基于多尺度信息交互网络的文本-图像行人重识别方法
本发明属于计算机视觉,具体涉及一种基于多尺度信息交互网络的文本-图像行人重识别方法。
背景技术:
1、文本-图像行人重识别是智能视频监控中的一项任务,用于在多个相机中查询目标行人。传统方法忽略了无法获取行人图像的复杂或特殊场景,如偏远道路或遮挡情况。为解决此问题,可利用目击者提供的语言描述进行搜索,即文本-图像行人重识别。该方法通过比较查询文本与图像的相似度,对大型图像库中的人物图像进行排序,并选择排名靠前的图像作为匹配项。由于使用文本描述作为查询更简单自然,文本-图像行人重识别具有广阔的应用前景。文本-图像行人重识别是一项具有挑战性的任务。在处理过程中,图像可能存在遮挡、背景杂波和姿态干扰等问题,而文本描述的任意顺序和歧义性会增加特征对齐的不确定性。近些年,人们主要使用两种方法来缩小图文之间的模态差距:全局匹配方法和局部匹配方法。全局匹配方法既无法充分挖掘图像中的局部细节,又缺乏中间层的充分跨模态交互。局部匹配方法复杂度高,极有可能会破坏图像和文本的上下文信息或者引入噪声,进而影响图像和文本特征的对齐结果,同时又因为需要较大的计算量,局部匹配方法中的信息交互不可避免地会降低推理效率,难以在实际应用中实现。
技术实现思路
1、本发明是为了解决上述现有技术存在的不足之处,提出一种基于多尺度信息交互网络的文本-图像行人重识别方法,以期能挖掘细粒度的有效匹配信息,以缩小模态之间的差距,从而提高文本-图像行人重识别的准确率。
2、本发明为达到上述发明目的,采用如下技术方案:
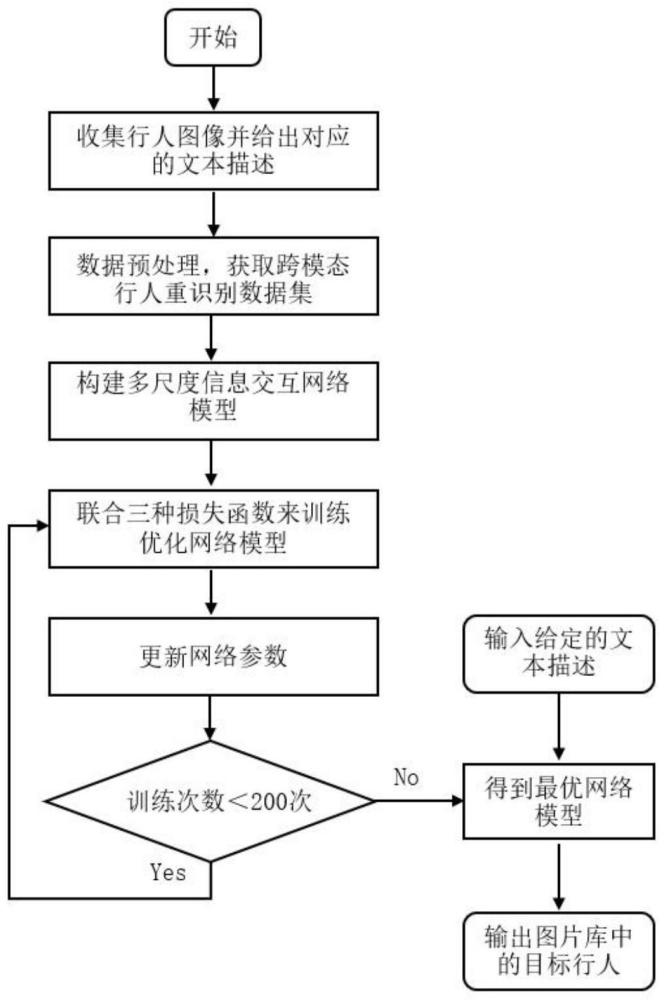
3、本发明一种基于多尺度信息交互网络的文本-图像行人重识别方法的特点在于,包括以下步骤:
4、步骤1、收集成对的文本描述和行人图像并进行统一的预处理,获取跨模态行人重识别数据集;
5、步骤1.1、用不同规格的相机分别采集处于不同的场景、视点下的若干个行人图像,得到行人图像数据集i={i1,i2,...,in,...,in},其中,in表示第n张行人图像,n为行人图像数据集i中行人图像的总数;
6、步骤1.2、生成行人图像数据集i中行人图像对应的文本描述,从而得到文本数据集t={t1,t2,...,tn,...,tn};其中,tn表示第n张行人图像in对应的文本描述;
7、步骤2、构建多尺度信息交互网络包括:双路径图像-文本特征提取网络,基于注意力的隐式多尺度特征更新网络,基于多元注意力交互机制的跨模态特征联合网络;
8、步骤2.1、所述双路径图像-文本特征提取网络使用vit图像编码器从in中提取初级特征,得到视觉特征vn={vn,g,vn,1,vn,2,...,vn,k,...,vn,k},并使用transformer文本编码器从tn中提取初级特征,得到文本特征tn={tn,g,tn,1,tn,2,...,tn,l,...,tn,l},其中,vn,g是in的全局视觉特征,vn,k是in中第k个补丁的局部特征,tn,g是tn的全局文本特征,tn,l是tn的第l个文本局部特征;k表示网格状补丁的数量,l表示文本特征的固定长度,当文本特征的长度大于l时,选择前l个单词;当文本特征的长度小于l时,在文本特征的末尾进行零填充;
