一种基于SBM-Net模型的视网膜血管图像分割方法
本发明属于计算机技术语义分割,特别涉及一种基于sbm-net模型的视网膜血管图像分割方法。
背景技术:
1、视网膜图像中的血管是指在眼底图像或视网膜成像中可见的血管网络。视网膜是位于眼球内部的感光层,负责接收和传递光信号到大脑,以产生视觉感知。在视网膜图像中,血管呈现为细长的线状结构,分为动脉和静脉。动脉通常呈现为较亮的颜色,比静脉细而明亮,直径较小。而静脉则较粗,颜色较暗。血管网络呈现出分支、交叉和网状结构,可以提供关于视网膜健康状况的重要信息。视网膜血管的形态和分布对于评估眼部健康和诊断一些疾病非常重要。医生可以通过观察视网膜血管的变化来检测和监测眼部疾病,如糖尿病视网膜病变、青光眼、视网膜血管阻塞等。
2、随着人工智能技术在医学领域的研究发展,采用传统的图像分割方法对医学图像进行分割,进而大幅度提高了医疗诊断正确率,提高了医疗诊断水平。视网膜血管图像与传统医学图像不同,视网膜血管图中血管细而密集,有多个分支、交叉,分为动脉和静脉。动脉通常呈现为较亮的颜色,比静脉细而明亮,直径较小。而静脉则较粗,颜色较暗。容易导致模型过拟合,分割效果差。传统的图像分割模型难以对细而杂繁的血管提取关键特征,无法很好的分割眼部血管图像。
技术实现思路
1、发明目的:针对以上出现的问题,本发明提供了一种基于sbm-net模型的视网膜血管图像分割方法,通过构建的isb模块和swin transformer block模块、mce模块进行下采样编码,通过构建mse模块进行上采样解码,通过训练得到最终的sbm-net模型,进而提高语义分割的精度。
2、技术方案:本发明提出一种基于sbm-net模型的视网膜血管图像分割方法,包括以下步骤:
3、s1:构建眼部数字视网膜血管的图像数据集;
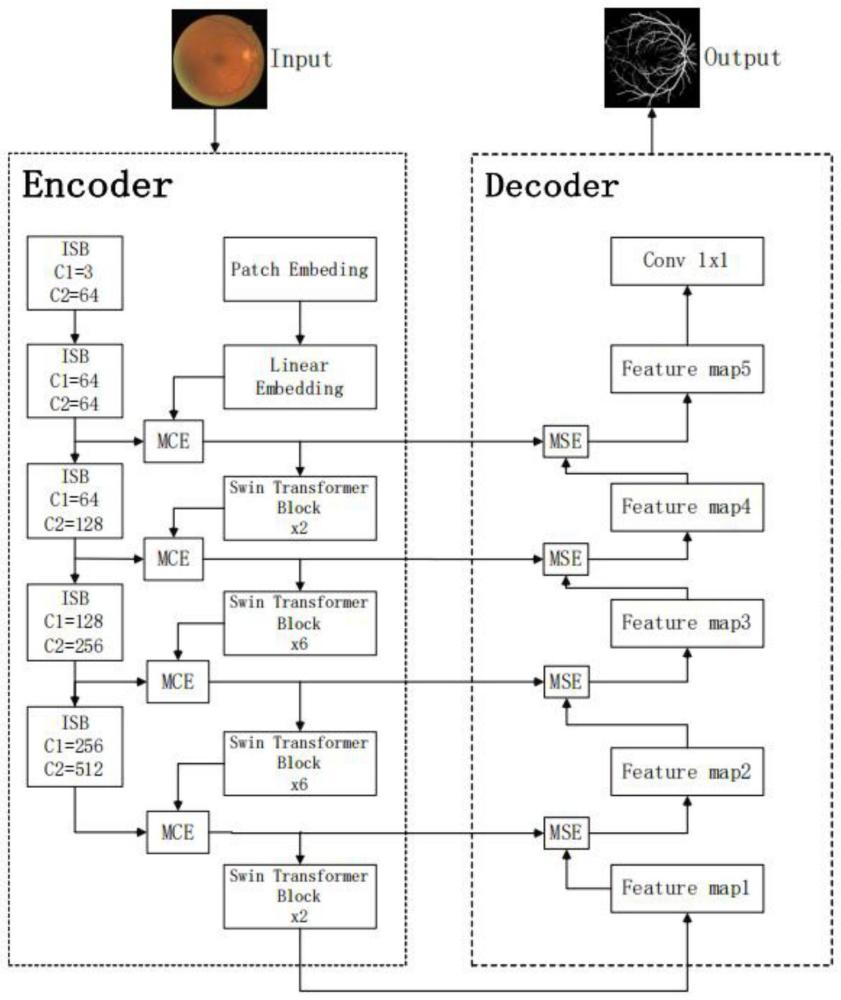
4、s2:构建基于sbm-net模型的视网膜血管图像分割模型,所述视网膜血管图像分割模型包括编码器和解码器两部分,编码器部分包括局部特征提取模块和全局特征提取模块以及将局部特征和全局特征进行融合的mce模块;所述局部特征提取模块包括依次连接的5个isb模块;全局特征提取模块包括一个patch embedding模块、linear embedding模块,以及4个swin transformer block模块;所述解码器部分包括4个mse模块、5个feature map,以及一个conv 1x1像素级分类器;
5、s3:利用s2所述的视网膜血管图像分割模型对眼部数字视网膜血管的图像进行图像分割。
6、进一步地,所述isb模块为在inverted residual block模型上加入注意力scse。
7、进一步地,所述编码器部分的具体执行过程如下:
8、将图像特征输入到提取局部特征模块,依次经过5个isb模块来提取局部特征;然后,将图像特征输入到提取全局特征模块,经过patch embedding将特征图转换为固定大小的向量,然后通过linear embedding来逐步恢复图像细节,将linear embedding输出特征与第二个isb模块输出的特征通过第一个mce模块进行融合后作为第一个swintransformer block模块的输入;
9、第三个isb模块输出的特征与第一个swin transformer block模块输出的特征经过第二个mce模块进行融合后作为第二个swin transformer block模块的输入;
10、第四个isb模块输出的特征与第二个swin transformer block模块输出的特征经过第三个mce模块进行融合后作为第三个swin transformer block模块的输入;
11、第五个isb模块输出的特征与第三个swin transformer block模块输出的特征经过第四个mce模块进行融合后作为第四个swin transformer block模块的输入;
12、第四个swin transformer block模块的输出特征作为编码器的输入特征featuremap。
13、进一步地,所述解码器部分具体执行过程如下:
14、第四个swin transformer block模块的输出特征作为编码器的输入特征featuremap1,然后将其输入到mse模块中,4个mce模块的输出特征输入到对应的4个mse模块,每个mse模块之间通过输出特征feature map连接。
15、进一步地,所述isb模型的具体方结构为:
16、s2.1:构建包含1×1conv2d,batchnorm2d,h-wish激活函数的通道压缩的模块;
17、s2.2:构建包含n×nconv2d,batchnorm2d,h-wish实现通道可分离的分组卷积模块;
18、s2.3:构建包含1×1conv2d,batchnorm2d的卷积聚合特征的模块;
19、s2.4:构建跳跃连接的残差模块,将原始输入的特征,与经过上述3步的特征进行残差连接;
20、s2.5:构建spatial squeeze模块,包括用于减小通道数,实现空间压缩的1×1conv2d;以及将空间注意力的权重限制在0到1之间的激活函数sigmoid;
21、s2.6:构建channel excitation模块,包括自适应平均池化层,用于压缩通道信息的adaptiveavgpool2d;用于减小通道数的1×1conv2d;用于引入非线性的激活函数relu;用于还原通道数的1×1conv2d;用于将通道注意力的权重限制在0到1之间的激活函数sigmoid;
22、s2.7:将spatial squeeze模块的输出特征和channel excitation模块的输出特征沿着通道维度相加的方式拼接,得到最终信息校正的scse模型;
23、s2.8:将构建好的scse通过跳跃连接加入到inverted residual block,实现isb模型的构建。
24、进一步地,所述mce模块的具体方结构为:
25、s3.1:构造注意力eca模块;
26、s3.2:将isb模块输出的特征与swin transformer block模块输出的特征相加拼接与eca组合构造出mce模块。
27、进一步地,所述mse模块的具体结构为:
28、s4.1:构建具有upsample、doubleconv的上采样模块;
29、s4.2:构造注意力scse模块;
30、s4.3:构造将下采样的特征与上采样的特征进行concat拼接,将拼接后的特征加入注意力scse组合构造出mse模块。
31、进一步地,所述s1的具体方法为:
32、s1.1:采集并保存眼部数字视网膜血管的图像数据,对数据采用labelme工具进行人工标注并制作成数据集;
33、s1.2:对眼部数字视网膜血管的图像数据集进行预处理,将原数据集通过数据增强来提高数据质量,提高模型的泛化性和鲁棒性;
34、s1.3:将制作完成的数据集按照一定比例划分为训练集和测试集。
35、有益效果:
36、1、本发明编码阶段采用isb模块提取局部特征,采用swin transformer block模块提取全局特征,通过mce模块将isb模块提取局部特征与swin transformer block模块提取的全局信息充分融合。这样有助于充分提取到数据特征,同时也可以通过mce中注意力eca自适应地调整通道特征图的权重,提高特征图的表达能力,有助于提升模型的分割性能和泛化能力。
37、2、本发明采用的isb模块是由inverted residual block和注意力scse结合,注意力scse有效地学习特征图的空间相关性和通道相关性,并通过调整特征图的权重来提取有用的信息。isb模块通过整合不同的层数和不同卷积核大小的特征,可以捕捉到更多有用的语义信息,从而提高了模型的准确性和鲁棒性。inverted residual block是一种轻量级深度学习模型的模块,用于增强特征表示和减少模型的计算复杂性。它在深度方向上进行特征扩展和压缩,以提高模型的表达能力和效率。inverted residual block减少了计算的参数量,这样可以提高运行速率。
38、3、本发明解码阶段采用的mse模块采用的是concat方式对不同特征进行融合,通过注意力scse能够有效地学习特征图的空间相关性和通道相关性,并通过调整特征图的权重来提取有用的信息,提高解码阶段的特征图的表达能力,提高分割性能。
- 还没有人留言评论。精彩留言会获得点赞!