6D姿态预测神经网络模型及方法与流程
本技术涉及机器视觉,特别涉及一种6d姿态预测神经网络模型及方法。
背景技术:
1、当前已经出现由弱人工智能向强人工智能转化的趋势,然而我们希望让护理机器人拥有面向强人工智能的行为能力,能够全天候提供病人的床旁护理服务,除了能够与病人进行会话交流外,还能够自主帮助患者起居、康复训练、用餐、取药换药等工作。而要护理机器人实现上述功能,就得让护理机器人知道目标物体的空间相对坐标以及目标物体的移动方向。护理机器人通过深度照相机获取动态目标的图像数据,其内置的神经网络算法会根据实时抓拍的图像数据,完成目标物体的空间相对坐标及移动方向的预测。上述神经网络技术被称为6d姿态预测技术,在机器视觉领域应用较广。除了机器人外,汽车的无人驾驶系统、无人机察打一体系统以及巡飞弹自主巡航系统也在广泛应用6d姿态预测技术。
2、6d就是物体的六个自由度,其中三个自由度为物体图像坐标映射到相机坐标的转换矩阵,它是用来帮助机器人确定物体的空间位置参数;另外三个自由度为对象在空间中的三维旋转角,它是用来帮助机器人确定对象的动态转动参数。hong等使用multi-taskcascaded convolutional networks (mtcnn)完成rgb图像的2d目标检测,并基于得到的对象边界框计算出转换矩阵;另外,他们使用q-net算法完成对象旋转角(四元数)的回归预测。然而mtcnn是针对人脸识别开发的神经网络算法,该算法使用滑动窗口及非极大值抑制等方法确定的最佳边界框的方式适用于小图像,对于包含更多对象的大尺寸图像耗时较为严重。另外,通过矩形框划定物体区域作为目标检测的标签,已训练的mtcnn将会把最佳的矩形区域作为该对象,但不规则对象外轮廓并非矩形,这将导致不规则对象质心与该矩形质心偏差较大,影响旋转角的预测准确度。
3、因此,现有技术存在缺陷,有待改进与发展。
技术实现思路
1、本技术实施例提供一种6d姿态预测神经网络模型及方法,能够提高对象3d转换矩阵预测的准确性和对象旋转角回归预测的准确性,从而提高护理机器人的行为能力。
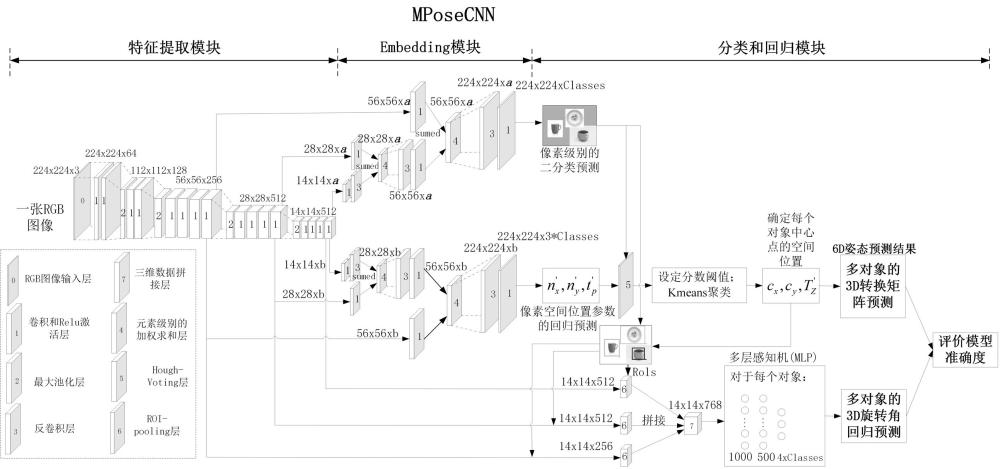
2、本技术实施例提供一种6d姿态预测神经网络模型,包括特征提取模块、embedding模块以及分类和回归模块;
3、所述特征提取模块用于通过预训练的vgg19的前16个卷积层或vgg16的前13个卷积层提取rgb-d图像中不同尺寸的3d特征图;
4、所述embedding模块用于对不同尺寸的所述3d特征图进行卷积、反卷积和加权求和操作,生成用于多对象分类预测的第一特征图集合和用于多对象中心坐标回归预测的第二特征图集合;
5、所述分类和回归模块用于对所述第一特征图集合进行处理,以获取每一对象的像素级别的二分类预测结果,以及对所述第二特征图集合进行处理,以获取每一所述对象的像素空间位置参数的回归预测结果,并将所述像素级别的二分类预测结果和所述像素空间位置参数的回归预测结果输入至hough-voting层,通过所述hough-voting层确定每一对象的中心点空间位置以及深度,以计算出每一所述对象的3d转换矩阵,完成多对象的3d转换矩阵的预测;
6、所述分类和回归模块还用于基于每一所述对象的所述像素级别的二分类预测结果和所述对象的所述中心点空间位置确定出每一所述对象的矩形边界框,并通过roipooling层从所述vgg19或vgg16的三个预设卷积层中剪裁出第三特征图集、第四特征图集和第五特征图集,以及将所述第三特征图集、第四特征图集和第五特征图集输入至具有预设神经元个数的多层感知机中,通过所述多层感知机确定每一所述对象的3d旋转角,以完成多对象的3d旋转角的回归预测。
