一种基于AI的智能对话管理系统及方法与流程
本发明涉及智能客服,更具体地说,它涉及一种基于ai的智能对话管理系统及方法。
背景技术:
1、现有的智能客服通常是通过人工配置应答模板或者自动化构建知识图谱的方式来回答用户问题。
2、人工配置应答模板的方式是通过提取用户问题的关键词与应答模板的索引关键词进行相似度计算,将相似度最大的应答模板返回给用户;自动化构建知识图谱的方式是通过提取智能客服的历史对话数据,以历史的用户问题和客服回答作为知识图谱的实体或者通过提取用户问题和客服回答中的关键词作为知识图谱的实体,存在于同一会话或者同一对话轮次的实体之间存在连接关系,最后将当前的用户问题与知识图谱的用户问题进行相似度匹配作为客服回答。
3、然而无论是人工配置应答模板还是自动化构建知识图谱的过程中可能都存在异常情况,例如:人工配置应答模板时恶意填写不合法或者敏感词汇;自动化构建知识图谱时可能存在错误或者歧义的问答组合或者用户问题不存在对应的客服回答等异常情况。
4、现有的智能客服通过人工校验和设置校验规则可以快速检测应答模板是否存在异常,然而知识图谱数据量庞大、复杂度较高,单一的人工校验耗时耗力,单一的设置校验规则缺乏语义理解,导致对知识图谱的异常情况的检测精度较低,从而导致智能客服回答不准确,用户满意度下降。
技术实现思路
1、本发明提供一种基于ai的智能对话管理系统,解决相关技术中通过人工校验知识图谱耗时耗力和通过设置校验规则校验知识图谱缺乏语义理解,导致对知识图谱的异常情况的检测精度较低,智能客服回答不准确的技术问题。
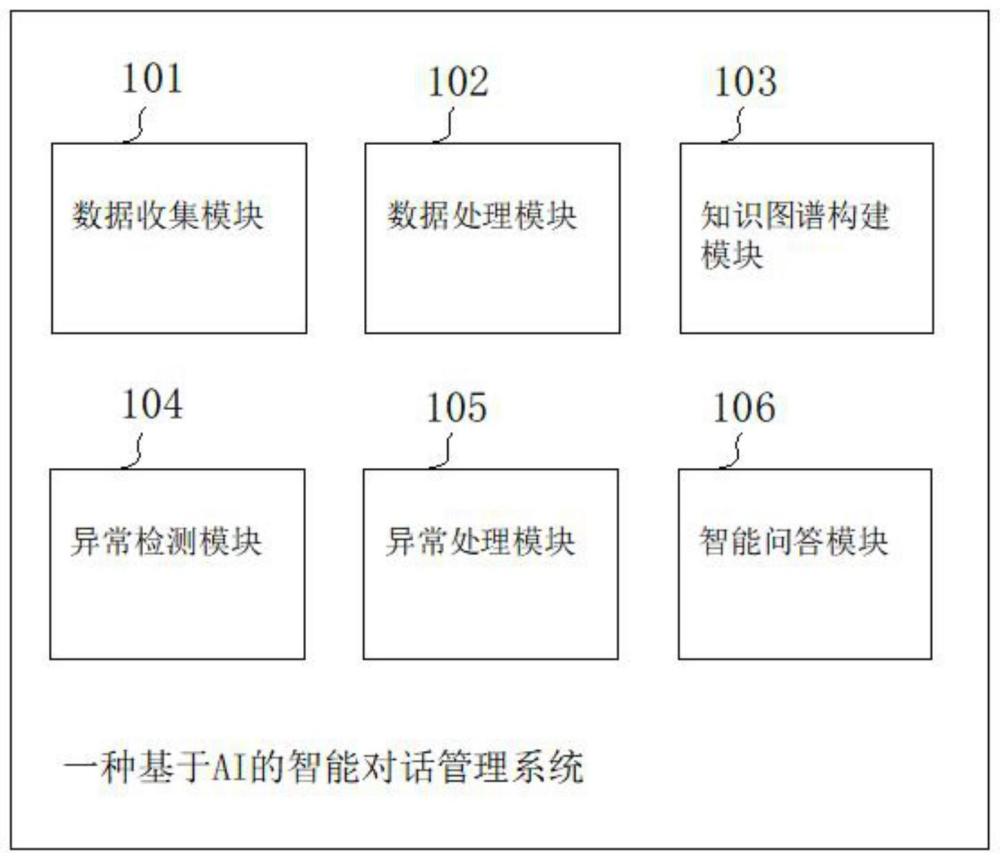
2、本发明提供了一种基于ai的智能对话管理系统,包括:
3、数据收集模块,其用于收集智能客服的历史对话数据;
4、历史对话数据包括:用户问题数据和客服应答数据;
5、数据处理模块,其用于对历史对话数据进行数据处理获得备用数据;
6、知识图谱构建模块,其用于基于备用数据构建第一知识图谱;
7、第一知识图谱包括:实体、实体的属性值和实体的连接关系;
8、每个实体都分配有一个唯一的标识符;
9、实体的类型包括:文本类型、数值类型和布尔类型;
10、实体和实体的属性值通过提取备用数据生成;
11、实体的连接关系表示实体之间存在边;
12、异常检测模块,其用于将第一知识图谱输入异常检测模型,输出第一邻接矩阵;异常检测模型包括:第一隐藏层和第二隐藏层;
13、第一隐藏层输入第一知识图谱,输出第一矩阵;第一矩阵的行向量表示一个实体的更新属性值;
14、第二隐藏层输入第一矩阵,输出第一邻接矩阵;第一邻接矩阵的第i行的第j列的元素值表示第一知识图谱的第i个实体和第j个实体之间是否存在边,如果存在边则第一邻接矩阵的第i行的第j列的元素值赋值为1,否则赋值为0;
15、异常处理模块,其用于根据第一邻接矩阵和第一知识图谱进行异常处理获得第二知识图谱;第二知识图谱和第一知识图谱的表示相同;
16、智能问答模块,其用于将第二知识图谱存储在图数据库中,根据当前用户输入的问题文本通过图数据库提供的查询工具检索获得对应的实体返回给用户。
17、进一步地,对历史对话数据进行数据处理获得备用数据包括以下步骤:
18、步骤s301,文本预处理;通过自然语言处理工具去除历史对话数据中的特殊字符、标点符号和停用词;
19、步骤s302,敏感词处理;通过构建敏感词库识别历史对话数据中的敏感词,并将该敏感词直接删除作为脱敏处理,敏感词库中的敏感词汇通过人工添加设置;
20、步骤s303,去除存在缺失值的数据;当历史对话数据中的一条数据存在缺失值则直接去除该条数据;