9、步骤2.2、所述基于注意力的隐式多尺度特征更新网络由前景增强判别器模块、随机语言掩码模块和语义一致特征金字塔网络构成;
10、步骤2.2.1、所述前景增强判别器模块对vn进行处理,得到增强后的映射特征
11、步骤2.2.2、随机语言掩码模块以δ%的概率用掩码符号“[mask]”对tn进行随机屏蔽,得到文本映射特征其中,δ表示阈值;
12、步骤2.2.3、所述语义一致特征金字塔网络使用卷积对进行降采样后,得到2r层不同尺度的特征图;接着将相邻两个尺度的特征图中的高分辨率特征图进行降采样处理,得到的降采样后的高分辨率特征图再与另一个尺度的低分辨率特征图进行交叉融合,得到r个经过交叉融合的特征图;随后对r个特征图进行相同处理,将高分辨率特征图进行降采样处理后,与对应的低分辨率特征图进行两两交叉融合,最终得到一个包含丰富的局部和全局信息的图像特征
13、步骤2.3、基于多元交互注意力机制的跨模态特征联合网络使用受多样性损失约束的多头注意模块、交叉注意力模块对和进行处理,得到图像表示和文本表示以实现图像-文本对齐;
14、步骤3、采用联合跨模态投影匹配损失lcmpm、身份损失lnd(fnv)和多样性损失ldiv来构建总的损失函数ltotal,并基于i和t,使用adam优化策略对多尺度信息交互网络进行训练,直至总的损失函数ltotal收敛为止,得到最优多尺度信息交互模型,用于对输入的待检测的文本进行图像匹配,并输出对应的目标行人图像。
15、本发明所述的基于多尺度信息交互网络的文本-图像行人重识别方法的特点也在于,所述前景增强判别器模块由空间引导定位模块和通道去噪模块组成;
16、所述空间引导定位模块对vn分别进行最大池化和平均池化操作,并将两个操作的结果串联后,再通过一个卷积层和sigmoid激活函数的处理,从而得到空间权重系数an,sgl;再将vn与an,sgl进行逐元素相乘,得到增强后的映射特征
17、所述通道去噪模块对依次进行全局最大池化和全局平均池化操作后,再将得到的特征向量分别送入共享的两层神经网络中进行处理,将得到的两个结果相加后,再经过一个sigm oid激活函数的处理,得到通道权重系数an,cdm;最后将与an,cdm进行逐元素相乘后,得到增强后的映射特征
18、所述步骤2.3包括:
19、步骤2.3.1、所述多头注意模块利用patch embedding操作将转换成一维序列矩阵并利用式(1)所示的线性投影计算,得到m个注意力头中第m个注意力头的图像查询向量图像键向量和图像值向量
20、
21、式(1)中,表示第m个注意力头的待训练的3个参数矩阵,d表示掩码令牌的嵌入维度;
22、步骤2.3.2、所述多头注意模块利用linear操作将转换成一维序列矩阵并利用式(1)得到m个注意力头中第m个注意力头的文本查询向量文本键向量和文本值向量
