基于类别名称感知分解式框架的少样本命名实体识别方法与流程
本发明属于自然语言处理信息抽取领域。
背景技术:
1、随着互联网的快速发展,每天都有海量的非结构化文本产生。如何快速地从这些无序的文本信息中抽取出结构化的知识,帮助人类更高效地获取知识,成为近年来重要的研究热点。信息抽取技术就是为了解决这个问题。
2、命名实体识别(named entity recognition,简称ner)是信息抽取领域的一个重要的子任务。其任务目标是给定一段非结构文本,从句子中寻找、识别和分类相关实体,例如人物(person,简称per)、地点(location,简称loc)和机构名称(organization,简称org)。其要求既要正确识别出实体的跨度,也要正确分类实体的类别,是信息抽取领域重要和难点问题之一。
3、深度学习时代,大规模预训练语言模型的出现,使得ner技术得到了快速的发展。但是这些方法都需要大量的领域内的特定类别的人工标注数据,而标注数据耗费人力和时间。为了解决这个问题,近些年来少样本命名实体识别(few-shot named entityrecognition,简称few-shot ner)技术得到了广泛的关注和研究兴趣。few-shot ner希望能够仅用领域内的少量样本,即可取得令人满意的结果。
4、在few-shot ner中,我们希望模型首先在一个源域进行训练,接着模型利用目标域内的由少量支撑样本组成的支撑集进行域适应,最后再在目标域内进行测试。注意,源域和目标域中的实体类别无重叠部分。主要的方法主要分为两大类:基于提示(prompt-based)和基于度量(metric-based)的方法。其中基于度量的方法取得了更好且更稳定的效果,主要有原型网络(prototypical network)方法、对比学习(contrastive learning)方法等。其中,基于度量的分解框架取得了最佳的效果,其将ner拆分为实体跨度检测和实体类别分类两个阶段,在实体跨度检测阶段通过序列标注方法抽取出实体跨度,在实体类别分类阶段采用原型网络方法。由于其只需要单独学习实体跨度信息和实体类别信息,学习的难度大大降低,在面临少样本场景时更加有利。
5、但是现有的基于度量的分解框架方法还存在一定的缺陷。首先,在实体跨度检测阶段学到的是一个类别无关的模型,所以在目标域测试阶段,模型会抽取出一些错误的实体跨度,这些实体跨度可能是属于源域实体类别集合的实体,而不属于目标域实体类别集合,但是会被进一步分类到目标域任意的一个实体类别。其次,在实体类别分类阶段,现有方法往往通过极少量样本构造类别原型,缺乏类别语义的指导,在某些极坏场景下,所给的支撑样本距离真实类别中心过远,构造的原型可能会极不准确。原型构造的不稳定和不准确,直接导致了模型所取得的效果不佳。
技术实现思路
1、本发明旨在至少在一定程度上解决相关技术中的技术问题之一。
2、为此,本发明的目的在于提出一种基于类别名称感知分解式框架的少样本命名实体识别方法,用于解决实体跨度检测阶段的错误跨度和实体类别分类阶段的不稳定且不准确的原型问题。
3、为达上述目的,本发明第一方面实施例提出了一种基于类别名称感知分解式框架的少样本命名实体识别方法,包括:
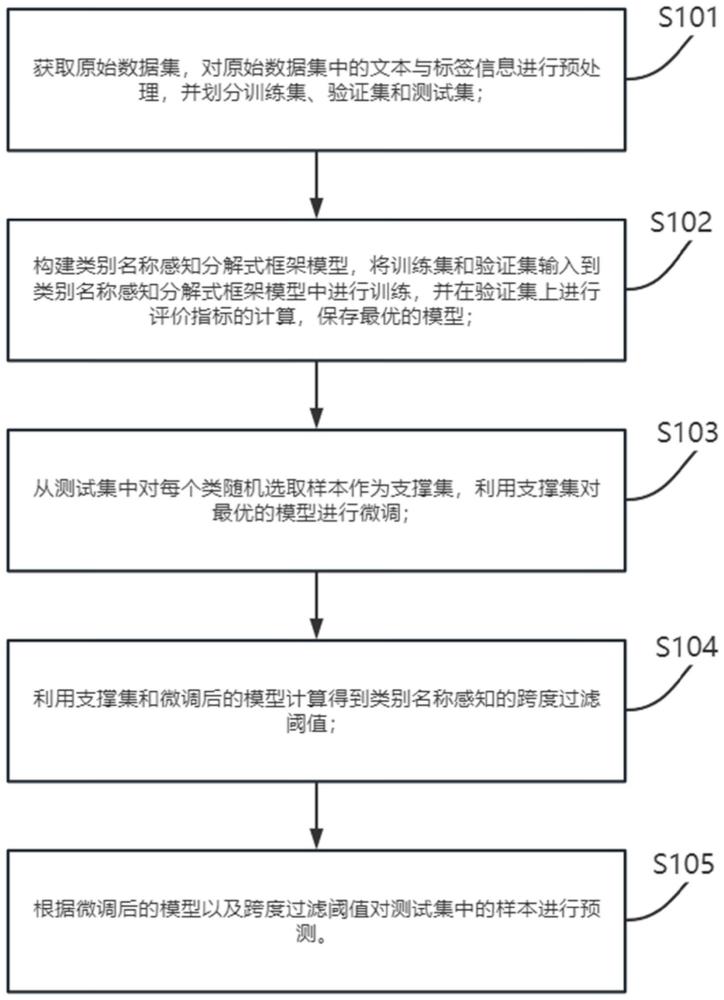
4、获取原始数据集,对所述原始数据集中的文本与标签信息进行预处理,并划分训练集、验证集和测试集;
5、构建类别名称感知分解式框架模型,将所述训练集和所述验证集输入到类别名称感知分解式框架模型中进行训练,并在验证集上进行评价指标的计算,保存最优的模型;
