据存储至所述虚拟表中;
33、数据映射单元,用于执行预先配置好的数据映射规则,将所述虚拟表中的数据映射至所述目标图数据库中。
34、本技术第三方面提供了一种基于flink的知识图谱持续动态构建装置,所述装置包括:
35、处理器、存储器、输入输出单元以及总线;
36、所述处理器与所述存储器、所述输入输出单元以及所述总线相连;
37、所述存储器保存有程序,所述处理器调用所述程序以执行第一方面以及第一方面中任一项可选的所述方法。
38、本技术第四方面提供了一种计算机可读存储介质,所述计算机可读存储介质上保存有程序,所述程序在计算机上执行时执行第一方面以及第一方面中任一项可选的所述方法。
39、从以上技术方案可以看出,本技术具有以下优点:
40、1、通过使用flink的流处理引擎,该方法能够实现知识图谱的实时构建。一旦企业的知识发生更新或新增,系统会无感知地将更新或新增的知识及时构建到知识图谱中,无需用户手动进行构建操作,保证了知识图谱的实时性。
41、2、提供了配置多种数据源的连接信息的能力,包括结构化数据源、半结构化数据源和非结构化数据源。通过配置flink-sql连接器和调用udf函数,实现了对不同类型数据源的适配,使得方法具有良好的灵活性和可扩展性。
42、3、通过将虚拟表存储至分布式计算集群中,使得方法能够充分利用大数据处理的优势,处理海量数据而不受性能影响,实现了对大规模知识图谱的构建和管理。
43、4、引入了各类flink-sql连接器,增强了图谱构建任务的可配置性。用户可以根据实际需求选择合适的连接器和配置参数,以适应不同的数据源和构建场景。
44、5、提供了flink-sql的udf函数,特别用于处理非结构化数据(文本、视频)。通过udf函数,能够在flink框架中对文本、视频类数据进行特征提取,将其转化为结构化数据,为知识图谱的构建提供了更多的数据来源。
45、通过监控知识是否更新或新增的状态,使得知识图谱的构建能够持续动态进行,避免了重复劳动和构建延迟,满足了企业知识持续演进的需求。
- 还没有人留言评论。精彩留言会获得点赞!