7、在本技术实施例所述的6d姿态预测神经网络模型中,所述embedding模块用于对不同尺寸的所述3d特征图进行卷积、反卷积和加权求和操作,生成用于多对象分类预测的第一特征图集合和用于多对象中心坐标回归预测的第二特征图集合,包括:
8、所述embedding模块用于对所述vgg19的第16个所述卷积层或vgg16的第13个所述卷积层中的所述3d特征图进行卷积和反卷积操作,得到第一操作结果,并将所述第一操作结果与所述vgg19的第12个所述卷积层或vgg16的第10个所述卷积层中的所述3d特征图执行卷积操作后得到的结果进行加权求和操作,得到第二操作结果,以及将所述第二操作结果进行反卷积和卷积操作,得到第三操作结果,将所述第三操作结果与所述vgg19的第8个所述卷积层或vgg16的第7个所述卷积层中的所述3d特征图执行卷积操作后得到的结果进行加权求和、反卷积和卷积操作,生成所述用于多对象分类预测的第一特征图集合;
9、所述embedding模块还用于对所述vgg19的第16个所述卷积层获取vgg16的第13卷积层中的所述3d特征图执行卷积和反卷积操作,得到第四操作结果,并将所述第四操作结果与所述vgg19的第12个所述卷积层或vgg16的第10个所述卷积层中的所述3d特征图执行卷积操作后得到的结果进行加权求和操作,得到第五操作结果,以及将所述第五操作结果进行反卷积和卷积操作,得到第六操作结果,将所述第六操作结果与所述vgg19的第8个所述卷积层或vgg16的第7个所述卷积层中的所述3d特征图执行卷积后的结果进行加权求和、反卷积和卷积操作,生成所述用于多对象中心坐标回归预测的第二特征图集合。
10、在本技术实施例所述的6d姿态预测神经网络模型中,所述将所述第三操作结果与所述vgg19的第8个所述卷积层或vgg16的第7个所述卷积层中的所述3d特征图执行卷积操作后得到的结果进行加权求和、反卷积和卷积操作,生成所述用于多对象分类预测的第一特征图集合,包括:
11、将所述第三操作结果与所述vgg19的第8个所述卷积层或vgg16的第7个所述卷积层中的所述3d特征图执行卷积操作后得到的结果进行加权求和操作,将所述加权求和操作得到的结果进行反卷积操作,将所述反卷积操作得到的结果进行卷积操作,得到所述用于多对象分类预测的第一特征图集合。
12、在本技术实施例所述的6d姿态预测神经网络模型中,所述通过所述hough-voting层确定每一对象的中心点空间位置以及深度,以计算出每一所述对象的3d转换矩阵,完成多对象的3d转换矩阵的预测,包括:
13、通过所述hough-voting层生成每一像素点作为对象候选中心点时的像素点分值,得到所有像素点的所述像素点分值,并将所有所述像素点分值按分值从大到小的顺序排列,使用kmeans聚类方法将像素点分值大于或等于预设像素点分数阈值的像素点进行聚类操作,以确定每一对象的中心点空间位置以及深度,根据相机坐标与图像坐标的映射关系,计算出每个对象的3d转换矩阵,完成多对象的3d转换矩阵的预测。
14、在本技术实施例所述的6d姿态预测神经网络模型中,所述并通过roi pooling层从所述vgg19或vgg16的三个预设卷积层中剪裁出第三特征图集、第四特征图集和第五特征图集,包括:
15、通过roi pooling层按照所述矩形边界框在原图像中的位置及比例从所述vgg19的第16个所述卷积层或vgg16的第13个所述卷积层中的所述3d特征图中剪裁出所述第三特征图集,从所述vgg19的第12个所述卷积层或vgg16的第10个所述卷积层中的所述3d特征图中剪裁出所述第四特征图集,以及从所述vgg19的第8个所述卷积层或vgg16的第7个所述卷积层中的所述3d特征图中剪裁出所述第五特征图集。
16、本技术实施例还提供一种护理机器人的6d姿态预测神经网络模型,包括多个以上任一实施例所述的6d姿态预测神经网络模型,部分所述6d姿态预测神经网络模型通过预训练的vgg19的前16个卷积层提取rgb-d图像中不同尺寸的3d特征图,余下部分所述6d姿态预测神经网络模型通过预训练的vgg16的前13个卷积层提取所述rgb-d图像中不同尺寸的3d特征图。
17、本技术实施例还提供一种6d姿态预测方法,用于以上任一实施例所述的6d姿态预测神经网络模型,所述方法包括:
18、通过预训练的vgg19的前16个卷积层或vgg16的前13个卷积层提取rgb-d图像中不同尺寸的3d特征图;
19、对不同尺寸的所述3d特征图进行卷积、反卷积和加权求和操作,生成用于多对象分类预测的第一特征图集合和用于多对象中心坐标回归预测的第二特征图集合;
20、对所述第一特征图集合进行处理,以获取每一对象的像素级别的二分类预测结果,以及对所述第二特征图集合进行处理,以获取每一所述对象的像素空间位置参数的回归预测结果;
21、将所述像素级别的二分类预测结果和所述像素空间位置参数的回归预测结果输入至hough-voting层,通过所述hough-voting层确定每一对象的中心点空间位置以及深度,以计算出每一所述对象的3d转换矩阵,完成多对象的3d转换矩阵的预测;
22、基于每一所述对象的所述像素级别的二分类预测结果和所述对象的所述中心点空间位置确定出每一所述对象的矩形边界框,并通过roi pooling层从所述vgg19或vgg16的三个预设卷积层中剪裁出第三特征图集、第四特征图集和第五特征图集;
23、将所述第三特征图集、第四特征图集和第五特征图集输入至具有预设神经元个数的多层感知机中,通过所述多层感知机确定每一所述对象的3d旋转角,以完成多对象的3d旋转角的回归预测。
24、在本技术实施例所述的6d姿态预测方法中,所述对不同尺寸的所述3d特征图进行卷积、反卷积和加权求和操作,生成用于多对象分类预测的第一特征图集合和用于多对象中心坐标回归预测的第二特征图集合,包括:
25、对所述vgg19的第16个所述卷积层或vgg16的第13个所述卷积层的所述3d特征图进行卷积和反卷积操作,得到第一操作结果;
26、将所述第一操作结果与所述vgg19的第12个所述卷积层或vgg16的第10个所述卷积层的所述3d特征图执行卷积操作后得到的结果进行加权求和操作,得到第二操作结果;
27、将所述第二操作结果进行反卷积和卷积操作,得到第三操作结果,将所述第三操作结果与所述vgg19的第8个所述卷积层或vgg16的第7个所述卷积层中的所述3d特征图执行卷积操作后得到的结果进行加权求和、反卷积和卷积操作,生成所述用于多对象分类预测的第一特征图集合;
28、对所述vgg19的第16个所述卷积层获取vgg16的第13卷积层执行卷积和反卷积操作,得到第四操作结果;
29、将所述第四操作结果与所述vgg19的第12个所述卷积层或vgg16的第10个所述卷积层中的所述3d特征图执行卷积操作后得到的结果进行加权求和操作,得到第五操作结果;