23、步骤2.3.3、所述交叉注意力模块利用式(2)获取m个注意力头中第m个注意力头的图像注意力图和文本注意力图
24、
25、式(2)中,dk表示向量的维度;t表示转置;
26、所述交叉注意力模块利用式(3)分别得到m个注意力头的图像注意力图和文本注意力图
27、
28、式(3)中,cat表示拼接;
29、步骤2.3.4、所述交叉注意力模块利用transformer的前馈网络对和进行处理,得到最终的图像表示和文本表示
30、所述步骤3中的总的损失函数ltotal是按如下步骤得到:
31、步骤3.1、利用式(4)构建从图像到文本的跨模态投影匹配损失
32、
33、式(4)中,fit表示第i张行人图像ii对应的文本描述ti经过多尺度信息交互网络后得到的最终的文本表示;pn,i表示和fit为匹配对的预测概率,ε是一个参数,qn,i表示和fit为匹配对的真实概率;yn,i是和fit为匹配对的真实匹配标签;表示fit经过标准化后的文本特征;表示将投影到上;
34、步骤3.2、利用式(4)构建从文本到图像的跨模态投影匹配损失从而将与相加得到跨模态投影匹配损失lcmpm;
35、步骤3.3、利用式(5)构建身份损失lnd(fnv);
36、lnd(fnv)=-log(softmax(wnd×gn(fnv))) (5)
37、式(5)中,gn(fnv)表示对fnv进行全局归一化后的结果,wnd表示第n个行人的权重向量;
38、步骤3.4、利用式(6)构建多样性损失ldiv;
39、
40、步骤3.4、利用式(7)构建总的损失函数ltotal;
41、ltotal=lcmpm+ldiv+lid (7)。
42、本发明一种电子设备,包括存储器以及处理器的特点在于,所述存储器用于存储支持处理器执行所述文本-图像行人重识别方法的程序,所述处理器被配置为用于执行所述存储器中存储的程序。
43、本发明一种计算机可读存储介质,计算机可读存储介质上存储有计算机程序的特点在于,所述计算机程序被处理器运行时执行所述文本-图像行人重识别方法的步骤。
44、与现有技术相比,本发明的有益效果在于:
45、1、本发明在使用基于注意力的隐式多尺度特征更新网络对初级图像和文本特征进行处理,去除图像中多余的背景和环境信息,增加了文本特征的多样性,并且自适应地调整不同尺度特征图之间的权重,将图像中的细节与整体特征有效融合,显著提升了图像和文本表示的表达能力。
46、2、本发明设计了一种多元交互注意力机制,能够有效地捕捉到不同视觉特征和文本信息之间的交互关系,使用文本特征辅助优化视觉特征,促进视觉特征学习到更多与文本特征互补的细节信息,缩小了模态间差距,从而实现了隐式多尺度对齐。
47、3、本发明联合跨模态投影匹配损失、身份损失和多样性损失,优化训练文本-图像行人重识别模型,拉近匹配的图像和文本表示之间距离,并使不同尺度的特征聚焦于不一样的信息,实现了基于语义中心的隐式多尺度对齐。
- 还没有人留言评论。精彩留言会获得点赞!