6、从所述测试集中对每个类随机选取样本作为支撑集,利用所述支撑集对所述最优的模型进行微调;
7、利用所述支撑集和微调后的模型计算得到类别名称感知的跨度过滤阈值;
8、根据微调后的模型以及所述跨度过滤阈值对测试集中的样本进行预测。
9、另外,根据本发明上述实施例的一种基于类别名称感知分解式框架的少样本命名实体识别方法还可以具有以下附加的技术特征:
10、进一步地,在本发明的一个实施例中,所述类别名称感知分解式框架模型,包括:
11、实体跨度检测模块和实体类别分类模块;其中,所述实体跨度检测模块由一个bert和一个分类层组成;所述实体类别分类模块由一个bert组成。
12、进一步地,在本发明的一个实施例中,所述将所述训练集和所述验证集输入到类别名称感知分解式框架模型中进行训练,包括:
13、训练实体跨度检测模块:
14、记输入的句子为x={x1,...,xn},将其经过预训练语言模型bert获得具有上下文表示的向量:
15、
16、其中,表示预训练语言模型bert,θ1表示bert的参数,h表示得到的上下文表示向量;
17、将h输入到一个线性分类层中来计算每个字是否属于实体词的概率分布,线性分类层包括一个dropout层和一个矩阵w,对于某个字xi按下面计算其是否属于实体词的概率分布:
18、p(xi)=softmax(dropout(w·hi+b)),
19、通过真实标签值和计算得到的概率分布计算实体跨度检测模块的损失函数值,如下:
20、
21、其中,记实体跨度检测模块的损失函数为lspan,yi为对应于xi的真实标签值,取值为0或1,0表示该字为非实体词的一部分,1表示该字为实体词的一部分;
22、在实体跨度检测模块训练过程中,通过更新参数{θ1,w,b}来减小lspan。
23、进一步地,在本发明的一个实施例中,所述将所述训练集和所述验证集输入到类别名称感知分解式框架模型中进行训练,还包括:
24、训练实体类别分类模块:
25、记输入样本中的实体字集合为对应的真实标签值为y={y1,...,ym},源域训练集中的实体类别集为γsource={t1,...,tm},将其中的类别标签转化为对应的类别名称集合γ'source=map(γsource)={t1',...,t'm},其中map()表示此转化过程;
26、按下面两种顺序将实体字上下文表示和对应的类别名称表示拼接起来:
27、
28、
29、其中,和分别表示按照实体-标签和标签-实体的顺序拼接得到的表示向量,map()用来将原始标签转化为对应的类别名称,为此处用到的bert;
30、通过所述表示向量进一步构造正负样本对,构造原则为:不同顺序的同一标签的作为正对,不同顺序的不同标签的作为负对;按下面的公式构造对比学习损失函数:
31、
32、zi={z|1≤z≤m,yz=yi},
33、
34、其中,m是此批次里实体字的总数目,zi是此批次内与实体字zi具有相同标签yi的实体字集合,sim()是归一化的相似度衡量函数,τ是温度系数,用于在训练时关注难样本对。
35、进一步地,在本发明的一个实施例中,所述从所述测试集中对每个类随机选取样本作为支撑集,利用所述支撑集对所述最优的模型进行微调,包括:
36、采用损失函数lspan和llabel对模型参数进行进一步更新;其中损失函数llabel表示为:
37、
38、
39、当损失值连续上升β时停止参数更新;
40、其中,当每个类仅给一个样本时,β取值为1,而每个类给五个样本时,β取值为6;实体跨度检测模块中的bert参数θ1更新后为θ1',实体类别分类模块中的bert参数θ2更新后为θ2'。