30、将所述第五操作结果进行反卷积和卷积操作,得到第六操作结果,将所述第六操作结果与所述vgg19的第8个所述卷积层或vgg16的第7个所述卷积层执行卷积后的结果进行加权求和、反卷积和卷积操作,生成所述用于多对象中心坐标回归预测的第二特征图集合。
31、在本技术实施例所述的6d姿态预测方法中,所述通过所述hough-voting层确定每一对象的中心点空间位置以及深度,以计算出每一所述对象的3d转换矩阵,完成多对象的3d转换矩阵的预测,包括:
32、通过所述hough-voting层生成每一像素点作为对象候选中心点时的像素点分值,得到所有像素点的所述像素点分值;
33、将所有所述像素点分值按分值从大到小的顺序排列,使用kmeans聚类方法将像素点分值大于或等于预设像素点分数阈值的像素点进行聚类操作,以确定每一对象的中心点空间位置以及深度;
34、根据相机坐标与图像坐标的映射关系,计算出每个对象的3d转换矩阵,完成多对象的3d转换矩阵的预测。
35、在本技术实施例所述的6d姿态预测方法中,所述并通过roi pooling层从所述vgg19或vgg16的三个预设卷积层中剪裁出第三特征图集、第四特征图集和第五特征图集,包括:
36、通过roi pooling层按照所述矩形边界框在原图像中的位置及比例从所述vgg19的第16个所述卷积层或vgg16的第13个所述卷积层中的所述3d特征图中剪裁出所述第三特征图集;
37、通过roi pooling层按照所述矩形边界框在原图像中的位置及比例从所述vgg19的第12个所述卷积层或vgg16的第10个所述卷积层中的所述3d特征图中剪裁出所述第四特征图集;
38、通过roi pooling层按照所述矩形边界框在原图像中的位置及比例从所述vgg19的第8个所述卷积层或vgg16的第7个所述卷积层中的所述3d特征图中剪裁出所述第五特征图集。
39、本技术实施例提供的6d姿态预测神经网络模型,包括特征提取模块、embedding模块以及分类和回归模块,特征提取模块通过vgg19的前16个卷积层或vgg16的前13个卷积层提取rgb-d图像中不同尺寸的3d特征图,embedding模块对不同尺寸的3d特征图进行卷积、反卷积和加权求和操作,生成用于多对象分类预测的第一特征图集合和用于多对象中心坐标回归预测的第二特征图集合,分类和回归模块对第一特征图集合进行处理,以获取每一对象的像素级别的二分类预测结果,以及对第二特征图集合进行处理,以获取每一对象的像素空间位置参数的回归预测结果,并将像素级别的二分类预测结果和像素空间位置参数的回归预测结果输入至hough-voting层,通过hough-voting层确定每一对象的中心点空间位置以及深度,以计算出每一对象的3d转换矩阵,完成多对象的3d转换矩阵的预测;分类和回归模块基于每一对象的像素级别的二分类预测结果和对象的中心点空间位置确定出每一对象的矩形边界框,并通过roi pooling层从vgg19或vgg16的三个预设卷积层中剪裁出第三特征图集、第四特征图集和第五特征图集,以及将第三特征图集、第四特征图集和第五特征图集输入至具有预设神经元个数的多层感知机中,通过多层感知机确定每一对象的3d旋转角,以完成多对象的3d旋转角的回归预测,从而本技术实施例的6d姿态预测神经网络模型能够提高对象3d转换矩阵预测的准确性和对象旋转角回归预测的准确性,从而提高护理机器人的行为能力。
- 还没有人留言评论。精彩留言会获得点赞!