一种基于蜂群优化和孤立森林的电力数据清洗方法与流程
本发明涉及电力数据处理领域,尤其涉及一种基于蜂群优化和孤立森林的电力数据清洗方法。
背景技术:
1、随着智能电网的发展,先进测量装置被大规模应用在电力系统中,海量的电力数据被采集和存储。然而,由于各种各样的原因,电力数据在采集、传输和存储过程中出现了缺失、错误等异常情况,影响各种大数据技术的对数据价值的挖掘,降低了电网运营效率。在此背景之下,需要有效的数据清洗对电力数据进行异常检测和清洗,从而提高电力数据的价值,为人工智能等新兴数据应用技术清除应用障碍,这对提高电网运营效率、增加电力数据价值与保障电力数据分析业务的可靠性具有重要意义。
2、因此,上述技术问题亟待本领域技术人员解决。
技术实现思路
1、鉴于上述问题,本技术提供了一种基于蜂群优化和孤立森林的电力数据清洗方法,通过蜂群优化的孤立森林算法,对电力数据库中的异常数据进行清洗,有效提高电力运营效率和电力数据安全。
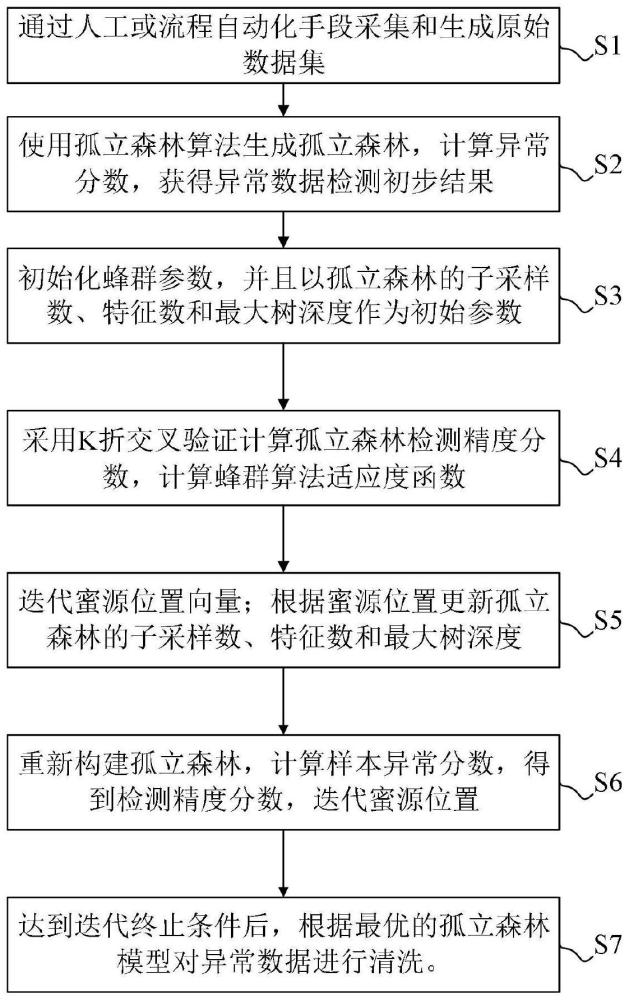
2、为实现上述目的,发明人提供了一种基于蜂群优化和孤立森林的电力数据清洗方法,该方法包括以下步骤:
3、步骤s1:通过人工或流程自动化手段采集和生成原始数据集;
4、步骤s2:使用孤立森林算法生成孤立树集合构成的孤立森林,计算异常分数,获得异常数据检测初步结果;
5、步骤s3:初始化蜂群参数,以孤立森林参数的子采样数、特征数和最大树深度作为蜂群算法可行解-蜜源的初始参数;
6、步骤s4:根据k折交叉验证计算孤立森林的检测精度分数,根据所述检测精度分数计算蜂群算法适应度函数;
7、步骤s5:根据蜂群算法迭代可行解-蜜源位置向量;根据可行解-蜜源位置更新孤立森林的子采样数、特征数和最大树深度;
8、步骤s6:根据蜂群算法重新构建孤立森林,重复步骤s2-s4,计算样本异常分数,得到检测精度分数,迭代可行解-蜜源位置;
9、步骤s7:达到蜂群算法迭代终止条件后,获得最优的孤立森林参数,根据最优孤立森林模型对异常数据进行清洗;
10、所述步骤s6具体包括以下步骤:
11、步骤s61:根据s5得到的孤立森林参数重新构建孤立森林,计算蜂群算法中的适应度函数;
12、步骤s62:根据新的适应度函数,重复步骤s5,执行s5中蜂群算法的三个模块;
13、步骤s63:判断是否满足蜂群算法的迭代终止条件,若满足跳转到步骤s7,否则重复步骤s61-s62;
14、所述步骤s7的迭代终止条件为迭代次数,数据清洗方式为移除异常值,并加入异常标记。
15、进一步的,所述步骤s1具体包括以下步骤:
16、步骤s11:采用rpa等流程化自动化处理软件或者人工采集的方法从电力数据库中汇总需要异常数据清洗的数据集,包括含有异常标识的历史记录数据与无异常表示的待检测数据;
17、步骤s12:根据步骤s11所述历史记录数据,编制带标签的机器学习数据集,从而传递给机器学习异常检测算法。
18、步骤s13:基于孤立森林算法,根据步骤s12所述带标签的机器学习数据集构建孤立森林,计算样本异常分数,获得异常数据检测的初步结结果