41、进一步地,在本发明的一个实施例中,所述利用所述支撑集和微调后的模型计算得到类别名称感知的跨度过滤阈值,包括:
42、通过下式计算类别名称感知的跨度过滤阈值:
43、
44、其中,和分别表示支撑集中的实体字以及其对应的标签。
45、进一步地,在本发明的一个实施例中,所述根据微调后的模型以及跨度过滤阈值对测试集中的样本进行预测,包括:
46、借助目标域实体类别名称集合和支撑集的少量样本,计算目标域测试集中的所有类别的原型表示:
47、
48、
49、其中,zj为支撑集中实体类别为tj的实体字集合,和分别表示支撑集中的实体字以及其对应的标签,构造的实体类别原型pj为类别名称感知的类别原型;
50、对每个候选实体跨度计算其与各个实体类别名称语义的最大相似度:
51、
52、其中si表示某一实体跨度;如果max_sim/2小于阈值γt,则认为此候选实体跨度应从候选集中删去,反之,则认为该实体跨度是正确检测出的,根据其在语义空间中与哪个实体类别原型更近来判断其所属实体类别,计算方式如下:
53、
54、
55、其中,ypred即为此实体跨度所属的实体类别,si连同ypred一起加入到最终预测结果集合中。
56、为达上述目的,本发明第二方面实施例提出了一种基于类别名称感知分解式框架的少样本命名实体识别装置,包括以下模块:
57、获取模块,用于获取原始数据集,对所述原始数据集中的文本与标签信息进行预处理,并划分训练集、验证集和测试集;
58、训练模块,用于构建类别名称感知分解式框架模型,将所述训练集和所述验证集输入到类别名称感知分解式框架模型中进行训练,并在验证集上进行评价指标的计算,保存最优的模型;
59、优化模块,用于从所述测试集中对每个类随机选取样本作为支撑集,利用所述支撑集对所述最优的模型进行微调;
60、计算模块,用于利用所述支撑集和微调后的模型计算得到类别名称感知的跨度过滤阈值;
61、预测模块,用于根据微调后的模型以及所述跨度过滤阈值对测试集中的样本进行预测。
62、为达上述目的,本发明第三方面实施例提出了一种计算机设备,其特征在于,包括存储器、处理器及存储在所述存储器上并可在所述处理器上运行的计算机程序,所述处理器执行所述计算机程序时,实现如上所述的一种基于类别名称感知分解式框架的少样本命名实体识别方法。
63、为达上述目的,本发明第四方面实施例提出了一种计算机可读存储介质,其上存储有计算机程序,其特征在于,所述计算机程序被处理器执行时实现如上所述的一种基于类别名称感知分解式框架的少样本命名实体识别方法。
64、本发明实施例提出的基于类别名称感知分解式框架的少样本命名实体识别方法,借助实体类别名称的语义指导过滤错误的实体跨度,并在实体类别分类阶段借助类别名称构造更稳定和更准确的原型。
65、与现有技术相比,本发明的优点与积极效果有:
66、1)本发明通过分解式框架的方法,将命名实体识别拆分为实体跨度检测和实体类别分类两个子任务,使得模型能够在少样本场景中更充分地分别学习实体跨度和实体类别信息。
67、2)本发明在实体类别分类子模块的训练阶段引入了类别名称感知的对比学习策略,使得模型学习到泛化性良好且与类别名称语义相关的特征空间,进而在少样本场景中,能够为每个新类构造更加稳定且准确的原型。
68、3)本发明提出了一个类别名称感知的实体跨度过滤策略,将实体跨度检测阶段检测出的错误实体跨度从实体跨度候选集中删去,以进一步提高模型在多种场景下的稳定性和有效性。
- 还没有人留言评论。精彩留言会获得点赞!