一种基于多核神经网络处理器的算法加速方法与流程
本发明属于人工智能领域,尤其涉及一种多核神经网络处理器的算法加速方法。
背景技术:
1、近年来,深度学习已成为最为火热的研究领域。神经网络处理器被用于支持神经网络的执行和计算,因为其自身独特的硬件结构和其数据驱动并行计算的架构,使得在神经网络计算时性能和功耗上有较大的优势。随着神经网络的不断发展和各种复杂的应用场景提出,单核神经网络处理器已经很难满足要求,而多核神经网络处理器通过使用多个核心并行处理推理任务能够大大提升性能,减少推理时间。
2、但是,在实际处理神经网络推理任务时,由于没有采用合适的分配调度方法导致多核神经网络处理器的资源利用率低,并不能发挥出多核神经网络处理器的全部性能。
技术实现思路
1、为了解决背景技术中存在的技术问题,本发明提供了一种基于多核神经网络处理器的算法加速方法。本发明以神经网络处理器底层硬件为核心,通过研究算法及算子在神经网络处理器中进行计算时的操作,对神经网络算法在多核神经网络处理器中的计算任务进行分配。提高了神经网络处理器的性能。
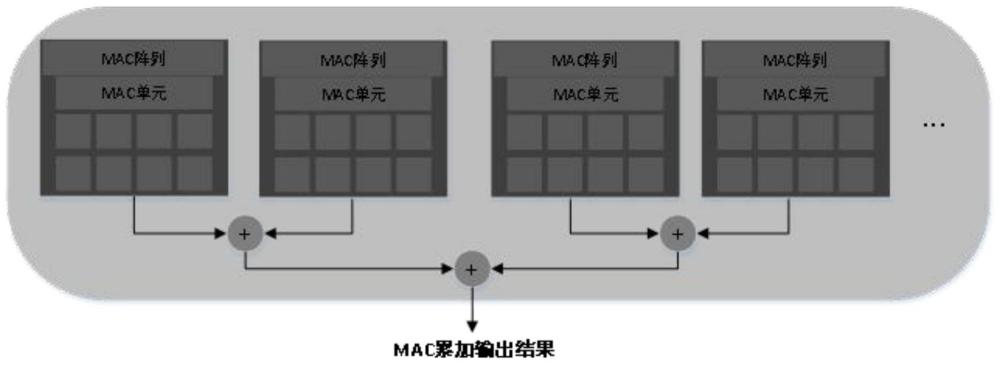
2、本发明的技术解决方案是:本发明为一种基于多核神经网络处理器的算法加速方法,其特殊之处在于:该方法包括以下步骤:
3、1)确定处理器单核心mac单元的计算架构,以及核心数量n(n为>1的任意正整数),并对所有核心编号;
4、2)确定神经网络处理器单个核心对所支持的张量算子的执行行为;
5、3)根据步骤2)中所得张量算子的执行行为分析是否可以2个核以上并行加速执行,设定2个到n个核心加速时的计算任务分配规则,并确定该算子多个核加速后的结果合并规则;
6、4)对待加速的算法,需配置执行加速任务的核心数量m(m>1的任意正整数,m<=n),以及主核编号,并启动算法加速任务。
7、进一步的,步骤1)中确定单核心mac单元计算架构包括确定神经网络处理器中的mac阵列数量和每组mac阵列中的mac单元数量。
8、进一步的,步骤2)中确定神经网络处理器单个核心对所支持的张量算子的执行行为是确定神经网络处理器支持的张量算子的计算方式和其在处理器中的执行方式。
9、进一步的,步骤3)中确定计算任务分配规则是根据算法分配计算任务,具体包括:
10、a)根据神经网络算法输入大小分配计算任务;其分配方式为根据c通道数对计算任务分割,分配给选定用来加速的核心计算单元;计算完成后,由主核按合并规则对计算结果汇总,并分配下一次计算任务;
11、b)根据卷积核个数分配计算任务;其分配方式为根据卷积核个数对计算任务分割,分配给选定用来加速的核心计算单元。计算完成后,由主核按合并规则汇总计算结果,将结果作为输入,根据下一层的卷积核数量再分配给各个核心加速计算;
12、c)根据神经网络单层计算量分配计算任务,其分配方式为将输入数据分割为与核心数相同的特征图,将其送入选定用来加速的核心进行计算,共同完成一层算子运行,计算完成后由主核按合并规则汇总计算结果形成新的特征图,同理再分割并进行分配。
13、进一步的,步骤a)中根据神经网络算法输入大小分配计算任务具体为:神经网络算法输入大小通常由c,h,w组成(其中c表示输入通道数,h表示输入高度,w表示输入宽度),处理器核心数为n,通过c分配计算任务时,则每个处理器核心计算输入为(c/n)*h*w大小的数据,同理,也可通过h和w进行任务分配,每个处理器核心计算输入为(h/n)*c*w和(w/n)*c*h大小的数据。
14、进一步的,步骤b)根据卷积核个数分配计算任务具体为:神经网络中卷积操作计算量较大,可根据卷积核个数分配计算任务,卷积核个数为k,大小为kh*kw,核心数为n,则每个核心在单个卷积层的计算量为c*h*w*kh*kw*(k/n)。
15、进一步的,步骤c)根据神经网络单层计算量分配计算任务具体为:一个核心中的所有mac单元无法一次执行某个算子的全部计算任务时,可根据神经网络单层计算量分配,每个核心输入数据量为(c*h*w)/n,可将一层计算任务分配到多个核心中并行计算。