19、进一步的,所述步骤s2中的孤立森林算法具体包括以下步骤:
20、步骤s21:根据输入样本,从样本特征中随机选择一个特征,并随机选择一个分割值;
21、步骤s22:根据选定特征和分割值构建决策树,将数据集进行划分;
22、步骤s23:当达成以下三个条件之一:达到最大树深度、节点上只有一个样本和节点上所有样本具有相同的特征值;结束决策树的生成,得到孤立树itree;
23、步骤s24:重复步骤s21-s23,生成多个孤立树,得到孤立森林iforest;
24、步骤s25:根据孤立森林中样本的路径长度计算异常分数,得到异常检测结果。
25、进一步的,所述的孤立森林算法具体步骤s21,使用了随机子采样技术构建孤立森林的输入样本:
26、为了避免数据规模过大造成的样本划分困难,所述的孤立森林算法通过随机子采样技术降低孤立树生成难度;所述随机子采样技术具有两个输入:子样本数量参数φ,原始数据集;所述随机子采样技术通过计算机中的随机数生成器随机获得数据集索引列表,根据索引列表选择数据样本中的部分数据样本,用于机器学习算法训练。
27、进一步的,所述的孤立森林算法具体步骤s25,样本异常分数的计算基于样本路径长度和树平均路径长度定义:
28、所述样本路径长度h(x)被定义为孤立树itree中根节点到样本所在叶子节点的边个数;所述树平均路径长度的定义如下式所示:
29、
30、上式中n为样本数量,h(x)为调和数,c(n)为树的平均路径长度;所述样本异常分数基于下式计算:
31、
32、中,e(h(x))为样本x在多个孤立树中路径长度的期望;当样本的路径长度期望相对树的平均路径长度小很多时,所述异常分数s(x,n)将接近于1,此时样本被判定为异常数据;当样本路径长度远大于树平均路径长度,所述异常分数s(x,n)将接近0,此时样本被判定为正常数据。
33、进一步的,所述步骤s4具体包括以下步骤:
34、步骤s41:根据孤立森林算法对异常数据进行检测,根据如下公式计算异常数据的检测成功率tpr:
35、
36、步骤s42:根据k折交叉验证计算检测成功率的平均值,作为检测精度分数a。所述k折交叉验证的工作原理为:
37、将原始的数据级分成k组子集,将每个子集分别做一次验证集,其余作为训练集,构成k组验证集和训练集,对应得到k个模型,使用k个模型的验证集检测结果计算步骤s41的tpr并去平均值,作为检测精度分数a。
38、步骤s43:根据检测精度分数,根据下式计算蜂群算法适应度函数:
39、
40、式中,a为检测精度分数,σ为权重因子,fiti为蜂群算法中的可行解的适应度,所述蜂群算法可行解对应孤立森林模型的三个参数构成的向量。
41、进一步的,所述步骤s5-s6具体包括以下三个模块:
42、可行解的领域搜索模块;
43、可行解概率选择模块;
44、可行解随机搜索模块。
45、进一步的,所述的蜂群算法的可行解邻域搜索模块,进行可行解初始化和搜索更新,所述可行解初始化由下式得到:
46、xij=xmin,j+rand(0,1)(xmax,j-xmin,j)
47、式中,i对应可行解向量的索引,j为d维特征对应的索引值,对应孤立森林中的三个需要优化的参数:子采样数、特征数和最大树深度;xij为第i个可行解向量的第j个元素值;rand(0,1)为0-1间的随机数生成函数;xmin和xmax对应的是xi向量元素中的最小值和最大值;
48、所述可行解搜索更新可以根据下式产生:
49、
50、式中,j为d维特征对应的索引值,vij为更新得到的第i个可行解vi的第j个元素值,i不等于j;xij为第i个原可行解向量xi的第j个元素值;xkj为第k个原可行解向量的第j个元素值;为[-1,1]之间的随机值;计算所述新的可行解vi的适应度,并与原可行解xi适应度对比,选择适应度更优的解作为新可行解。
51、进一步的所述的蜂群算法的可行解概率搜索模块,根据适应度函数按如下式计算可行解更新概率:
52、
53、式中,pi为更新可行解的概率,fiti为第i个可行解的优化目标函数值,fi tj为第j个可行解的优化目标函数值,n为可行解总数;根据可行解更新概率,基于如下式的轮盘赌算法判断是否根据可行解领域搜索模块更新可行解:
54、
55、式中,当取值为1时代表更新,取值为0时代表不更新,rand(0,1)随机生成0-1之间的数字,pi为更新可行解的概率。
56、10.根据权利要求7所述的可行解随机搜索模块,其特征在于,基于如下公式搜索新的可行解:
57、
58、式中,i对应可行解向量的索引,d为特征对应的索引值;xid为第i个可行解向量的第d个元素值;rand(0,1)为0-1间的随机数生成函数;xmin,d和xmax,d对应的是xi向量元素中的最小值和最大值;只有当某个可行解经过可行解领域搜索和可行解概率搜索的次数超过控制参数limit,且适应度没有得到提高的情况下,该可行解将被放弃,根据上式重新生成可行解,以避免陷入局部最优解。
59、区别于现有技术,上述技术方案基于蜂群优化和孤立森林的电力数据清洗方法,该方法包括:通过人工或流程自动化手段采集数据集;使用孤立森林算法计算样本异常分数,异常数据检测结果;以孤立森林的子采样数、特征数和最大树深度作为蜂群算法初始蜜源的位置向量,以k折交叉验证计算蜂群算法的目标函数;根据蜂群算法迭代更新孤立森林三种参数;重新构建孤立森林,计算得到检测精度分数,迭代蜜源位置;达到迭代终止条件后,获得最优的孤立森林模型,清洗异常数据。本发明针对电力数据中的异常数据清洗问题,使用基于蜂群算法优化和孤立森林的电力数据清洗方法,能够准确识别电力数据中的异常数据,对电力企业运营具有重要的意义。
60、上述
技术实现要素:
相关记载仅是本技术技术方案的概述,为了让本领域普通技术人员能够更清楚地了解本技术的技术方案,进而可以依据说明书的文字及附图记载的内容予以实施,并且为了让本技术的上述目的及其它目的、特征和优点能够更易于理解,以下结合本技术的具体实施方式及附图进行说明。
- 还没有人留言评论。精彩留言会获得点赞!