21、步骤s304,文本纠错处理;通过文本纠错工具对历史对话数据进行文本纠错获得备用数据。
22、进一步地,实体的类型为文本类型的属性值通过词向量模型编码生成;实体的类型为数值类型的属性值通过实数编码表示;实体的类型为布尔类型的属性值通过整数编码表示。
23、进一步地,实体和实体的属性值根据智能客服的业务决定。
24、进一步地,知识图谱的构建包括以下步骤:
25、步骤s401,分词处理;通过中文分词工具将备用数据进行分词;
26、步骤s402,词性标注处理;通过词性标注工具对分词后的备用数据进行词性标注;
27、步骤s403,实体识别;通过实体识别工具对词性标注后的备用数据进行实体识别获得命名实体;
28、步骤s404,实体链接;将备用数据中的命名实体与知识图谱中的实体建立链接;
29、步骤s405,抽取实体的连接关系;通过抽取实体连接关系工具构建实体之间的边。
30、进一步地,第一隐藏层的计算公式包括:
31、第一矩阵p的计算公式如下:其中表示第u个实体的更新属性值,pilem表示将m个实体的更新属性值进行堆叠操作,m表示第一知识图谱的实体的总数量的值;
32、第u个实体的更新属性值的计算公式如下:
33、其中nu表示第u个实体的邻居实体的集合,第u个实体的邻居实体表示与第u个实体存在边的实体,hv表示第v个邻居实体的属性值,αuv表示第u个实体与第v个邻居实体之间的归一化注意力系数,w表示权重参数,sigmoid表示sigmoid激活函数;
34、第u个实体与第v个邻居实体之间的归一化注意力分数αuv的计算公式如下:
35、其中nu表示第u个实体的邻居实体的集合,hu、hv和hx分别表示第u个实体的属性值、第v个邻居实体的属性值和第x个邻居实体的属性值,β表示注意力权重参数,w表示权重参数,||表示拼接操作,t表示转置操作,exp表示取自然指数函数的幂运算,leakyrelu表示leakyrelu激活函数。
36、进一步地,第二隐藏层的计算公式如下:
37、q=sigmoid(p*pt),其中q表示第一邻接矩阵,p表示第一矩阵,t表示转置操作,sigmoid表示sigmoid激活函数,第一矩阵的元素值大于等于0.5则赋值为1,否则赋值为0。
38、进一步地,用于训练异常检测模型的训练数据集中的训练样本对应的样本知识图谱和第二知识图谱的表示相同,即样本知识图谱不存在异常情况,异常检测模型在训练的过程中,通过学习实体之间的关联信息,并更新第一知识图谱以逼近样本知识图谱,第一知识图谱对应的第一邻接矩阵和样本知识图谱对应的样本邻接矩阵之间的差作为损失函数,用于反向传播更新异常检测模型的权重参数。
39、进一步地,提取第一邻接矩阵中元素值为0的实体,并将对应的第一知识图谱的实体删除获得第二知识图谱。
40、一种基于ai的智能对话管理方法,用于执行上述的一种实时客服云端数据管理系统,包括以下步骤:
41、步骤s501,收集智能客服的历史对话数据;
42、步骤s502,对历史对话数据进行数据处理获得备用数据;
43、步骤s503,基于备用数据构建第一知识图谱;
44、步骤s504,将第一知识图谱输入异常检测模型,输出第一邻接矩阵;
45、步骤s505,根据第一邻接矩阵和第一知识图谱进行异常处理获得第二知识图谱;
46、步骤s506,将第二知识图谱存储在图数据库中,根据当前用户输入的问题文本通过图数据库提供的查询工具检索获得对应的实体返回给用户。
47、本发明的有益效果在于:本发明通过神经网络模型综合考虑了知识图谱的实体的关联关系,实体的连接关系的关联程度通过归一化注意力系数表示,通过对知识图谱的信息融合来提高知识图谱的异常情况的检测精度。
- 还没有人留言评论。精彩留言会获得点赞!