16、进一步的,步骤3)中确定该算子多个核加速后的结果合并规则,合并规则应遵循多核加速后的计算结果与单核计算结果的数据存储方式保持一致。
17、进一步的,步骤4)中配置加速任务的核心数量和主核编号是通过算法加速任务配置所需的核心数量,确定一个核为主核,并启动算法加速。
18、本发明的优点是:本发明提供的基于多核神经网络处理器的算法加速方法,通过算法输入大小,卷积核个数和单层计算量对计算任务进行合理分配,多个核心并行计算,有效提高了神经网络处理器的性能。
技术特征:
1.一种基于多核神经网络处理器的算法加速方法,其特征在于:该方法包括以下步骤:
2.根据权利要求1所述的基于多核神经网络处理器的算法加速方法,其特征在于:所述步骤1)中确定单核心mac单元计算架构包括确定神经网络处理器中的mac阵列数量和每组mac阵列中的mac单元数量。
3.根据权利要求2所述的基于多核神经网络处理器的算法加速方法,其特征在于:所述步骤2)中确定神经网络处理器单个核心对所支持的张量算子的执行行为是确定神经网络处理器支持的张量算子的计算方式和其在处理器中的执行方式。
4.根据权利要求3所述的基于多核神经网络处理器的算法加速方法,其特征在于:所述步骤3)中确定计算任务分配规则是根据算法分配计算任务,具体包括:
5.根据权利要求4所述的基于多核神经网络处理器的算法加速方法,其特征在于:所述步骤a)中根据神经网络算法输入大小分配计算任务具体为:神经网络算法输入大小通常由c,h,w组成(其中c表示输入通道数,h表示输入高度,w表示输入宽度),处理器核心数为n,通过c分配计算任务时,则每个处理器核心计算输入为(c/n)*h*w大小的数据,同理,也可通过h和w进行任务分配,每个处理器核心计算输入为(h/n)*c*w和(w/n)*c*h大小的数据。
6.根据权利要求5所述的基于多核神经网络处理器的算法加速方法,其特征在于:所述步骤b)根据卷积核个数分配计算任务具体为:神经网络中卷积操作计算量较大,可根据卷积核个数分配计算任务,卷积核个数为k,大小为kh*kw,核心数为n,则每个核心在单个卷积层的计算量为c*h*w*kh*kw*(k/n)。
7.根据权利要求6所述的基于多核神经网络处理器的算法加速方法,其特征在于:所述步骤c)根据神经网络单层计算量分配计算任务具体为:一个核心中的所有mac单元无法一次执行某个算子的全部计算任务时,可根据神经网络单层计算量分配,每个核心输入数据量为(c*h*w)/n,可将一层计算任务分配到多个核心中并行计算。
8.根据权利要求7所述的基于多核神经网络处理器的算法加速方法,其特征在于:所述步骤3)中确定该算子多个核加速后的结果合并规则,合并规则应遵循多核加速后的计算结果与单核计算结果的数据存储方式保持一致。
9.根据权利要求8所述的基于多核神经网络处理器的算法加速方法,其特征在于:所述步骤4)中配置加速任务的核心数量和主核编号是通过算法加速任务配置所需的核心数量,确定一个核为主核,并启动算法加速。
技术总结
本发明涉及一种基于多核神经网络处理器的算法加速方法,本发明包括以下步骤:1)确定处理器单核心MAC单元的计算架构,以及核心数量N(N为>1的任意正整数),并对所有核心编号;2)确定神经网络处理器单个核心对所支持的张量算子的执行行为;3)根据步骤2)中所得张量算子的执行行为分析是否可以2个核以上并行加速执行,设定2个到N个核心加速时的计算任务分配规则,并确定该算子多个核加速后的结果合并规则;4)对待加速的算法,需配置执行加速任务的核心数量M(M>1的任意正整数,M<=N),以及主核编号,并启动算法加速任务。本发明以神经网络处理器底层硬件为核心,通过研究算法及算子在神经网络处理器中进行计算时的操作,对神经网络算法在多核神经网络处理器中的计算任务进行分配。提高了神经网络处理器的性能。
技术研发人员:田泽,马城城,秦翔,孙成璐,罗进杰,胡亚
受保护的技术使用者:西安翔腾微电子科技有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!